
当我们开始构建 Vela 时,有一个非常具体、甚至有点执拗的目标:新的 Postgres 环境应该快到让人感觉不到自己在“做预置”。 我们的意思不是“对于一台 VM 来说已经很快了”,而是真正尽可能地快。快到平台工程师会把它称为即时交付,同时又必须具备完整隔离。
也就是说,我们当时有三个硬约束:
- 数据库之间必须完全隔离,是硬边界,而不是所谓“namespace 级隔离”。
- 必须真正抗 noisy neighbor,对 CPU、RAM 和磁盘活动都要有硬性资源限制。
- 必须具备 Kubernetes 原生扩展性,支持自动放置以及不中断的替换(live migration)。
Vela 最初的目标听起来简单直接,但真正做起来却难得令人抓狂。Vela 中的每一个数据库(branch)都要拥有强隔离,并且能够动态、独立地扩展。它应该像人们期待的那样,在 Kubernetes 上表现为一个数据库,但同时又要拥有虚拟机级别的隔离保证。
这篇文章讲述了我们如何从那个起点走到 10 秒内启动,同时仍然保留数据库之间的完整隔离,以及在 Kubernetes 内部自然工作的扩展行为。一路上,我们学到了很多东西:KubeVirt 的模型及其锋利边缘、为什么 VM 自动扩缩容和 pod 自动扩缩容存在微妙但重要的差异,以及为什么一个小到极致的自定义 OS 镜像,可能比几乎任何调优参数都更能撬动性能。
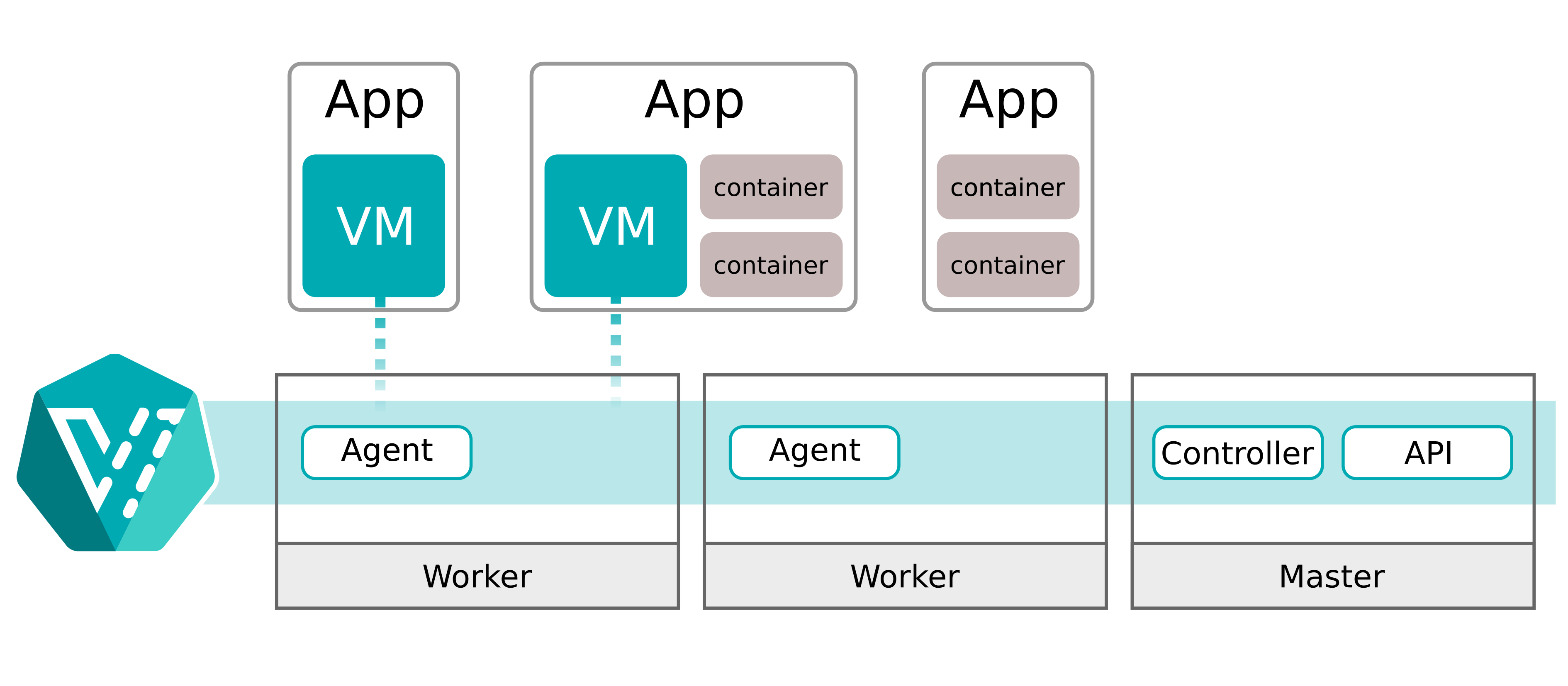
为什么我们选择虚拟机
一开始我们选择 VM,出于一个很务实的原因:VM 的 live migration 是一个已经被解决的问题。大多数 hypervisor 都支持它,而且在成熟度上,它仍明显领先于容器级的 live migration。我们当然也看过一些容器迁移方案(例如 zeropod),但它们不符合我们的约束。它们在扩缩容上做得不错,甚至能平滑地缩到零,但达不到我们要求的“不中断 live migration”。
Kubernetes 也是不可谈判的前提。对大多数平台团队来说,Kubernetes 就是“底层基座”,其他一切都应该整合进它的调度、可观测性和运维生命周期。
于是我们做了显而易见的选择:把 Postgres 运行在 VM 里,但这些 VM 依然由 Kubernetes 对象来控制。KubeVirt 正是为此而设计的:它把 VM 类型扩展进 Kubernetes API,并通过一个启动 QEMU/KVM 的 pod 来运行 VM 的“载荷”。
第一次尝试:KubeVirt、Docker,以及令人沮丧的启动时间
在 Kubernetes 上跑虚拟机?那不就是 KubeVirt 吗。和很多人一样,我们当时也是这么回答的。能有多难呢?
我们的第一版实现,状态好的时候大约 2 分钟,状态差的时候最多要 5 分钟。已经够“即时”了,对吧? 🫣
单看 VM 本身的启动时间,其实并不算特别糟糕。问题在于,启动 VM 只是开始。我们在 VM 里面先启动 Docker(Compose),然后为每个 branch 拉取并加载多个容器镜像,实际上就是每个 branch 所需的全部服务:Postgres、PGBouncer、PostgREST 等。Docker Hub 的限流以及“镜像拉取抽奖”很快就成了尾部延迟的残酷来源。
启动路径大致是这样的:
- Kubernetes 创建 KubeVirt VM 资源
- VM 资源启动 QEMU
- 来宾操作系统启动
- Docker 服务变为可用
- Docker 下载各个容器镜像
- Docker 按照依赖图逐个启动容器
- 容器启动并进入 healthy 状态
- 我们把 branch 标记为 active(healthy)
我们知道每次 VM 启动都重新下载镜像并不理想,但没想到会糟糕到这种程度。核心问题在于 Docker 处理镜像下载和容器启动的方式。它基本上会先把所有镜像都下完,然后再按依赖关系顺序启动。只要遇到一个很大的镜像,或者一个因为限流而特别慢的镜像,这次启动就被拖垮了。镜像越多,撞上“坏日子”的概率就越高。
最终,我们识别出了三个会放大延迟的部分,按影响从高到低排序如下:
- 为了让 branch 服务镜像可用而进行的 image pull 和 registry throttling
- 由 VM 和其内 Docker 容器构成的双层启动路径
- 额外的设置步骤,例如注册 DNS 名称、置备新磁盘、运行 Postgres 的 initdb 等等
给 Docker 镜像做预缓存
首先,我们必须消灭“每次都重新下载”这个问题。如果你的启动路径里包含“下载依赖”,那你拥有的就不是启动时间,而是一个概率分布。
既然我们本来就在构建一个 VM 镜像,那为什么不“顺手”在构建过程中把所有需要的容器镜像都预先下载下来呢?
说干就干。我们调整了构建流程,加入一个步骤:把所需的 Docker 镜像全部下载好,并打包进最终的虚拟机启动镜像。
这一步效果非常明显。最大的启动时间波动来源被消除了。我们获得了相当稳定的 90 到 100 秒基线。尽管如此,我们仍然花了不少时间在启动 Linux 镜像本身,以及等待 Docker 服务可用上,然后才能真正拉起 branch 服务。作为第一次尝试,这已经足够好了。但我们也知道,进一步优化的空间不在于继续启动一个典型 Linux 镜像,而在于重新审视整个启动过程。
为什么要用 Docker?
一直悬而未决的一个问题是:“你们为什么偏偏要在 VM 里面用 Docker?”
简短的回答只有一个词:方便。
更长的回答是:它让我们可以通过不同的 Docker 镜像和不同的候选服务(例如 Pgpool-II、PGBouncer 等)快速试验,从而缩短迭代周期。
我们需要在不重建虚拟机的前提下进行实验,而当时 Docker 就是完美方案。它也会让数据库升级变得非常简单。对 Postgres 来说,进行大版本升级时需要同时具备新旧两个版本。用 Docker 的话,这几乎就是多下载一次的事情:使用新版本的基础镜像,启动后快速拉取旧版本,执行迁移,再删掉旧的容器镜像。完成。
不过,在我们回头继续处理其他延迟因素之前,新的问题已经开始逼近了。
当 KubeVirt 开始不再适合我们
我们想先说清楚:下面这些问题并不意味着“KubeVirt 很差”。 事实上,KubeVirt 解决的是一个非常困难的问题,而且它是用最“Kubernetes”的方式来解决的。
但我们的目标行为,也就是快速、高频、弹性、并且“长得像数据库”的 VM,给系统施加的是另一类压力。它不是典型的“长生命周期”VM,也不是那种使用场景永远不变的工作负载。KubeVirt 非常适合那些想要 Kubernetes 的便利性,同时又想保留传统 VM 生命周期和隔离特性的场景。可我们偏离了这种典型路径,这一点开始越来越明显。
扩展一台虚拟机,并不等于扩展一个 pod
第一个摩擦点在于,CPU 和 RAM 的 VM 资源扩缩容,对我们来说不是偶发操作。我们希望尽可能频繁、尽可能快地动态扩容和缩容,甚至包括 scale-to-zero。
在 KubeVirt 中,这样的变更会立即触发 live migration。哪怕当前宿主机上仍然有足够资源,也一样。最痛的点在于,live migration 总是把 VM 迁移到另一个 Kubernetes worker。虽然 live migration 对性能的影响本身有限,但让虚拟机不断在节点之间移动,对我们来说完全不可接受。
“Current hotplug implementation involves live-migration of the VM workload.” KubeVirt Authors, “Memory Hotplug” documentation (KubeVirt.io)
对于典型的 VM 生命周期来说,这个设计决策很合理。但对我们而言,它意味着每一次“resize”都会演变成“搬动整个世界”,进而带来网络复杂性和数据库连接稳定性问题。
我们需要一种方案:只有在确实没有资源可用时才 live-migrate 虚拟机,而平时则允许 CPU 和 RAM 在本地完成扩缩容。
live migration 和 TCP 会话是个很残酷的组合
我们还撞上了另一个更残酷的现实:只有当你的网络栈和迁移管线能够维持工作负载所依赖的不变量时,live migration 才能称得上“无缝”。Postgres 客户端对长时间停顿非常不宽容。
数据库对延迟敏感,而且是连接导向的。我们的内部测试表明,在持续连接测试下,哪怕非常细小的中断也会很快显现出来。像 passt 这样的方案确实减轻了一部分问题,但在中到高强度的 pgbench 负载下,我们仍然会看到连接断开。
而且看起来我们并不是唯一的受害者。KubeVirt 社区已经有公开 issue 和讨论,围绕迁移后的网络问题。例如有一个长期存在的报告指出,迁移之后 masquerade 接口上的连通性可能会中断。另外一些社区成员则描述了 迁移过程中底层 pod/network identity 变化导致连接丢失 的情况。
我们需要的是真正的 overlay networking。
双层资源记账:Pod 与 VM
另一个坑是,资源控制发生在栈的多个层级上。
- 虚拟机层,也就是 QEMU 认为 VM 拥有多少资源。
- Pod/Cgroup 层,也就是 Kubernetes 实际施加在 virt-launcher(QEMU)pod 上的限制。
在我们的实验中我们发现,CPU 和内存分配必须在 VM 层和 pod 层同时被有效管理。只更新 pod 层会导致 VM 内部出现 out-of-memory 问题。这和前面提到的扩展性问题是关联的。
为了缓解部分问题并支持 live resizing,我们不得不绕开 KubeVirt,直接用 libvirt 去更新 VM。与此同时还得非常小心,不能把系统搞坏,因为只要 KubeVirt 的虚拟机资源触发一次 reconciliation,任何“手工”修改都会被重新覆盖掉。
我们需要一种更安全的做法。
该继续往前走了
我们多次遇到这样一种情况:想做的事情需要依赖不属于支持 API 表面的 workaround,而下一次 reconciliation 又会把它们全部抹掉。去 patch KubeVirt 意味着巨大的工作量,而我们并不想为了继续前进就长期背着这样一个核心项目的 fork。
于是我们问自己:
- “KubeVirt 是 Kubernetes 的优秀虚拟化 API 吗?” 是的。
- “KubeVirt 是适合我们的 branch 生命周期和扩展模型的抽象吗?” 我们认为不是。
于是我们做了开源建设者会做的事:寻找一种更符合我们需求的替代路径。基本只有两条路:找到更好的现成方案,或者彻底从零自己写一个、专门为此而生的方案。
我们最初的想法是直接构建一个基于 libvirt 或 QEMU 的自有抽象层。但在真正去看 KubeVirt 源码体量并开始拆解所需功能之后,我们意识到了前方工作量的规模。
把虚拟机和 Kubernetes 真正“嫁接”在一起,是一项非常艰难的工作。太多概念是天然分离的,而你又必须把它们重新整合起来。我们被吓到了。于是决定先去找找别的现成方案。找一个更接近我们需求的东西。然后我们运气不错。
转向:采用 Neon 的 Autoscaling
如果你能找到一个更符合需求的方案,那么更好的做法就是去找那个方案。我们也确实这么做了。
这个思路其实很简单,想一想就很自然:去看邻近公司在做什么。幸运的是,外面有很多数据库产品。很多都是开源的。很多都和 Postgres 相关。
当我们发现 Neon 的 Autoscaling 项目时,也意识到我们并不是第一个遇到这些限制的人。他们遇到过很多同样的问题,并选择为此写出自己的解决方案。Neon 的做法是彻底按“数据库形状”来设计的。它围绕 在 K8s 管理的 micro-VM(基于 QEMU)中进行 Postgres 垂直自动扩缩容 展开。而且他们还解决了最棘手的部分:“在改变资源或迁移工作负载时,不要中断 TCP 连接。”
Autoscaling 最有意思的地方,在于扩缩容决策是如何做出的,以及扩缩容本身是如何生效的。
首先,Autoscaling 使用 Cgroups 来限定资源(CPU 和内存)的使用范围,以便做用量统计。为了捕获“宿主”(来宾 VM)的使用情况,它依赖通过 Prometheus 收集到的指标。每隔几秒,系统就会根据当前使用情况评估是否需要扩容或缩容。此外,虚拟机内部的 agent 还可以主动请求扩缩容决策,不过这个请求也可能被否决。
由于 Autoscaling 底层使用的是 QEMU,所以 CPU 和内存都可以 hot-plug。也就是说,在运行时可以按需向虚拟机附加或移除 CPU 核心。内存也类似,使用的是 virtio-mem 设备,可以在运行中增加或移除。在拆除 virtio-mem 设备之前,Linux 内核会先把相关内存区域迁走并释放掉它(和 memory ballooning 有些类似)。
“We want to dynamically change the amount of CPUs and memory of running Postgres instances, without breaking TCP connections to Postgres.” Neon Autoscaling README (GitHub)
Autoscaling 的组件
Autoscaling 本身是一组协同工作的组件,共同实现 Kubernetes 上的 serverless Postgres。
- 一个 controller(neonvm-controller),用于管理虚拟机资源(CRD)。
- 一个 scheduler,用于评估节点容量并决定 VM 的放置与替换。
- 一个 per-node agent(daemonset),负责收集和上报 VM 的资源使用情况。
- 一个与工作负载并行运行的 VM monitor,通过 Prometheus 上报使用情况,并带有 cgroup 专用配置。
- 一个 VXLAN manager,与 Flannel 配合,通过虚拟网络接口和 overlay networking 保证持续连通性。
- 一个封装 VM 的 runtime image,负责提供 VM 镜像、启动 QEMU、处理 DHCP/port forwarding,以及管理挂载。
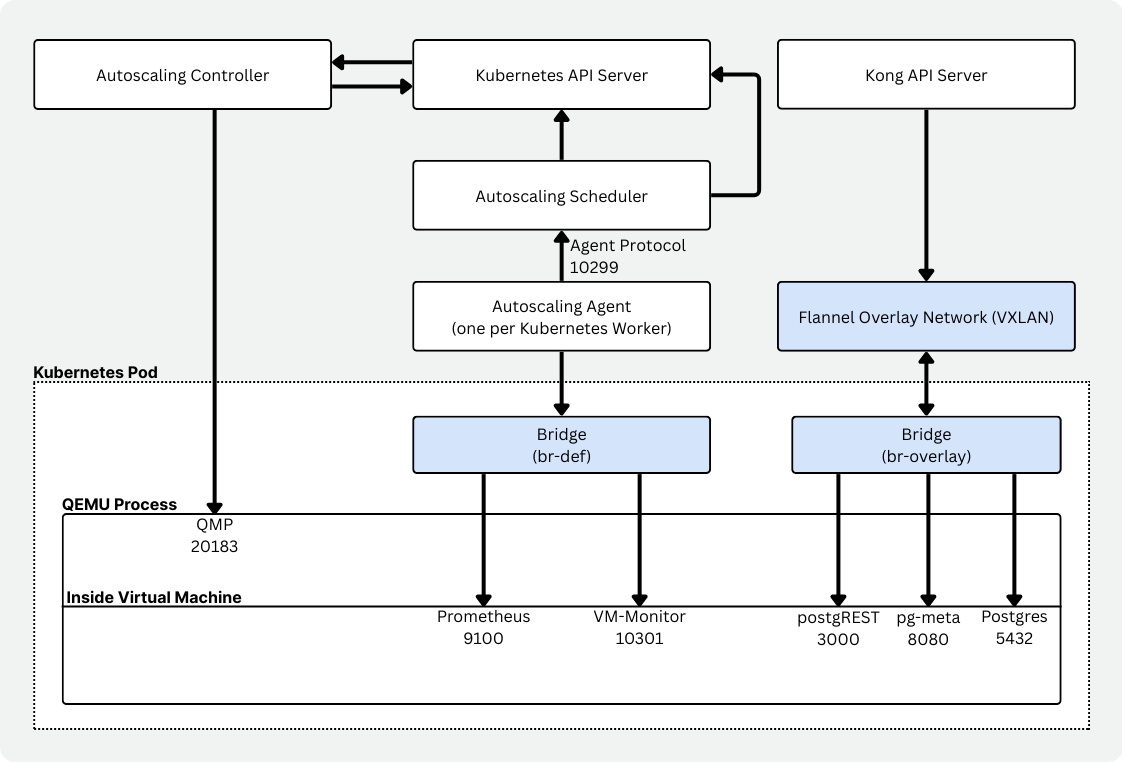
你会发现这里仍然是同样的概念分层:定制 scheduler、每个节点上的 autoscaling-agent,以及能够立即响应内存压力的 vm-monitor。对 Vela 来说,这显然更匹配。
感谢 Neon 团队在 Autoscaling 上做出的出色工作。
不过仍然需要一些改动
尽管 Autoscaling 已经非常贴合我们的需求,但由于 Neon 和 Vela 实现方式不同,仍然有一些“粗糙边缘”需要处理。
首先,由于我们底层主存储使用 simplyblock,我们需要支持为虚拟机附加一个或多个 PVC(Persistent Volume Claim)。
接着,我们还想对 CPU 和 RAM 使用设置上限,同时又不失去 live 更新这些限制的能力。不幸的是,QEMU 需要提前知道一个 VM 在任意时刻理论上最多可以附加多少 CPU 和 RAM。我们必须把这些值设置得远高于我们实际预期用户会扩到的程度。因此,我们在决策过程中加入了 soft limit。当前 VM 的 hard limit 是 128 vCPU 和 256 GB 内存。soft limit 则表示当前允许的最大扩展规模,比如 8 vCPU 或 16 GB 内存。超过 soft limit 的请求会被拒绝。
最后,我们还加了一个简单的 PowerState,让我们只需更新 CRD 中的值,就能启动或停止虚拟机。纯粹是为了方便。
赢下启动时间:杀掉“VM 里的 Docker”
当 Autoscaling 解决了生命周期和扩展上的大部分摩擦之后,我们终于可以回到真正的问题:启动时间。真正的突破来自于我们对自己诚实了一点。我们在启动路径里做的事情,坦白说很蠢。我们为了自己的方便牺牲了用户体验。我们先启动一个通用 Linux 发行版,再启动 Docker,然后再通过容器镜像编排多个服务。于是我们直接把这一整层“内部容器层”删掉了。
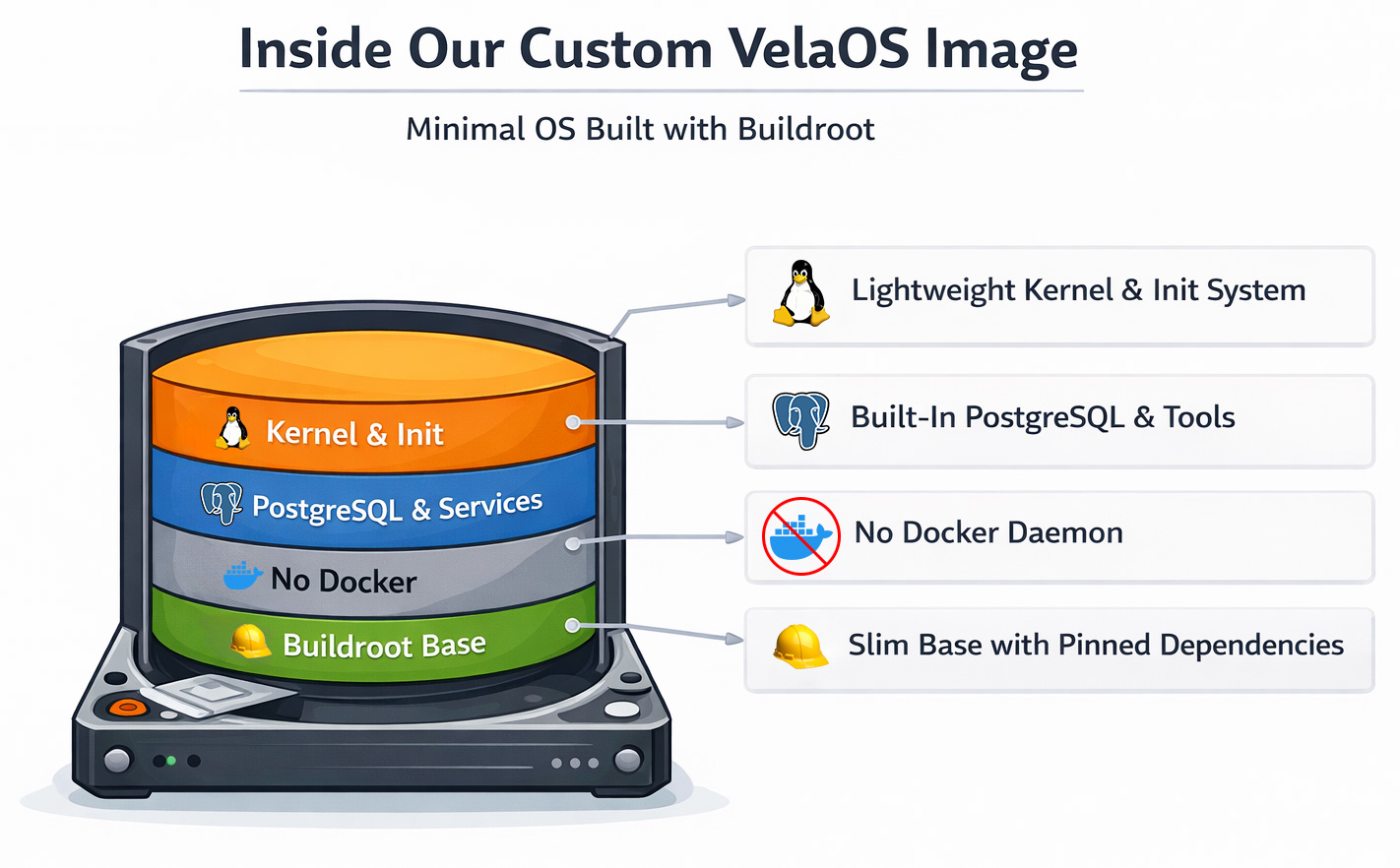
VelaOS:基于 Buildroot 的定制 Linux 内核和 rootfs
我们转向了一个 基于 Buildroot 的定制 Linux 镜像。Buildroot 本身是一个用于构建 Linux 内核和最小 root filesystem 的框架。它最初面向嵌入式设备,支持只读文件系统镜像、设备更新器等等。
即便你以前可能没直接接触过 Buildroot,它实际上是一个被广泛使用的系统。更知名的使用者包括 OpenWRT、Home Assistant OS(HAOS),以及像 Google Fiber 这样的嵌入式设备厂商。Buildroot 的一个显著特征就是可以生成极小的 root filesystem。
切换到 Buildroot 之后,除了去掉 Docker 本身,我们还很快得到了一些额外收益:
- 启动过程变得可预测,因为我们使用 inittab 作为基础 init 系统,可以精确控制什么在什么时候启动。
- 不再需要 Docker pull,因为所有服务都集成进了启动镜像。
- 更快的启动速度,因为我们不再使用通用操作系统镜像,而是使用优化过的 Linux 内核。
- 可重现构建,每个组件都固定到特定版本或 commit 以及 checksum,从而保证只构建未被篡改的组件。
代价则是开发迭代速度有所下降。Buildroot 作为构建框架,会自己构建最终镜像中的大多数组件。这样它能生成极小的磁盘镜像,但代价是更长的 build 时间。不过借助 CCache 和其他优化技术,这依然处于可接受范围内。
最终形成的启动路径非常简单:
- Kubernetes 根据 Autoscaling scheduler 的决策为 VM pod 调度节点
- runtime 使用我们的 VM 镜像启动 QEMU
- guest 启动一个已预装所需服务的最小 OS
- Postgres 以及 branch 所需的辅助服务立刻就绪(无需下载)
这条路径仍有改进空间。但现阶段,我们认为 <10 秒已经足够好。Vela 的价值在于:“branch 出现得快、行为稳定、隔离坚实。”
隔离与扩展性:为什么它仍然像 Kubernetes
一个很自然的担忧是:“如果你们离开了 KubeVirt,开始自己做 VM plumbing,那不是失去了 Kubernetes 的易用性吗?”
在实践中,我们保留了 Kubernetes 最重要的部分。我们依然通过 CRD 和 controller 实现声明式控制,让系统去 reconcile 目标状态。调度依然通过 Kubernetes 完成,而具体 placement 又会受到 Autoscaling scheduler 和 agent 的影响。节点级资源约束为 placement、scaling 和 migration 提供依据,这些判断基于真实的节点容量和实际 VM 使用情况。最后,隔离边界则通过“每个数据库 branch 都拥有自己的 VM 边界”来强制实现。
与此同时,我们仍然保留了把 Vela branch 从一个 Kubernetes worker 完整 live-migrate 到另一个 worker 的可能性,而且不会破坏已有的 Postgres 连接。
快速启动也是 control plane 的能力
但 10 秒内启动并不只是更好的用户体验。它还会改变你构建系统的方式,以及你会构建什么:
- Vela 可以更激进地扩容,因为增加容量的代价足够低,不管是通过更多虚拟机进行水平扩展,还是通过 VM 限额 live resizing 进行垂直扩展。
- Vela 可以把环境视为临时性的,因为重建成本低,而且存储与计算完全分离。
- Vela 可以通过替换 VM 而不是修复 VM 来吸收故障。
这就是一种系统应该具备的形状:最终它可以服务用户、智能体和 CI 工作流,而不会让用户一直等待。
经验总结:事情永远比你想得更复杂!
真正的争论不是“VM vs container”,而是启动路径的确定性。
我们出于正确的原因从 VM 开始(迁移成熟度、强隔离),但最糟糕的延迟来自我们自己对方便和快速迭代的偏爱。Docker 启动、镜像拉取,全都算在内。一旦我们去掉“启动时拉镜像”,time-to-ready 就不再是碰运气。
Kubernetes 的 reconciliation 既是朋友,也是敌人。
如果你发现自己在“绕开 reconciler 做事”,那通常意味着你已经偏离了系统预设的扩展模型。此时要么回到被支持的模式,要么选择一个更符合你控制需求的底层基座。
最快的优化通常就是删除东西。
就像最快的代码往往是从未执行的代码一样,最快的优化通常是删掉不必要的组件。对我们来说,彻底移除 Docker Compose 和镜像拉取,直接消除了数分钟的不确定性。
live migration 不是一个单点功能,而是一整块产品表面。
KubeVirt 和 Autoscaling 对迁移的处理方式截然不同。在 KubeVirt 中,几乎任何 CPU 或内存配置变化都会落到 live migration 上;而 Autoscaling 则尽量在现有 VM 实例上完成处理,只有当物理资源紧张时才退回迁移。另一个巨大差异是,它通过真正的 overlay network 而不是 Kubernetes 网络平面上的小技巧来获得稳定网络身份。对于数据库型工作负载来说,“它被迁移了”这一事件必须对客户端完全不可见,否则你一辈子都会在和重连风暴与尾部延迟作斗争。
最小化 OS 镜像不只是为了速度。它还能降低运维熵。
一个小而专用的镜像拥有更少的可动部件。这意味着更少的意外交互、更少在后台“帮倒忙”的守护进程,以及在出问题时更小的调试面。借助基于 Buildroot 的 VelaOS,我们还实现了可重现构建,并获得了在任何时刻都能精确知道 VM 内有哪些内容(数据除外)的能力。
不要害怕自己会害怕。有时候,这正会带来更好的结果。
当我们认真评估是否要自己构建 KubeVirt 替代品时,那项工作的范围确实让人害怕。正是这种害怕,逼着我们花时间去寻找是否已经存在更合适的方案。这最终把我们带到了 Autoscaling。而我们很庆幸自己当时被吓到了。
KubeVirt 正在为 Kubernetes 生态做重要的工作。
如果不是 KubeVirt 率先把虚拟机带入 Kubernetes,也许我们今天不会站在这里。值得明确地说:KubeVirt 正在为整个生态做重要的工作。即使在我们碰到限制的地方,这个项目也仍在积极演进。例如,KubeVirt 社区自己也在跟踪围绕 migration targeting 和 resize coupling 的改进,从 #15625 这样的 issue 中可以看到。此外,KubeVirt 还在持续记录真实世界集成案例,例如它如何与云环境中的 Cluster Autoscaler 协同工作。
我们接下来想去哪里
我们并不把这看作“KubeVirt vs Neon Autoscaling”。在 Kubernetes 上运行 VM 有多种合理方式,最佳选择取决于你的工作负载形状。
KubeVirt 仍然是一个强大、通用的 Kubernetes 虚拟化层,我们也依然在密切关注它的进展。
但对于 Vela 的核心目标,比如拥有强隔离的快速临时数据库 branch,我们需要的是一个毫不掩饰地为数据库优化的 control plane 和 runtime path。
Neon 的 Autoscaling 提供了正确的基础,而 Vela OS 则让启动时间变得可预测。
如果你也在这个领域构建类似的东西,我们非常愿意聊聊你的经验、决策以及更多边缘场景。尤其是关于网络、迁移行为或者 VM 镜像设计。
在不久的将来,我们会开始把自己做的改进逐步 upstream 回去。我们相信健康的开源生态,希望把这些变化共享出来,而不是私下保留。
如果你想体验并测试我们的 Vela Postgres 实例,可以在 https://demo.vela.run 创建一个免费账号。Vela 是完全开源的,目标是在你自己的数据中心或私有云中进行 self-hosting。目前我们正在清理代码库、修复剩余 bug,并实现面向用户的安装流程。