
简短版本:当查询变慢时,大家首先想到的通常是索引。PostgreSQL 提供了很多索引手段:多列索引、部分索引、表达式索引。问题在于成本。索引越多,存储、维护和写入代价就越高。而很多人忽视了 CREATE STATISTICS。扩展统计可以用几乎可以忽略的存储成本,显著改善 planner 的判断。
很多糟糕执行计划的根源,并不是 planner “不聪明”,而是它在基于错误的数据画像做出完全理性的决策。当多个谓词之间存在相关性时,单列统计就不够了。扩展统计正是为此而生。
简短版本
CREATE STATISTICS 允许 PostgreSQL 收集普通列统计难以表达的额外信息。
它最常见的收益场景主要有四类:
- 跨多列的相关过滤条件,
- 多列
DISTINCT估计, - 严重偏斜的值组合,
- 那些你原本想通过表达式索引解决的表达式问题。
–-- Alternative to index on expressions CREATE STATISTICS stats_expr ON (date_trunc(‘day’, created_at)) FROM events; --- What people normally mean by --- extended statistics CREATE STATISTICS stats_multi (dependencies, ndistinct, mcv) ON plan_tier, region, billing_status FROM tenants; |
第一种形式适合 date_trunc、JSONB 提取等表达式统计。第二种则是大多数人理解中的“extended statistics”。
最重要的三类是 dependencies、ndistinct 和 mcv。而且和普通统计一样,CREATE STATISTICS 只是定义对象,真正填充数据的是 ANALYZE。
为什么需要扩展统计?
默认情况下,PostgreSQL 主要维护按列的统计信息。只要过滤条件可以近似看成独立事件,这种方法就足够好。一旦列与列之间的关系变得重要,问题就开始出现。
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
在真实数据里,这样的条件往往是相关的。但如果没有额外统计,PostgreSQL 会把它们当成彼此独立的过滤器。结果就是:数学上整齐,现实中荒谬。
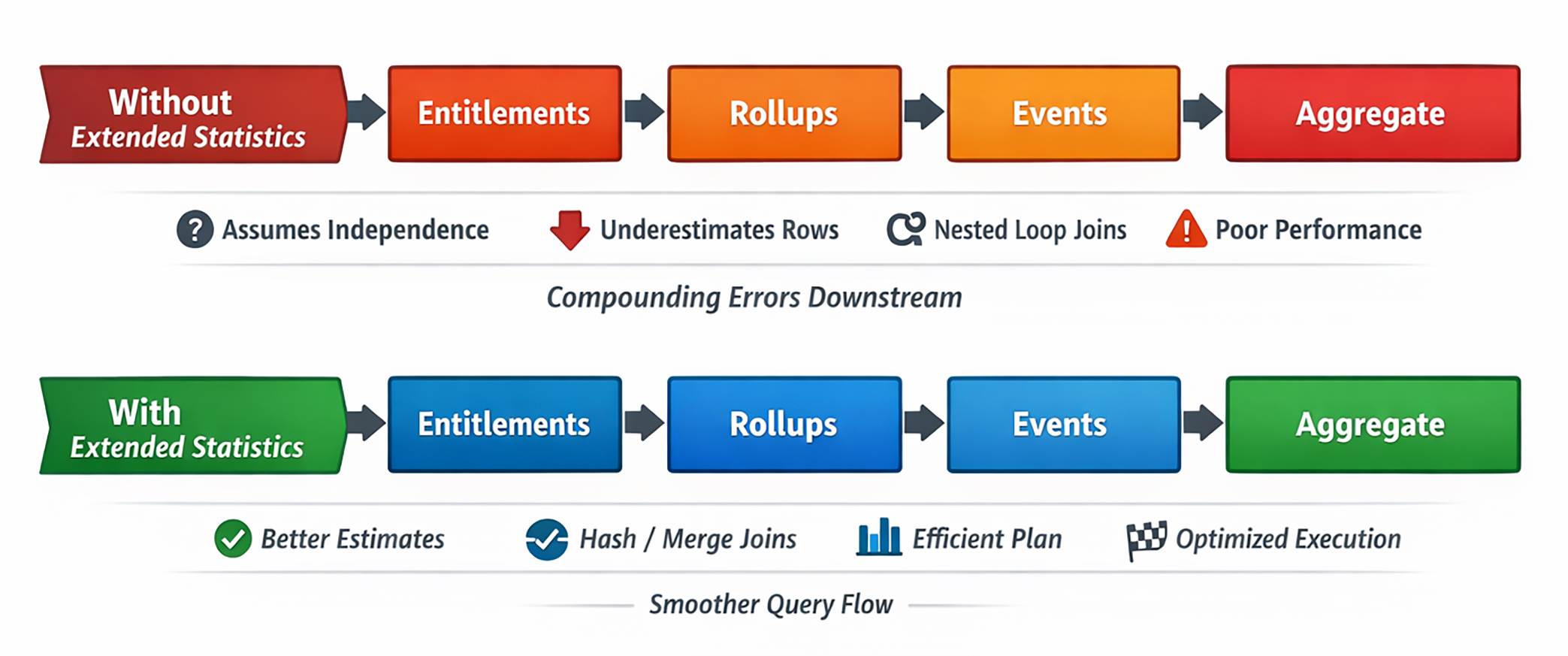
而只要起点估计错了,后面的几乎所有东西都会一起偏掉:join 顺序、join 类型、并行策略、hash 大小、排序方式、spill 风险。
Postgres 默认知道什么
每次执行 ANALYZE 时,PostgreSQL 都会为每一列记录空值比例、直方图、常见值、distinct 数等信息。这些都很有用,但它们依然只是单列知识。
假设有一张 100 万行的表,分布如下:
plan_tier = 'enterprise'命中 6 %region = 'eu-central'命中 25 %billing_status = 'active'命中 80 %
1,000,000 * 0.06 * 0.25 * 0.80 = 12,000 rows |
问题在于,这些列在真实世界里往往不是独立的。真正的答案可能是 40,000 行,也可能是 60,000 行,甚至只有 5,000 行。单列统计无法回答这个问题。
扩展统计的基准测试
为了更具体地说明这一点,我构造了一个合成但有意做得很真实的 SaaS analytics workload,包含四张表:tenants、tenant_entitlements、usage_rollups 和 analytics_events。
这个数据集被专门设计成会暴露 planner 的盲区:plan、region 和 billing status 之间的相关性,premium entitlement 的集中分布,以及并不随机的 (tenant, feature, day) 组合。
它当然是合成数据,但这种“合成”更像风洞实验:为了隔离真实现象而构造出来的可控环境。
通过数据形状隔离问题
表:tenants
租户分段列之间的相关性,和真实 SaaS 数据里经常看到的情况非常接近。
表:tenant_entitlements
sso、audit_logs、workflows 这类 premium feature 更集中在 enterprise tenant 上。
表:usage_rollups
这张表模拟了每个 tenant-feature 组合在时间维度上的现实 fanout。
表:analytics_events
这里是高基数爆炸点。每一个通过前面过滤条件的 tenant-feature 组合,都可能对应大量原始事件行。
报表查询
业务问题很简单:“在某个重要区域中的活跃 enterprise tenant 里,哪些 premium feature 最近最活跃?”
SELECT e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.region = 'eu-central' AND t.billing_status = 'active' AND te.entitlement IN ('sso', 'audit_logs') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY e.feature_name ORDER BY rolled_requests DESC; |
如果要跨多个区域一起分析,则使用带 CTE 和后续聚合的扩展版本。
WITH regional_feature_totals AS ( SELECT t.region, e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') AND te.entitlement IN ('sso', 'audit_logs', 'workflows') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY t.region, e.feature_name ) SELECT region, feature_name, total_events, rolled_requests FROM ( SELECT region, feature_name, total_events, rolled_requests, row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank FROM regional_feature_totals ) ranked WHERE regional_rank <= 3 ORDER BY region, regional_rank; |
拆解这条查询的结构
阶段 1:定义 tenant slice
WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') |
如果 PostgreSQL 在这第一步就估错,后面所有 fanout 都会建立在错误的人群基数之上。
阶段 2:限制到有权限的 feature
JOIN tenant_entitlements te ON te.tenant_id = t.id ... AND te.entitlements IN (...) |
entitlement 表在这里既是 join 目标,也是一个相关的 feature 过滤器。
阶段 3:绑定最近使用情况
JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement ... AND r.rollup_day >= CURRENT_DATE - 30 |
在这里 multiplicity 开始累积。一个 tenant 可能有多个匹配的 entitlement,一个 tenant-feature 组合也可能有多个最近的 rollup day。
阶段 4:扩展到原始事件
JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name ... AND e.event_type IN (...) |
到了这一步,行数估计的错误就会变得非常昂贵。Nested Loop 在纸面上看起来可能很便宜,实际上却完全不是。
阶段 5:再把爆炸结果收回来
GROUP BY e.feature_name ORDER BY rolled_requests DESC |
GROUP BY t.region, e.feature_name |
最终结果集很小,但得到它的过程并不小。这正是这条查询特别适合作为 planner 演示的原因。
阶段 6:multi-region 查询中的 ranking
row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank ... --- followed by WHERE regional_rank <= 3 |
这里又增加了排序压力和 temp I/O 压力。也就是说,这不只是 join 和聚合的问题,同时也是 ranking 问题。
扩展统计如何救场
面对这种问题,第一反应通常是加更多多列索引、部分索引甚至表达式索引。这里我们改用三个统计对象,直接修正 planner 的错误假设。
- tenant 列之间的相关性,
- tenant 与 entitlement 的组合,
- rollup 组合。
当然,创建之后必须重新执行 ANALYZE。
类型:dependencies
函数依赖统计帮助 PostgreSQL 理解:某些列足够强地预测另一些列,因此把它们看成独立变量是错误的。
- 国家通常强烈预测货币。
- 州通常强烈预测时区。
- tenant segment 通常强烈预测 entitlement 家族。
CREATE STATISTICS stats_tl_segment_dependencies (dependencies) ON id, plan_tier, region, billing_status FROM tenants; |
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
可以这样记:dependencies 修正的是“这些过滤条件并不独立”。
类型:mcv
MCV 的字面意思是“most common values”,但在扩展统计里更适合理解成“most common combinations”。
CREATE STATISTICS stats_tl_segment_mcv (mcv) ON plan_tier, region, billing_status FROM tenants; |
这样 PostgreSQL 就能学到哪些组合特别常见、特别稀少,甚至根本不出现。可以这样记:mcv 修正的是“这个具体组合和平均值不一样”。
类型:ndistinct
ndistinct 告诉 PostgreSQL,多列组合真正有多少种不同取值,而不只是知道每一列单独的 distinct 数。
CREATE STATISTICS stats_tel_entitlement_ndistinct (ndistinct) ON tenant_id, entitlement FROM tenant_entitlements; CREATE STATISTICS stats_url_feature_ndistinct (ndistinct) ON tenant_id, feature_name, rollup_day FROM usage_rollups; |
可以这样记:ndistinct 修正的是“这些 group-by 或 join 组合并没有 planner 以为的那么多”。
PostgreSQL 实际存了什么
这里就很有意思了。我们当然也可以用更多索引来解决上述问题。但索引在维护和存储上都很贵。
而扩展统计则惊人地便宜。它们的定义存放在 pg_statistic_ext 中,收集的数据存放在 pg_statistic_ext_data 中。
pg_statistic_ext记录有哪些统计对象。pg_statistic_ext_data记录实际收集到了哪些数据。
在这次基准测试里,所有统计对象总共只占了大约 2,059 字节:
- Tenant-Segment
mcv:约 1,049 字节 - Tenant-Segment
dependencies:约 518 字节 - Entitlement
ndistinct:约 220 字节 - Rollup
ndistinct:约 272 字节
这正是重点:它们不是巨大的“影子索引”,而是让 planner 少犯错的轻量元数据。
修正执行计划
最初我写这篇文章时,想重点证明的是更快的运行时间。确实有改善,但更重要的结果其实是:估计准确度明显变好了。
| Scenario | Average Time | Worst Estimate | Additional Storage |
|---|---|---|---|
| Extended statistics | 2,857.896 ms | 48.27x | 2.0 KiB |
| Baseline + Composite Join-Key Indexes | 5,882.659 ms | 106.48x | 37.64 MiB |
| Baseline + Events (feature_name, event_type, tenant_id) | 4,781.551 ms | 108.7x | 31.45 MiB |
| Baseline + Partial Hot-Path Indexes | 4,765.351 ms | 106.22x | 30.20 MiB |
| Extended Statistics + Partial Hot-Path Indexes | 4,876.187 ms | 46.65x | 30.21 MiB |
每条查询都执行了 5 次。完整执行计划和结果在 repository 中。
单区域查询
基线 schema 使用的是单列索引。它确实避免了完全顺序扫描,但 planner 仍然必须去猜测 tenants、entitlements、rollups、events 之间相关谓词的交集。
| Metric | Value |
|---|---|
| Average execution time | 14,168.174 ms |
| Average planning time | 4.134 ms |
| Execution samples | 31,093.955 ms, 29,065.788 ms, 3,564.811 ms, 3,570.114 ms, 3,546.200 ms |
| Planning samples | 5.058 ms, 3.952 ms, 8.969 ms, 1.899 ms, 0.793 ms |
| Join chain | Nested Loop:Inner -> Nested Loop:Inner -> Nested Loop:Inner |
| Scan nodes | Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Nested Loop: 178,389 estimated / 18,774,720 actual (105.25x) |
| Worst estimate path | Sort -> Aggregate -> Nested Loop |
引入扩展统计后,情况明显改善:
| Metric | Value |
|---|---|
| Average execution time | 2,857.896 ms |
| Average planning time | 3.025 ms |
| Execution samples | 4,318.854 ms, 2,612.261 ms, 2,396.848 ms, 2,467.702 ms, 2,493.816 ms |
| Planning samples | 6.719 ms, 2.067 ms, 2.128 ms, 2.243 ms, 1.970 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Hash: 12,966 estimated / 625,824 actual (48.27x) |
| Worst estimate path | Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash |
planner 不再把中间结果误以为特别小。还有一个非常关键的细节:估计总成本反而上升了。这不是退化,而是 PostgreSQL 终于开始相信一个更接近现实的数据模型。
多区域查询
在 multi-region 版本里,运行时间的改善更加明显。
基线:
| Metric | Value |
|---|---|
| Average execution time | 24,933.705 ms |
| Average planning time | 3.648 ms |
| Execution samples | 84,815.859 ms, 12,696.190 ms, 11,819.487 ms, 8,482.936 ms, 6,854.054 ms |
| Planning samples | 6.125 ms, 5.681 ms, 2.067 ms, 2.181 ms, 2.187 ms |
| Join chain | Merge Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Sort: 53,580 estimated / 17,164,496 actual (320.35x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Merge Join -> Sort |
加入扩展统计后:
| Metric | Value |
|---|---|
| Average execution time | 7,289.319 ms |
| Average planning time | 2.875 ms |
| Execution samples | 7,503.924 ms, 8,261.715 ms, 7,433.035 ms, 8,181.565 ms, 5,066.357 ms |
| Planning samples | 9.244 ms, 0.932 ms, 1.039 ms, 1.801 ms, 1.359 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Nested Loop: 68,387 estimated / 1,113,566 actual (16.28x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash -> Nested Loop |
这已经不是小修小补了,而是 PostgreSQL 终于回到了现实所在的同一个邮政编码。
查询真的更快了吗?
有时候是,有时候不是。也正因为如此,这个话题值得被更谨慎地看待。
单区域运行时间
- 基线平均值:14,168.174 ms
- 扩展统计平均值:2,857.896 ms
看起来很夸张,但基线数据被前两次极慢的运行严重拉高了。所以更稳妥的说法是:planner 理解变好了,而这在这个 workload 上也关联到了更好的稳定态表现。
多区域运行时间
- 只用统计:7,289.319 ms
- 最好的纯索引策略:6,886.473 ms
这并不削弱 CREATE STATISTICS 的价值。它只是说明:统计修正 cardinality 估计,索引提供物理访问路径,这是两个相关但不同的问题。
为什么索引对比很重要
最有意思的结果之一是:某些重索引方案在成本或运行时间上看起来不错,但在估计质量上仍然远远更差。
- 扩展统计:约 2.0 KiB
- 重索引替代方案:约 30.20 MiB 到 37.64 MiB

这正是最容易被低估的地方:只用大约 2 KiB 的元数据,PostgreSQL 就能少犯很多错;而基于索引的替代方案却要额外花几十 MiB,而且往往并没有真正解决 planner 的问题。
为什么“两个都用”并不会自动赢
我当然也测试了最直观的问题:扩展统计再加上最优索引,是不是一定更好?
答案是不一定。
Single-region:
- 只用统计:2,857.896 ms
- 统计 + Partial Hot-Path Indexes:4,876.187 ms
Multi-region:
- 只用统计:7,289.319 ms
- 统计 + Partial Hot-Path Indexes:8,950.207 ms
更多索引不仅仅意味着更多机会,也意味着 planner 的搜索空间发生了变化。所以“两个都上”不是自然法则,只是另一个要靠 benchmark 回答的问题。
实际使用中的 caveat
这里有几条非常值得明确说明的限制:
- 扩展统计只在 单个 relation 内部 生效。
- PostgreSQL 不会直接把它们用于 跨表 join selectivity 估计。
- 并不是所有 workload 都会受益。如果列之间确实接近独立,收益就会很小。
- 它不能替代好的查询设计、有用的索引、分区、合理的内存设置和快速存储。
它本质上是给 planner 提供更好信息的能力,而不是通用性能护身符。
什么时候该用 CREATE STATISTICS
实务上的规则很简单:如果某个计划看起来明显不对,而问题似乎和多列一起过滤或分组时 planner 的建模错误有关,那就应该在本能地继续堆索引之前,先想想 extended statistics。
好的候选场景包括:
- 强相关的过滤列,
- 由 segment 驱动的维度属性,
- cardinality 明显错误的 group-by workload,
- 多列 fanout 问题,
- 偏斜的高频值组合,
- 某个单表估计错误进而污染整个后续计划的情况。
不太适合的场景包括:真正缺的是物理访问路径、明显受 I/O 限制的 workload,以及列本身确实近似独立的情况。
可以使用 EXPLAIN (ANALYZE, VERBOSE, BUFFERS) 来验证。如果 estimated rows 和 actual rows 相差极大,那么扩展统计很可能值得一试。
比起技巧,更该追求真实
CREATE STATISTICS 最好的地方在于,它不是继续往数据上叠更多结构,而是给 planner 更多真实信息。
这些基准并没有说“扩展统计永远会赢”。它们说的是更有用的话:
- 它让 PostgreSQL 少犯了很多错。
- 它以有意义的方式改变了执行计划形状。
- 它几乎不消耗存储。
- 而且在很多情况下,它比再堆几十 MiB 索引更直接地解决了 planner 问题。
基准、查询和结果都在 GitHub 上。你也可以在我们的 Vela Postgres Sandbox 中自己跑一遍。
如果你曾经看着某个执行计划想过:“这个 join 根本没理由像穿着风衣一样套三层吧?”,那你很可能一直在找的就是扩展统计。