
Quando começamos a construir a Vela, tínhamos um objetivo muito específico, e um pouco teimoso: um novo ambiente Postgres precisava ficar pronto tão rápido que não parecesse “provisioning”. Não queríamos dizer “rápido para o boot de uma VM”; queríamos dizer o mais rápido possível. Rápido o suficiente para que platform engineers falassem em entrega instantânea, mas ainda com isolamento total.
Dito isso, tínhamos três restrições:
- Isolamento total entre bancos de dados com fronteiras duras, não apenas “isolamento em nível de namespace”.
- Resiliência total contra noisy neighbors com limites rígidos de CPU, RAM e atividade de disco.
- Escalabilidade nativa de Kubernetes com placement automático e replacement sem interrupção (live migration).
Embora o objetivo inicial da Vela pareça simples e direto, foi irritantemente difícil de atingir. Cada banco de dados (branch) na Vela recebe isolamento forte e a capacidade de escalar de forma dinâmica e independente. A sensação é a de um banco de dados em Kubernetes como deveria ser, mas com as garantias de isolamento de uma máquina virtual.
Este post conta como chegamos dali até boots abaixo de 10 segundos, mantendo isolamento total entre bancos de dados e um comportamento de escalabilidade que funciona naturalmente dentro do Kubernetes. No caminho, aprendemos bastante sobre o modelo do KubeVirt (e suas arestas), por que autoscaling de VMs é sutilmente diferente de autoscaling de pods, e por que uma imagem minúscula de sistema operacional customizado pode ser uma alavanca de performance maior do que quase qualquer flag de tuning.
Por que escolhemos máquinas virtuais
No começo, escolhemos VMs por um motivo pragmático: live migration de VM é um problema resolvido. Ela é suportada pela maioria dos hypervisors e ainda está significativamente à frente da live migration de containers em termos de maturidade. Nós realmente olhamos trabalhos de migração de containers (por exemplo zeropod), mas eles não batiam com nossas restrições. Eles lidavam bem com escalabilidade, inclusive até zero, mas não atendiam ao nosso requisito de live migration sem interrupção.
Kubernetes também não era negociável. Para a maioria dos times de plataforma, Kubernetes é “o substrato”, e espera-se que todo o resto se integre ao seu scheduling, observability e lifecycle operacional.
Então fizemos o óbvio: rodar Postgres dentro de VMs que ainda fossem controladas como objetos do Kubernetes. KubeVirt foi projetado exatamente para isso: ele estende a API do Kubernetes com tipos de VM e executa o “payload” da VM por meio de um pod que inicia o QEMU/KVM.
Primeira tentativa: KubeVirt, Docker e boots frustrantes
Máquinas virtuais em Kubernetes? Isso é KubeVirt. Como todo mundo, essa também foi a nossa resposta. Quão difícil isso poderia ser?
Nossa primeira iteração inicializava em cerca de 2 minutos em um bom dia e até 5 minutos em um dia ruim. Instantâneo o bastante, certo? 🫣
Os tempos de boot da própria VM nem eram tão ruins. O problema é que inicializar a VM era só o começo. Nós iniciávamos Docker (Compose) dentro da VM e então fazíamos pull e load de várias imagens de container por branch, basicamente todos os serviços de cada branch (Postgres, PGBouncer, PostgREST, …). O throttling do Docker Hub e a “loteria do image pull” acabaram sendo uma fonte brutal de tail latency.
O processo de boot era duro:
- Kubernetes cria os recursos de VM do KubeVirt
- O recurso de VM inicializa o QEMU
- O sistema operacional guest sobe
- O serviço Docker fica disponível
- O Docker baixa as imagens individuais de container
- O Docker inicia os containers um a um de acordo com o grafo de dependências
- Os containers sobem e ficam healthy
- Nós marcamos o branch como ativo (healthy)
Sabíamos que baixar as imagens toda vez que uma VM subia não era o ideal, mas não esperávamos que fosse tão ruim. O principal problema está em como o Docker lida com downloads de imagem e startup de containers. Basicamente, ele baixa todas as imagens primeiro e só depois as inicia de acordo com o grafo de dependências. Uma imagem grande ou lenta (por throttling), e o dia acabou. Cada imagem extra aumenta a chance de você cair num dia ruim.
No fim, identificamos três componentes que amplificavam a latência, listados em ordem de impacto (do maior para o menor):
- Image pull e throttling de registry para disponibilizar as imagens dos serviços do branch.
- O startup em dois níveis com a VM e os containers Docker.
- Etapas adicionais de setup, como registrar o nome DNS, provisionar um novo disco, rodar o initdb do Postgres e coisas parecidas.
Vamos fazer pre-cache das imagens Docker
Primeiro, precisávamos eliminar o problema do download constante. Se seu caminho de boot inclui “baixar dependências”, você não tem tempo de boot. Você tem uma distribuição de probabilidade.
Já estávamos construindo uma imagem de VM, então por que não “simplesmente” pré-baixar todas as imagens de container necessárias durante o processo de build?
Falado e feito. Ou seja, ajustamos o processo de build para incluir uma etapa que baixa todas as imagens Docker necessárias e as embute na imagem final de boot da máquina virtual.
Isso funcionou muito bem. A maior fonte de variabilidade no tempo de boot desapareceu. Ficamos com uma base bastante consistente de 90-100 segundos. Ainda assim, muito tempo continuava sendo gasto no boot da imagem Linux e esperando o serviço Docker ficar disponível, até finalmente podermos subir os nossos serviços reais de branch. Para uma primeira tentativa, isso era suficiente. Mas sabíamos que havia espaço para otimização não apenas deixando de usar uma imagem Linux típica, e sim melhorando o procedimento de boot em si.
Por que Docker?
Uma das perguntas que continuava aparecendo era: “Por que diabos vocês usaram Docker dentro da VM?”
A resposta curta é uma palavra: conveniência.
A resposta longa é: a conveniência de ciclos de iteração mais rápidos usando diferentes imagens Docker e testando diferentes opções de serviço em potencial (como Pgpool-II, PGBouncer e outras).
Precisávamos da capacidade de experimentar sem reconstruir as máquinas virtuais, e o Docker era a solução perfeita naquele momento. Isso também tornaria upgrades de banco de dados bem simples. Em upgrades de major version no Postgres, você precisa de duas versões instaladas: a nova e a atual. Com Docker, isso ficava a um único download de distância. Usar a imagem base da nova versão, baixar rapidamente a versão antiga após o boot, executar a migração e remover a imagem antiga. Pronto.
De todo modo, antes mesmo de conseguirmos voltar aos outros fatores de latência, outros problemas começaram a aparecer.
Quando o KubeVirt começou a falhar para nós
Queremos deixar claro: nenhum dos problemas a seguir é simplesmente um caso de “KubeVirt é ruim”. Na verdade, o KubeVirt resolve um problema muito difícil e faz isso da forma mais Kubernetes possível.
O nosso comportamento-alvo (VMs rápidas, frequentes, elásticas e com formato de banco de dados) pressionava partes diferentes do sistema. Não era o caso típico de uma VM “long-lived” que nunca muda de uso. O KubeVirt é excelente se você quer a conveniência do Kubernetes e o lifecycle e o isolamento típicos de uma máquina virtual. Nós, por outro lado, nos afastávamos desse padrão, e isso começou a aparecer.
Escalar uma máquina virtual não é escalar um pod
O primeiro ponto de atrito foi que o escalonamento de recursos de VM para CPU e RAM não era raro para nós. Queríamos escalar para cima e para baixo de forma dinâmica, com a maior frequência e velocidade possíveis. Potencialmente incluindo scale-to-zero.
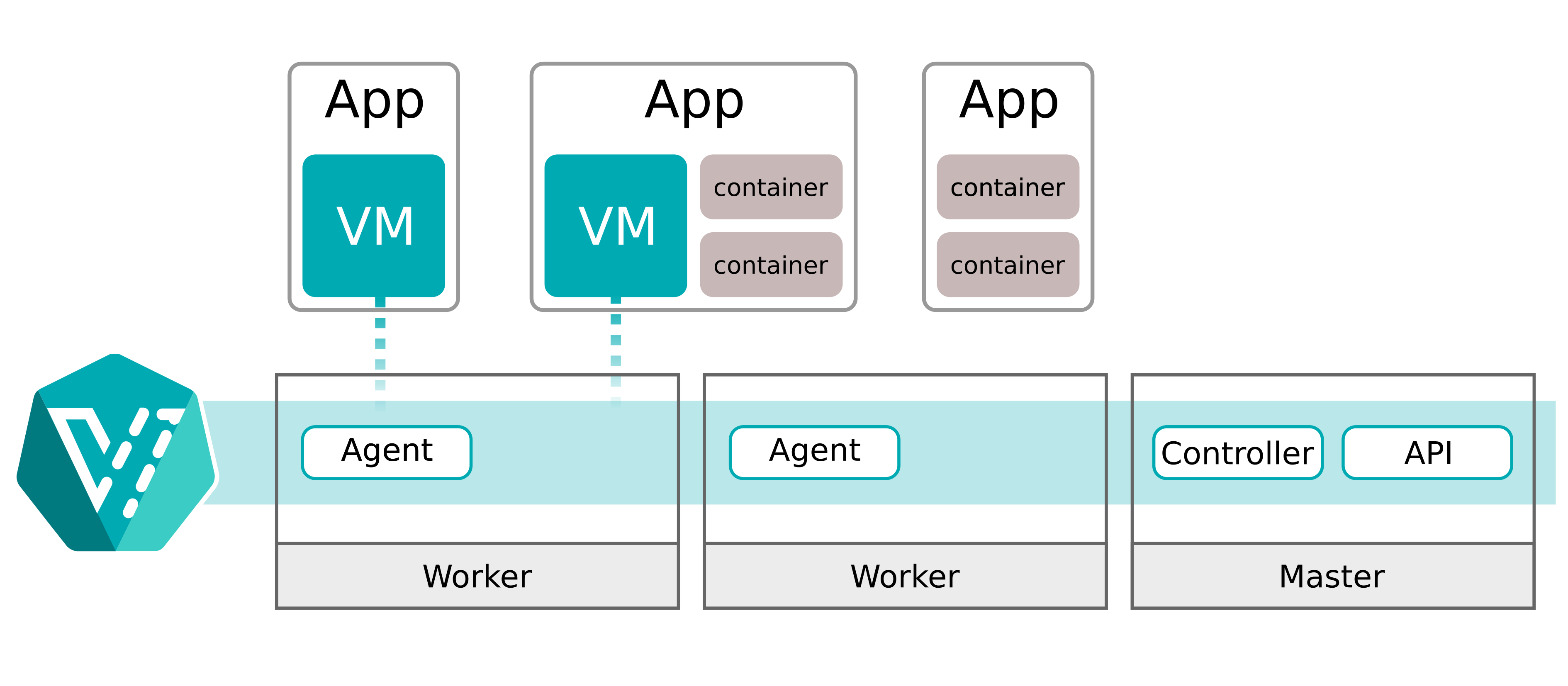
No KubeVirt, essas mudanças disparam uma live migration imediata. Mesmo quando há recursos suficientes no host atual. O principal ponto de dor é que a live migration sempre move a VM para outro worker do Kubernetes. Embora o impacto de performance da live migration seja limitado, mover constantemente as máquinas virtuais não funcionaria para nós.
“Current hotplug implementation involves live-migration of the VM workload.” KubeVirt Authors, “Memory Hotplug” documentation (KubeVirt.io)
Para um lifecycle típico de VM, essa decisão de design faz bastante sentido. Mas, para nós, isso significava que cada “resize” virava “mover o mundo”, com complexidade de rede em cascata e problemas de sustentabilidade das conexões ao banco.
Precisávamos de uma solução que só live-migrasse uma máquina virtual quando realmente não houvesse recursos disponíveis, permitindo scale up/down local de CPU e RAM.
Live migration e sessões TCP são uma combinação brutal
Também nos deparamos com uma verdade mais dura: live migration só é “transparente” se a pilha de rede e o pipeline de migração preservarem as invariantes que o workload assume. Clientes de Postgres não perdoam pausas longas.
Bancos de dados são sensíveis à latência e orientados a conexão. Nossos testes internos mostraram que mesmo as menores descontinuidades ficam visíveis rapidamente durante testes sustentados de conexão. Soluções sugeridas como passt reduziram parte da carga, mas ainda vimos conexões quebrando sob carga moderada a alta de pgbench.
E parece que não éramos os únicos. O KubeVirt tem issues públicas e discussões da comunidade sobre problemas de rede pós-migração. Por exemplo, há um relatório antigo de que, após a migração, a conectividade pode quebrar na interface masquerade. Outros membros da comunidade descreveram a perda de conexões porque a identidade subjacente de pod/rede muda durante a migração.
Precisávamos de um overlay networking de verdade.
Contabilidade de recursos em dois níveis: Pod vs VM
Outro detalhe incômodo: o controle de recursos acontece em múltiplas camadas da stack.
- O nível da máquina virtual é o que o QEMU acredita que a VM tem disponível.
- O nível do Pod/Cgroup é o que o Kubernetes impõe ao pod do virt-launcher (QEMU).
Nos nossos experimentos, descobrimos que alocações de CPU e memória precisavam ser gerenciadas de forma eficaz tanto no nível da VM quanto no nível do pod. Atualizar só o nível do pod causava problemas de out-of-memory dentro da VM. Isso está ligado ao problema de escalabilidade mencionado acima.
Para mitigar partes do problema e habilitar live resizing, tivemos de contornar o KubeVirt e usar libvirt para atualizar as VMs diretamente. Tivemos de tomar cuidado para não quebrar o sistema, porque um único evento de reconciliação em um recurso de máquina virtual do KubeVirt invalidaria qualquer atualização “manual”.
Precisávamos de uma forma mais segura de fazer isso.
Hora de seguir em frente
Batemos em várias situações em que precisávamos de workarounds que não se encaixavam de forma limpa na superfície de API suportada, e a próxima reconciliação desfaria tudo. Patchar o KubeVirt envolveria muito trabalho, e não queríamos carregar um fork duradouro de um projeto tão central apenas para continuar avançando.
Então nos perguntamos:
- “O KubeVirt é uma boa API de virtualização para Kubernetes?” Sim, é.
- “O KubeVirt é uma boa abstração para o nosso lifecycle de branches e nosso modelo de escalabilidade?” Nós achamos que não.
Então fizemos o que builders de open source fazem. Procuramos outra abordagem que combinasse melhor com nossos requisitos, e havia duas opções básicas: encontrar uma solução existente melhor ou escrever tudo do zero, purpose-built.
Nosso pensamento inicial foi construir nossa própria abstração em cima de libvirt ou até diretamente sobre QEMU. Mas, ao olhar o tamanho do código-fonte do KubeVirt e desenhar os recursos necessários, percebemos a dimensão do que havia pela frente.
Casar uma máquina virtual com Kubernetes é trabalho duro. Muitos conceitos divergem e precisam ser reintegrados. Isso nos assustou. Decidimos então procurar antes outras soluções. Algo mais próximo do que precisávamos. E tivemos sorte.
A virada: adotar o Autoscaling da Neon
A melhor abordagem é procurar outra solução se você puder encontrar uma que atenda melhor aos seus requisitos. E foi o que fizemos.
A abordagem era simples e óbvia, quando você pensa bem. Procurar empresas adjacentes e suas soluções. Felizmente para nós, existem muitos bancos de dados por aí. Muitos open source. Muitos relacionados a Postgres.
Quando encontramos o projeto Autoscaling da Neon, percebemos também que não éramos os primeiros a esbarrar nas limitações acima. Eles enfrentaram muitos dos mesmos problemas e escolheram escrever a própria solução. A abordagem da Neon era assumidamente “database-shaped”. Ela foi desenhada em torno do autoscaling vertical de Postgres dentro de micro-VMs gerenciadas por K8s (baseadas em QEMU). Eles também resolveram a parte mais delicada: “não quebrar sessões TCP quando você muda recursos ou move o workload”.
A parte mais interessante do Autoscaling é como as decisões de escalabilidade são tomadas e como a escalabilidade funciona na prática.
Primeiro, o Autoscaling usa Cgroups para delimitar os recursos (CPU e memória) para relatórios de uso. Para capturar o uso do “host” (a VM guest), ele usa métricas coletadas por Prometheus. A cada poucos segundos, o uso atual é avaliado em relação a potenciais eventos de scale up ou down. Além disso, o agente dentro da máquina virtual pode solicitar decisões de escala de forma proativa, embora essas solicitações possam ser vetadas.
Como o Autoscaling usa QEMU por baixo, CPU e memória podem ser hot-plugadas. Isso significa que, em runtime, núcleos de CPU são anexados e removidos da máquina virtual conforme necessário. A memória funciona de forma semelhante, usando dispositivos virtio-mem que podem ser adicionados ou removidos em runtime. O kernel Linux move as regiões de memória a serem removidas para liberar um dispositivo virtio-mem antes de destacá-lo (de forma parecida com memory ballooning).
“We want to dynamically change the amount of CPUs and memory of running Postgres instances, without breaking TCP connections to Postgres.” Neon Autoscaling README (GitHub)
Componentes do Autoscaling
O Autoscaling em si é um conjunto de componentes que trabalham juntos para habilitar Postgres serverless no Kubernetes.
- Um controller (neonvm-controller) para gerenciar os recursos de máquinas virtuais (CRDs).
- Um scheduler que avalia a capacidade dos nós e toma decisões de placement e replacement de VMs.
- Um agente por nó (daemonset) que coleta e reporta o uso de recursos das VMs.
- Um VM monitor que roda ao lado do workload e reporta uso via Prometheus, com configuração específica de cgroups.
- Um gerenciador VXLAN, garantindo conectividade sustentada com interfaces de rede virtuais e overlay networking (junto com Flannel).
- Uma runtime image que encapsula a VM. Ela disponibiliza a imagem da VM, inicia o QEMU, lida com DHCP/port forwarding e gerencia mounts.
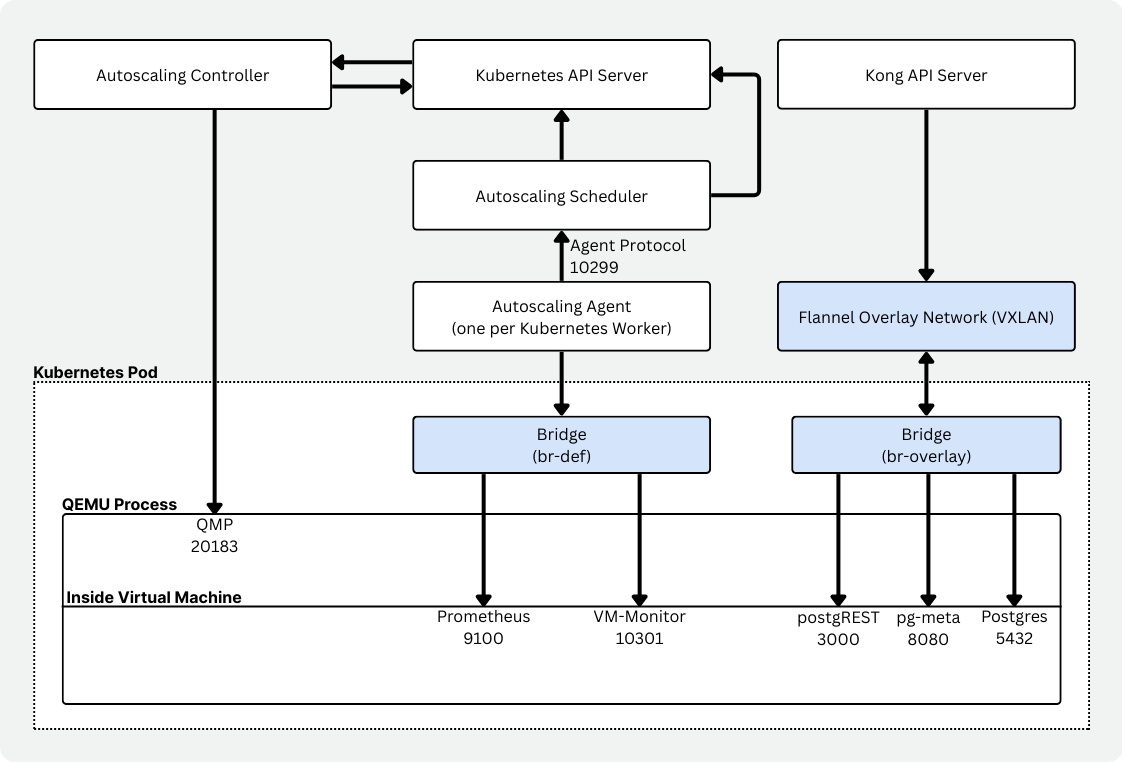
Aqui vemos a mesma divisão conceitual: um scheduler customizado, um autoscaling-agent por nó e um vm-monitor capaz de responder imediatamente à pressão de memória. Um ajuste muito melhor para a Vela.
Obrigado ao time da Neon por trás do Autoscaling por esse trabalho excelente.
Ainda assim, mudanças eram necessárias
Mas, por mais que o Autoscaling já fosse um ótimo encaixe, ainda havia algumas “arestas” por causa da diferença entre como Neon e Vela são implementadas.
Primeiro, com o simplyblock como storage subjacente principal, precisávamos de suporte para anexar um ou mais PVCs (Persistent Volume Claims) à máquina virtual.
Depois, queríamos uma forma de limitar o uso de CPU e RAM sem remover a possibilidade de atualizar esses limites em tempo real. Infelizmente, o QEMU precisa conhecer o máximo de CPU e RAM que pode ser anexado a qualquer momento. Precisávamos que esses valores fossem muito maiores do que esperávamos que as pessoas realmente alcançassem ao escalar. Então estendemos o processo de decisão com um soft limit. As VMs atuais têm um hard limit de 128 vCPUs e 256 GB de memória. O soft limit, no entanto, descreve os fatores máximos de escala correntes, como 8 vCPUs ou 16 GB de memória. Requisições acima do soft limit são recusadas.
Por fim, adicionamos um PowerState simples, que nos permite iniciar e parar a máquina virtual simplesmente atualizando esse valor no CRD. Conveniência pura.
Vencendo no boot time: matar o “Docker dentro da VM”
Agora que o Autoscaling resolveu uma grande parte da fricção de lifecycle e escalabilidade, era hora de voltar ao problema real: boot time. O verdadeiro avanço no boot time veio quando fomos honestos com nós mesmos. O que estávamos fazendo no startup era simplesmente idiota. Escolhemos conveniência para nós acima da experiência do usuário. Estávamos bootando uma distro generalista, depois bootando Docker e então orquestrando múltiplos serviços via imagens de container. Então removemos toda a camada interna de containers.
VelaOS: um kernel Linux customizado e rootfs baseado em Buildroot
Migramos para uma imagem Linux customizada baseada em Buildroot. O próprio Buildroot é um framework para construir kernels Linux e um root filesystem mínimo. Inicialmente pensado para dispositivos embarcados, ele suporta imagens de filesystem read-only, device updaters e mais.
Mesmo que você talvez nunca tenha ouvido falar diretamente de Buildroot, ele é na prática um sistema amplamente usado. Entre os usuários mais conhecidos estão OpenWRT, Home Assistant OS (HAOS), além de fabricantes de dispositivos embarcados como o Google Fiber. O Buildroot é conhecido por seus root filesystems mínimos.
Mudar para Buildroot nos trouxe alguns ganhos rápidos além de simplesmente eliminar o Docker:
- O processo de boot ficou determinístico usando o inittab como sistema init base para controlar exatamente o que sobe e quando.
- Sem mais Docker pulls, porque todos os serviços estão integrados à imagem de boot.
- Mais velocidade de boot, porque não usamos uma imagem de sistema operacional generalista, e sim um kernel Linux otimizado.
- Builds reproduzíveis, com cada componente fixado a uma versão ou commit específico e checksum, garantindo que apenas componentes não modificados sejam construídos.
Por outro lado, perdemos velocidade de iteração. O Buildroot, como framework de build, compila a maior parte dos componentes da imagem final por conta própria. Assim consegue imagens de disco incrivelmente pequenas, mas ao custo de tempo de build. Graças ao CCache e a outras técnicas de otimização, isso continuou sendo administrável.
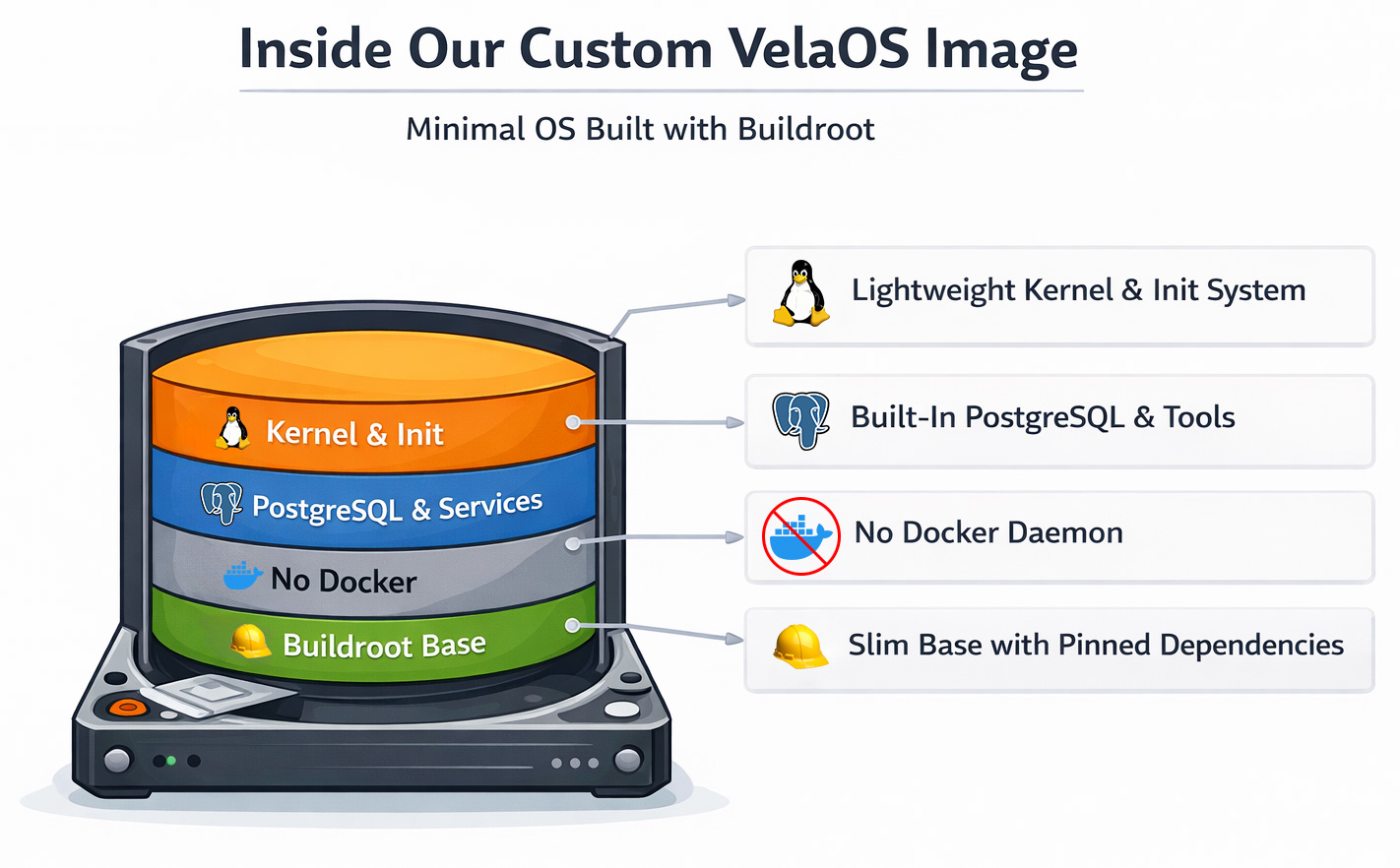
O caminho de boot resultante é simples:
- Kubernetes faz o scheduling do pod da VM (com base nas decisões do scheduler do Autoscaling).
- O runtime inicia o QEMU com a nossa imagem de VM.
- O guest inicializa um OS mínimo com os serviços já instalados.
- Postgres e os serviços de branch de suporte sobem imediatamente (sem downloads).
Ainda há espaço para melhorias. Mas, no momento, acreditamos que <10 segundos é bom o suficiente. O valor da Vela é: “branches aparecem rápido, se comportam de forma consistente e isolam de verdade”.
Isolamento e escalabilidade: por que isso ainda parece Kubernetes
Uma preocupação razoável é: “Se vocês deixaram o KubeVirt e começaram a rodar plumbing customizado de VM, não perderam a ergonomia do Kubernetes?”
Na prática, mantivemos as partes queridas do Kubernetes. Ainda temos controle declarativo via CRDs e controllers que reconciliam o estado desejado. O scheduling continua sendo implementado pelo Kubernetes, com o placement influenciado pelo scheduler e pelo agente do Autoscaling. Restrições de recursos no nível do nó fornecem a base necessária para decisões de placement, scaling e migration com base na capacidade real do nó e no uso real da VM. E, por fim, os limites de isolamento são aplicados fazendo de cada branch de banco de dados a sua própria fronteira de VM.
Tudo isso preservando a possibilidade de live-migrar totalmente um branch da Vela de um worker do Kubernetes para outro sem destruir conexões Postgres já existentes.
Boot rápido também é uma feature de control plane
Mas boot abaixo de 10 segundos não muda apenas a experiência do usuário. Também muda o que você constrói e como você constrói:
- A Vela pode escalar de forma mais agressiva, porque adicionar capacidade é barato, tanto horizontalmente com mais máquinas virtuais quanto verticalmente com live-resizing de limites de VM.
- A Vela pode tratar ambientes como efêmeros, porque o custo de recriação é baixo e storage e compute estão completamente separados.
- A Vela pode absorver falhas substituindo a VM em vez de repará-la.
Esse é o formato de um sistema que eventualmente consegue atender usuários, agentes e workflows de CI sem fazer o usuário esperar.
Lições aprendidas: É sempre mais complicado do que você pensa!
“VMs vs containers” não é o debate; determinismo no boot path é.
Começamos com VMs por bons motivos (maturidade de migração, isolamento forte), mas nossos piores atrasos vinham do nosso próprio amor por conveniência e iteração rápida. O startup do Docker junto com image pulls. No momento em que removemos “puxar imagens no boot”, o tempo até ficar pronto deixou de ser uma aposta.
A reconciliação do Kubernetes é amiga e inimiga.
Se você se pegar “trabalhando ao redor do reconciler”, trate isso como sinal de que está fora do modelo de extensão pretendido, e aproxime-se de padrões suportados ou escolha um substrato que combine melhor com as suas necessidades de controle.
A otimização mais rápida costuma ser remover coisas.
Assim como o código mais rápido é o código que nunca é executado, a otimização mais rápida costuma ser remover componentes desnecessários. No nosso caso, eliminar Docker Compose e image pulls removeu minutos de variabilidade.
Live migration não é uma única feature, mas toda uma superfície de produto.
KubeVirt e Autoscaling abordam migração de formas muito diferentes. Enquanto no KubeVirt quase toda mudança de CPU ou memória termina em live migration, o Autoscaling tenta fazer o máximo possível na instância atual da VM e só migra quando os recursos físicos ficam escassos. A outra grande diferença é uma identidade de rede estável alcançada por meio de uma rede overlay real, em vez de hacks no plano de rede do Kubernetes. Se o seu workload tem formato de banco de dados, o evento “isso foi migrado” precisa ser invisível para os clientes, ou você vai passar a vida lutando contra reconnect storms e tail latency.
Imagens mínimas de sistema operacional não servem apenas para velocidade. Elas reduzem a entropia operacional.
Uma imagem pequena e purpose-built tem menos partes móveis. Isso significa menos interações surpreendentes, menos daemons em segundo plano fazendo coisas “úteis” e uma superfície menor de debug quando algo dá errado. Com o VelaOS, baseado em Buildroot, também conseguimos builds reproduzíveis e a opção de certificar exatamente o que existe dentro da VM a qualquer momento (exceto os dados).
Não tenha medo de se sentir intimidado. Às vezes isso leva a um ótimo resultado.
Quando investigamos construir a nossa própria alternativa ao KubeVirt, a dimensão da tarefa era assustadora. Assustadora o suficiente para nos fazer dedicar tempo a pesquisar outras soluções que talvez já existissem. Isso nos levou ao Autoscaling. E estamos felizes por termos sentido esse medo.
O KubeVirt está fazendo um trabalho importante para o ecossistema Kubernetes.
Sem o KubeVirt dando os primeiros passos para levar máquinas virtuais ao Kubernetes, talvez não estivéssemos aqui hoje. Vale dizer isso explicitamente: o KubeVirt está fazendo um trabalho importante para o ecossistema. Mesmo onde encontramos limitações, o projeto continua evoluindo ativamente. Por exemplo, a própria comunidade do KubeVirt acompanha melhorias em migration targeting e no acoplamento com resize, como se vê em issues como a #15625. E o KubeVirt continua documentando integrações reais, como a execução ao lado do Cluster Autoscaler em ambientes cloud.
Para onde queremos ir em seguida
Não vemos isso como “KubeVirt vs Neon Autoscaling”. Existem várias formas válidas de rodar VMs em Kubernetes, e a melhor escolha depende do formato do seu workload.
O KubeVirt é uma camada de virtualização poderosa e genérica para Kubernetes, e continuamos acompanhando seu progresso de perto.
Mas, para os objetivos principais da Vela, como branches efêmeros e rápidos de banco de dados com isolamento forte, precisávamos de um control plane e de um runtime path assumidamente otimizados para bancos de dados.
O Autoscaling da Neon forneceu a base certa, e o Vela OS tornou o tempo de boot previsível.
Se você está construindo algo nesse espaço, gostaríamos muito de conversar sobre suas experiências, decisões e edge cases adicionais. Especialmente sobre networking, comportamento de migration ou design de imagens de VM.
No futuro próximo, começaremos a upstreamar as melhorias que fizemos. Acreditamos em um ecossistema open source saudável e queremos compartilhar as mudanças em vez de mantê-las privadas.
Se você quiser experimentar e testar nossas instâncias Postgres da Vela, crie sua conta gratuita em https://demo.vela.run. A Vela é totalmente open source e foi pensada para self-hosting no seu próprio data center ou private cloud. Neste momento, estamos limpando o codebase, corrigindo bugs restantes e implementando o procedimento de instalação voltado ao usuário.