
Versão curta: quando uma query está lenta, quase todo mundo pensa primeiro em índices. O PostgreSQL oferece vários: multi-column, partial, expression indexes. O problema é o custo. Mais storage, mais manutenção, mais trabalho na escrita. O que muita gente ignora é CREATE STATISTICS. Extended statistics podem melhorar o planner com um custo de armazenamento quase irrelevante.
Por trás de muitos planos ruins, o problema real não é que o planner “seja burro”. É que ele está tomando decisões racionais com uma imagem errada dos dados. Quando vários predicados estão correlacionados, estatísticas por coluna deixam de bastar. É exatamente aí que entram as extended statistics.
A versão curta
CREATE STATISTICS permite que o Postgres colete informações adicionais que as estatísticas normais por coluna não conseguem representar bem.
Na prática, isso ajuda especialmente em quatro tipos de situação:
- filtros correlacionados em múltiplas colunas,
- estimativas de
DISTINCTmulticoluna, - combinações de valores muito enviesadas,
- expressões para as quais normalmente você pensaria em criar um índice sobre expressão.
–-- Alternative to index on expressions CREATE STATISTICS stats_expr ON (date_trunc(‘day’, created_at)) FROM events; --- What people normally mean by --- extended statistics CREATE STATISTICS stats_multi (dependencies, ndistinct, mcv) ON plan_tier, region, billing_status FROM tenants; |
A primeira forma ajuda em expressões como date_trunc ou extração de JSONB. A segunda é o que a maioria das pessoas imagina quando fala em extended statistics.
Os três tipos mais importantes são dependencies, ndistinct e mcv. E, como nas estatísticas normais, CREATE STATISTICS apenas define o objeto; quem realmente coleta os dados é ANALYZE.
Por que usar extended statistics?
Por padrão, o PostgreSQL armazena principalmente estatísticas por coluna. Isso funciona bem enquanto os filtros podem ser tratados como independentes. O problema começa quando a relação entre colunas importa.
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
Em dados reais, predicados assim frequentemente são correlacionados. Sem estatísticas adicionais, o PostgreSQL se comporta como se cada filtro reduzisse o conjunto de linhas de forma independente. O resultado é uma estimativa matematicamente elegante e operacionalmente absurda.
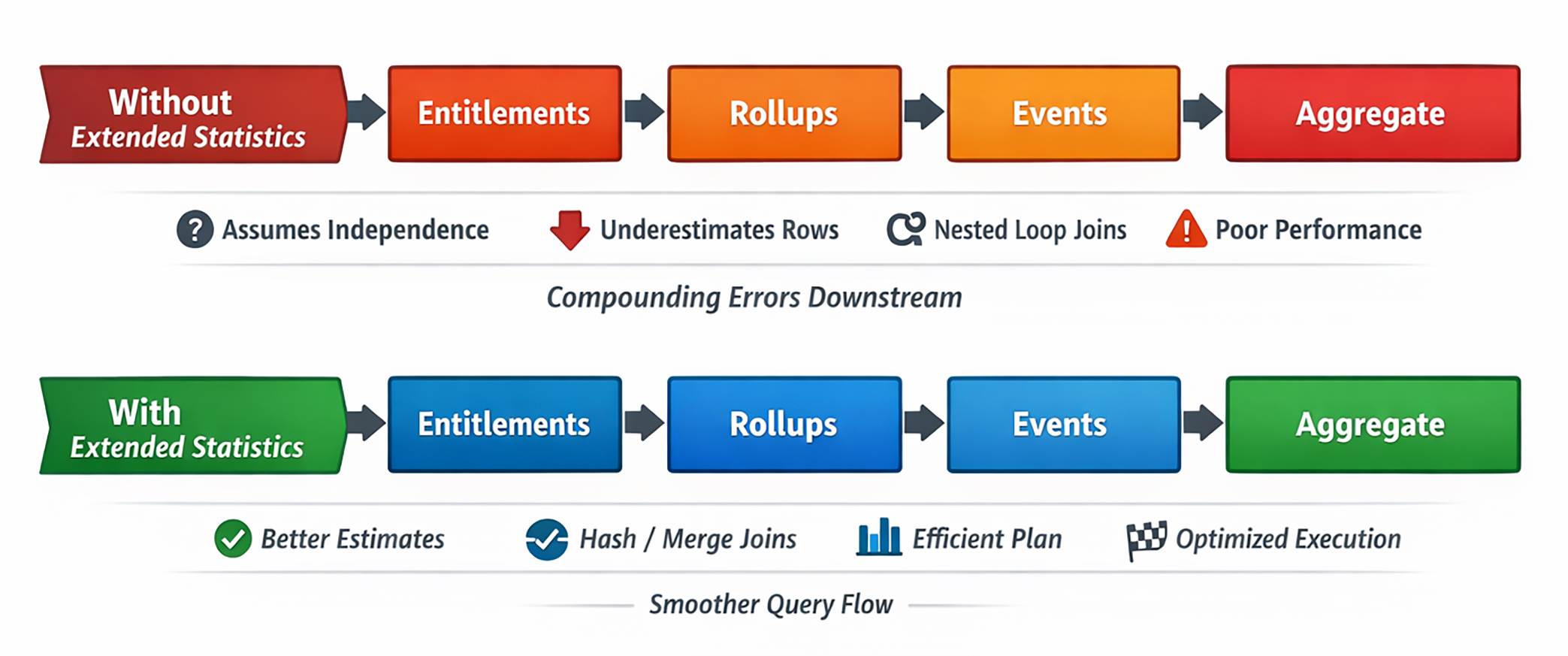
E quando a primeira estimativa está errada, quase tudo depois começa a tremer: ordem de joins, tipo de join, paralelismo, tamanho de hash, estratégia de sort e risco de spill.
O que o Postgres sabe por padrão
A cada ANALYZE, o PostgreSQL grava informações por coluna como fração de nulos, histogramas, valores mais comuns e contagens distintas. Tudo isso é útil, mas ainda é conhecimento local a uma única coluna.
Imagine uma tabela com um milhão de linhas e a seguinte distribuição:
plan_tier = 'enterprise'atinge 6 %region = 'eu-central'atinge 25 %billing_status = 'active'atinge 80 %
1,000,000 * 0.06 * 0.25 * 0.80 = 12,000 rows |
O problema é que essas colunas raramente são independentes no mundo real. A resposta real pode ser 40.000, 60.000 ou 5.000 linhas. Estatísticas por coluna não conseguem dizer isso sozinhas.
Benchmarking de extended statistics
Para tornar isso concreto, construí um workload analítico de SaaS sintético, mas intencionalmente realista, com quatro tabelas: tenants, tenant_entitlements, usage_rollups e analytics_events.
O dataset foi moldado para expor justamente os pontos cegos do planner: correlação entre plano, região e status de cobrança, concentração de entitlements premium e combinações (tenant, feature, day) que não são aleatórias.
É um dataset sintético, sim. Mas sintético no mesmo sentido em que um túnel de vento é sintético: controlado para isolar um fenômeno real.
Isolando o problema pelo formato dos dados
Tabela: tenants
As colunas de segmentação são correlacionadas de uma forma bastante comum em dados reais de SaaS.
Tabela: tenant_entitlements
Features premium como sso, audit_logs e workflows aparecem muito mais em tenants enterprise.
Tabela: usage_rollups
Essa tabela modela um fanout temporal realista por combinação tenant-feature.
Tabela: analytics_events
Aqui está o ponto de explosão de cardinalidade. Para cada combinação tenant-feature que passa pelo filtro, pode haver muitas linhas de eventos crus.
A query de reporting
A pergunta de negócio é simples: “entre os tenants enterprise ativos de uma região importante, quais features premium geraram mais atividade recente?”
SELECT e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.region = 'eu-central' AND t.billing_status = 'active' AND te.entitlement IN ('sso', 'audit_logs') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY e.feature_name ORDER BY rolled_requests DESC; |
Para analisar várias regiões ao mesmo tempo, usamos uma variante ampliada com CTE e agregação final.
WITH regional_feature_totals AS ( SELECT t.region, e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') AND te.entitlement IN ('sso', 'audit_logs', 'workflows') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY t.region, e.feature_name ) SELECT region, feature_name, total_events, rolled_requests FROM ( SELECT region, feature_name, total_events, rolled_requests, row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank FROM regional_feature_totals ) ranked WHERE regional_rank <= 3 ORDER BY region, regional_rank; |
Quebrando o formato da query
Etapa 1: definir o tenant slice
WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') |
Se o PostgreSQL errar essa primeira população, todo o restante do plano passa a se apoiar em uma base errada.
Etapa 2: restringir aos features permitidos
JOIN tenant_entitlements te ON te.tenant_id = t.id ... AND te.entitlements IN (...) |
A tabela de entitlements atua aqui tanto como alvo de join quanto como filtro correlacionado de feature.
Etapa 3: ligar uso recente aos features elegíveis
JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement ... AND r.rollup_day >= CURRENT_DATE - 30 |
Aqui começa a multiplicidade. Um tenant pode ter vários entitlements relevantes, e um par tenant-feature pode ter vários dias recentes de rollup.
Etapa 4: expandir para eventos brutos
JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name ... AND e.event_type IN (...) |
Nesse ponto, uma estimativa ruim já custa caro. Nested loops podem parecer baratos no papel quando não são.
Etapa 5: colapsar a explosão de volta
GROUP BY e.feature_name ORDER BY rolled_requests DESC |
GROUP BY t.region, e.feature_name |
O resultado final é pequeno, mas o trabalho para chegar até ele não é. É justamente isso que faz dessa query uma ótima demonstração do planner.
Etapa 6: ranking na query multi-região
row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank ... --- followed by WHERE regional_rank <= 3 |
Aqui entram mais sort, mais pressão sobre temp I/O e mais complexidade. Ou seja: não é só um problema de joins e agregação, mas também de ranking.
Extended statistics para o resgate
O reflexo mais comum diante desse tipo de problema é adicionar mais índices multi-column, partial ou sobre expressões. Aqui, em vez disso, usamos três objetos estatísticos para corrigir diretamente os pressupostos errados do planner.
- colunas correlacionadas de tenants,
- combinações tenant-entitlement,
- combinações de rollup.
E claro: depois de criar, é preciso rodar ANALYZE.
Tipo: dependencies
Estatísticas de dependência funcional ajudam o PostgreSQL a entender que certas colunas predizem outras de forma forte o suficiente para que tratá-las como independentes seja errado.
- País frequentemente prevê moeda.
- Estado frequentemente prevê fuso horário.
- O segmento do tenant frequentemente prevê famílias de entitlement.
CREATE STATISTICS stats_tl_segment_dependencies (dependencies) ON id, plan_tier, region, billing_status FROM tenants; |
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
Como regra mental: dependencies corrige “esses filtros não são independentes”.
Tipo: mcv
MCV significa “most common values”, mas aqui é mais útil pensar em “most common combinations”.
CREATE STATISTICS stats_tl_segment_mcv (mcv) ON plan_tier, region, billing_status FROM tenants; |
Assim o PostgreSQL aprende que certas combinações são especialmente comuns, especialmente raras ou impossíveis. Como regra mental: mcv corrige “essa combinação específica se comporta diferente da média”.
Tipo: ndistinct
ndistinct diz ao PostgreSQL quantas combinações distintas de várias colunas realmente existem, em vez de conhecer apenas o distinct de cada coluna isoladamente.
CREATE STATISTICS stats_tel_entitlement_ndistinct (ndistinct) ON tenant_id, entitlement FROM tenant_entitlements; CREATE STATISTICS stats_url_feature_ndistinct (ndistinct) ON tenant_id, feature_name, rollup_day FROM usage_rollups; |
Como regra mental: ndistinct corrige “essas combinações de group by ou join não são tão numerosas quanto o planner imagina”.
O que o PostgreSQL armazena
Aqui a coisa fica realmente interessante. Poderíamos tentar resolver tudo com mais índices. Só que índices custam caro para manter e custam caro em storage.
Extended statistics, por outro lado, são surpreendentemente baratas. As definições vivem em pg_statistic_ext e os dados materializados em pg_statistic_ext_data.
pg_statistic_extdiz quais objetos estatísticos existem.pg_statistic_ext_datadiz quais dados foram de fato coletados.
Neste benchmark, o footprint total ficou em cerca de 2.059 bytes:
- Tenant-Segment
mcv: ~1.049 bytes - Tenant-Segment
dependencies: ~518 bytes - Entitlement
ndistinct: ~220 bytes - Rollup
ndistinct: ~272 bytes
Esse é o ponto central: não são índices gigantes “sombra”, e sim pequenos metadados que impedem o planner de alucinar uma distribuição errada.
Corrigindo execution plans
Quando comecei a escrever este post, a minha ideia inicial era provar tempos melhores. Houve melhora, sim, mas o ganho mais importante foi na qualidade das estimativas.
| Scenario | Average Time | Worst Estimate | Additional Storage |
|---|---|---|---|
| Extended statistics | 2,857.896 ms | 48.27x | 2.0 KiB |
| Baseline + Composite Join-Key Indexes | 5,882.659 ms | 106.48x | 37.64 MiB |
| Baseline + Events (feature_name, event_type, tenant_id) | 4,781.551 ms | 108.7x | 31.45 MiB |
| Baseline + Partial Hot-Path Indexes | 4,765.351 ms | 106.22x | 30.20 MiB |
| Extended Statistics + Partial Hot-Path Indexes | 4,876.187 ms | 46.65x | 30.21 MiB |
Cada query foi executada cinco vezes. Os planos completos e os resultados estão no repositório.
Query de região única
O schema base usa índices de coluna única. Isso evita execução totalmente sequencial, mas ainda obriga o planner a estimar a interseção de predicados correlacionados em tenants, entitlements, rollups e events.
| Metric | Value |
|---|---|
| Average execution time | 14,168.174 ms |
| Average planning time | 4.134 ms |
| Execution samples | 31,093.955 ms, 29,065.788 ms, 3,564.811 ms, 3,570.114 ms, 3,546.200 ms |
| Planning samples | 5.058 ms, 3.952 ms, 8.969 ms, 1.899 ms, 0.793 ms |
| Join chain | Nested Loop:Inner -> Nested Loop:Inner -> Nested Loop:Inner |
| Scan nodes | Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Nested Loop: 178,389 estimated / 18,774,720 actual (105.25x) |
| Worst estimate path | Sort -> Aggregate -> Nested Loop |
Com extended statistics, a história melhora bastante:
| Metric | Value |
|---|---|
| Average execution time | 2,857.896 ms |
| Average planning time | 3.025 ms |
| Execution samples | 4,318.854 ms, 2,612.261 ms, 2,396.848 ms, 2,467.702 ms, 2,493.816 ms |
| Planning samples | 6.719 ms, 2.067 ms, 2.128 ms, 2.243 ms, 1.970 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Hash: 12,966 estimated / 625,824 actual (48.27x) |
| Worst estimate path | Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash |
O planner deixa de agir como se os volumes intermediários fossem minúsculos. Um detalhe importante: o custo total estimado sobe. Isso não é regressão; é um sinal de que o PostgreSQL passou a acreditar em um modelo mais realista.
Query multi-região
Na versão multi-região, o ganho de runtime ficou ainda mais evidente.
Baseline:
| Metric | Value |
|---|---|
| Average execution time | 24,933.705 ms |
| Average planning time | 3.648 ms |
| Execution samples | 84,815.859 ms, 12,696.190 ms, 11,819.487 ms, 8,482.936 ms, 6,854.054 ms |
| Planning samples | 6.125 ms, 5.681 ms, 2.067 ms, 2.181 ms, 2.187 ms |
| Join chain | Merge Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Sort: 53,580 estimated / 17,164,496 actual (320.35x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Merge Join -> Sort |
Com extended statistics:
| Metric | Value |
|---|---|
| Average execution time | 7,289.319 ms |
| Average planning time | 2.875 ms |
| Execution samples | 7,503.924 ms, 8,261.715 ms, 7,433.035 ms, 8,181.565 ms, 5,066.357 ms |
| Planning samples | 9.244 ms, 0.932 ms, 1.039 ms, 1.801 ms, 1.359 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Nested Loop: 68,387 estimated / 1,113,566 actual (16.28x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash -> Nested Loop |
Isso não é um ajuste marginal. É o PostgreSQL voltando a operar mais ou menos no mesmo CEP da realidade.
As queries realmente ficaram mais rápidas?
Às vezes sim, às vezes não. É exatamente por isso que o assunto merece cuidado.
Runtime de região única
- Média baseline: 14,168.174 ms
- Média com extended statistics: 2,857.896 ms
Isso parece espetacular, mas o baseline ficou muito distorcido por duas primeiras execuções extremamente lentas. A leitura mais honesta é: o planner passou a entender melhor o problema, e isso se correlacionou com melhor comportamento em regime estável.
Runtime multi-região
- Somente statistics: 7,289.319 ms
- Melhor estratégia apenas com índices: 6,886.473 ms
Isso não enfraquece o caso de CREATE STATISTICS. Apenas o deixa mais preciso: estatísticas melhoram a cardinalidade, índices criam caminhos físicos de acesso.
Por que a comparação com índices importa
Um dos resultados mais interessantes foi que alguns cenários cheios de índices pareciam atraentes em custo ou runtime, mas continuavam muito piores em qualidade de estimativa.
- Extended statistics: cerca de 2.0 KiB
- Alternativas pesadas em índices: cerca de 30.20 MiB a 37.64 MiB

Esse é o ponto subestimado: com cerca de 2 KiB de metadados, o PostgreSQL fica muito menos errado. Já as alternativas baseadas em índices consomem dezenas de MiB extras e muitas vezes nem atacam o problema real do planner.
Por que “usar os dois” não venceu automaticamente
Também testei a pergunta óbvia: extended statistics somadas a índices ideais seriam automaticamente melhores?
Não necessariamente.
Single-region:
- Somente statistics: 2,857.896 ms
- Statistics + Partial Hot-Path Indexes: 4,876.187 ms
Multi-region:
- Somente statistics: 7,289.319 ms
- Statistics + Partial Hot-Path Indexes: 8,950.207 ms
Mais índices não criam apenas novas oportunidades. Eles também mudam o espaço de busca do planner. “Usa os dois e pronto” não é lei da natureza; é mais uma hipótese para benchmark.
Caveats práticos
Existem algumas limitações que vale explicitar:
- Extended statistics só valem dentro de uma única relação.
- O PostgreSQL não as usa diretamente para estimativa de selectivity de joins entre tabelas.
- Nem todo workload se beneficia. Se as colunas forem realmente quase independentes, o ganho pode ser pequeno.
- Elas não substituem bom desenho de query, índices úteis, particionamento, memória bem configurada e storage rápido.
É uma funcionalidade de informação para o planner, não um amuleto universal de performance.
Quando recorrer ao CREATE STATISTICS
A regra prática é simples: se o plano parece errado, e essa “estranheza” está ligada a múltiplas colunas sendo filtradas ou agrupadas juntas de uma forma que o planner modela mal, pense em extended statistics antes de sair criando mais um índice por reflexo.
Bons candidatos incluem:
- colunas de filtro fortemente correlacionadas,
- atributos de dimensão guiados por segmento,
- workloads de group by com cardinalidade claramente errada,
- problemas de fanout multicoluna,
- combinações enviesadas de valores frequentes,
- planos em que uma má estimativa de uma única relação contamina todo o resto.
Piores candidatos incluem problemas de caminho de acesso físico inexistente, workloads claramente dominados por I/O e casos em que as colunas são de fato quase independentes.
Use EXPLAIN (ANALYZE, VERBOSE, BUFFERS). Se estimated rows e actual rows divergem muito, extended statistics merecem um teste sério.
Prefira verdade a truques
A melhor coisa em CREATE STATISTICS é que ela alimenta o planner com mais verdade, em vez de simplesmente empilhar mais estruturas em cima dos dados.
Os benchmarks não dizem “extended statistics sempre vencem”. Eles dizem algo mais útil:
- elas tornaram o PostgreSQL muito menos errado,
- mudaram o formato do plano de forma significativa,
- custaram quase nada em storage,
- e muitas vezes atacaram o problema do planner mais diretamente do que dezenas de MiB em índices extras.
O benchmark, as queries e os resultados estão no GitHub. Você também pode testar tudo na nossa Vela Postgres Sandbox.
E se você já olhou para um plano e pensou “não existe universo em que esse join deveria estar aninhado três vezes dentro de um sobretudo”, existe uma boa chance de que o recurso que você procurava fosse justamente extended statistics.