
Kiedy zaczęliśmy budować Velę, mieliśmy bardzo konkretny i trochę uparty cel: nowe środowisko Postgresa miało być gotowe tak szybko, żeby nie sprawiało wrażenia „provisioningu”. Nie chodziło nam o „szybko jak na boot VM”, tylko po prostu najszybciej jak się da. Na tyle szybko, żeby platform engineerowie mówili o niemal natychmiastowym dostarczeniu, ale nadal z pełną izolacją.
To oznaczało jednak trzy ograniczenia:
- Pełną izolację między bazami danych z twardymi granicami, a nie tylko „izolację na poziomie namespace’u”.
- Pełną odporność na noisy neighbors dzięki twardym limitom CPU, RAM i aktywności dyskowej.
- Skalowalność natywną dla Kubernetes z automatycznym placementem i bezprzerwowym replacementem (live migration).
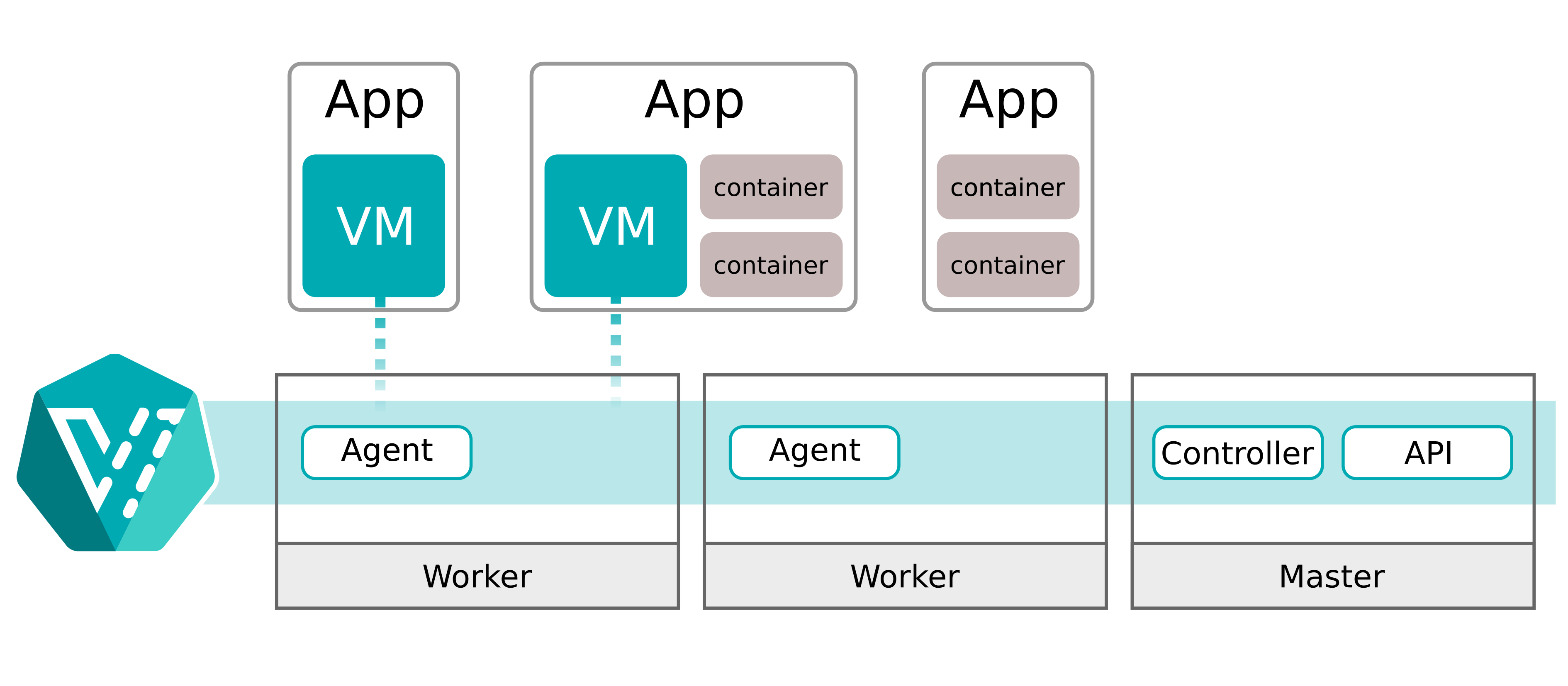
Choć początkowy cel Veli brzmi prosto i oczywiście, okazał się irytująco trudny do osiągnięcia. Każda baza danych (branch) w Veli dostaje silną izolację i możliwość dynamicznego, niezależnego skalowania. Całość ma się zachowywać jak baza danych na Kubernetes, ale z gwarancjami izolacji właściwymi dla maszyny wirtualnej.
Ten wpis to historia tego, jak doszliśmy stamtąd do bootów poniżej 10 sekund, zachowując przy tym pełną izolację między bazami i model skalowania, który działa naturalnie wewnątrz Kubernetes. Po drodze nauczyliśmy się sporo o modelu KubeVirt (i jego ostrych krawędziach), o tym, dlaczego autoscaling VM jest subtelnie inny niż autoscaling podów, oraz dlaczego malutki własny obraz systemu operacyjnego może być większą dźwignią wydajności niż prawie każdy tuning flag.
Dlaczego postawiliśmy na maszyny wirtualne
Na początku wybraliśmy VM-y z jednego pragmatycznego powodu: live migration VM to problem, który jest już rozwiązany. Obsługuje go większość hypervisorów i pod względem dojrzałości nadal wyraźnie wyprzedza live migration kontenerów. Przyglądaliśmy się pracom nad migracją kontenerów (np. zeropod), ale nie pasowały do naszych ograniczeń. Dobrze radziły sobie ze skalowaniem, nawet do zera, ale nie spełniały naszego wymagania nieprzerwanej live migration.
Kubernetes również nie podlegał negocjacji. Dla większości zespołów platformowych Kubernetes jest „substratem”, a wszystko inne ma się zintegrować z jego schedulingiem, observability i operacyjnym lifecyclem.
Zrobiliśmy więc to, co oczywiste: uruchomiliśmy Postgresa wewnątrz VM, które nadal są kontrolowane jako obiekty Kubernetes. KubeVirt jest do tego dokładnie zaprojektowany: rozszerza API Kubernetes o typy VM i uruchamia „payload” VM poprzez pod uruchamiający QEMU/KVM.
Pierwsza próba: KubeVirt, Docker i frustrujące booty
Maszyny wirtualne na Kubernetes? To właśnie KubeVirt. Jak wszyscy, taką odpowiedź mieliśmy i my. Jak trudne to może być?
Nasza pierwsza iteracja startowała w około 2 minuty w dobry dzień i nawet do 5 minut w zły dzień. Wystarczająco instant, prawda? 🫣
Czasy samego bootu VM nie były nawet aż tak złe. Problem polegał na tym, że uruchomienie VM było dopiero początkiem. W środku uruchamialiśmy Dockera (Compose), a potem pobieraliśmy i ładowaliśmy kilka obrazów kontenerów dla każdego brancha, czyli w praktyce komplet usług: Postgresa, PGBouncera, PostgREST i resztę. Throttling Docker Huba oraz „loteria image pulli” okazały się brutalnym źródłem tail latency.
Proces bootu wyglądał tak:
- Kubernetes tworzy zasoby VM KubeVirt
- Zasób VM uruchamia QEMU
- Startuje system gościa
- Usługa Dockera staje się dostępna
- Docker pobiera poszczególne obrazy kontenerów
- Docker uruchamia kontenery jeden po drugim zgodnie z grafem zależności
- Kontenery startują i stają się healthy
- Oznaczamy branch jako aktywny (healthy)
Wiedzieliśmy, że pobieranie obrazów przy każdym uruchomieniu VM nie jest optymalne, ale nie spodziewaliśmy się, że będzie aż tak źle. Główny problem wynika z tego, jak Docker obsługuje pobieranie obrazów i uruchamianie kontenerów. Najpierw ściąga wszystkie obrazy, a dopiero potem uruchamia je zgodnie z grafem zależności. Jeden duży albo wolno pobierający się (z powodu throttlingu) obraz i po wszystkim. Każdy kolejny obraz zwiększa szansę na „zły dzień”.
Ostatecznie zidentyfikowaliśmy trzy elementy wzmacniające latencję, w kolejności od największego wpływu do najmniejszego:
- Image pull i throttling rejestru, potrzebne do udostępnienia obrazów usług brancha.
- Dwupoziomowy start z VM i Dockerowymi kontenerami.
- Dodatkowe kroki setupu, takie jak rejestracja nazwy DNS, provisionowanie nowego dysku, uruchomienie initdb Postgresa i podobne.
Zróbmy pre-cache obrazów Dockera
Najpierw musieliśmy pozbyć się problemu „ciągłego pobierania”. Jeśli twój boot path zawiera „pobierz zależności”, to nie masz czasu bootu. Masz rozkład prawdopodobieństwa.
Budowaliśmy obraz VM, więc dlaczego po prostu nie pobrać wszystkich potrzebnych obrazów kontenerów już w trakcie builda?
Powiedziane, zrobione. Dostosowaliśmy proces builda tak, aby zawierał krok pobierający wszystkie potrzebne obrazy Dockera i pakujący je do finalnego obrazu startowego VM.
To zadziałało świetnie. Największe źródło zmienności czasu bootu zniknęło. Zeszliśmy do dość stabilnej bazy 90-100 sekund. Sporo czasu nadal zajmował boot obrazu Linuxa i czekanie, aż Docker stanie się dostępny, zanim wreszcie mogliśmy uruchomić właściwe usługi brancha. Jak na pierwszy strzał było to wystarczająco dobre. Wiedzieliśmy jednak, że dalej można optymalizować, nie tyle przez uruchamianie typowego obrazu Linuxa, ile przez usprawnienie samej procedury bootu.
Dlaczego Docker?
Jedno z pytań, które wracało, brzmiało: „Dlaczego, do cholery, używaliście Dockera wewnątrz VM?”
Krótka odpowiedź to jedno słowo: wygoda.
Długa odpowiedź brzmi: wygoda szybszych cykli iteracyjnych dzięki używaniu różnych obrazów Dockera i testowaniu różnych potencjalnych opcji usług (takich jak Pgpool-II, PGBouncer i inne).
Potrzebowaliśmy możliwości eksperymentowania bez przebudowywania maszyn wirtualnych, a Docker był wtedy idealnym rozwiązaniem. To miało też bardzo uprościć upgrade’y baz danych. W przypadku dużych upgrade’ów Postgresa potrzebujesz dwóch wersji: nowej i bieżącej. Z Dockerem to był tylko jeden download. Użyć bazowego obrazu nowej wersji, po boocie szybko pobrać starą, wykonać migrację i usunąć stary obraz kontenera. Gotowe.
Niestety, zanim zdążyliśmy wrócić do pozostałych czynników latencji, pojawiły się kolejne problemy.
Kiedy KubeVirt zaczął nas ograniczać
Chcemy to jasno powiedzieć: żaden z poniższych problemów nie sprowadza się po prostu do „KubeVirt jest zły”. W rzeczywistości KubeVirt rozwiązuje bardzo trudny problem i robi to w możliwie najbardziej „kubernetesowy” sposób.
Nasze docelowe zachowanie (szybkie, częste, elastyczne VM-y o „kształcie bazy danych”) obciążało jednak inne części systemu. To nie był typowy „long-lived” VM, który nigdy nie zmienia use case’u. KubeVirt jest świetny, jeśli chcesz wygody Kubernetes i typowego lifecycle’u oraz izolacji maszyny wirtualnej. My natomiast odchodziliśmy od tego wzorca i zaczęło to wychodzić na jaw.
Skalowanie maszyny wirtualnej to nie skalowanie poda
Pierwszym punktem tarcia było to, że skalowanie zasobów VM dla CPU i RAM nie było u nas rzadkim przypadkiem. Chcieliśmy skalować w górę i w dół dynamicznie, tak często i tak szybko, jak to możliwe. Potencjalnie nawet ze scale-to-zero.
W KubeVirt takie zmiany od razu uruchamiają live migration. Nawet jeśli na bieżącym hoście nadal są wystarczające zasoby. Główny ból polega na tym, że live migration zawsze przenosi VM na innego workera Kubernetes. Choć wpływ live migration na wydajność jest ograniczony, ciągłe przemieszczanie maszyn wirtualnych nie wchodziło w grę.
“Current hotplug implementation involves live-migration of the VM workload.” KubeVirt Authors, “Memory Hotplug” documentation (KubeVirt.io)
Dla typowego lifecycle’u VM taka decyzja projektowa ma zdecydowany sens. Dla nas oznaczała jednak, że każdy „resize” zamienia się w „przenoszenie całego świata”, a to pociąga za sobą złożoność sieciową i problemy z utrzymaniem połączeń do bazy.
Potrzebowaliśmy rozwiązania, które live-migruje maszynę tylko wtedy, gdy naprawdę brakuje zasobów, a poza tym pozwala lokalnie skalować CPU i RAM w górę i w dół.
Live migration i sesje TCP to brutalne połączenie
Wpadliśmy też na bardziej brutalną prawdę: live migration jest „bezszwowa” tylko wtedy, gdy stos sieciowy i pipeline migracyjny zachowują te same inwarianty, których oczekuje workload. Klienci Postgresa nie wybaczają długich pauz.
Bazy danych są wrażliwe na latencję i zorientowane na połączenia. Nasze testy wewnętrzne pokazały, że nawet najmniejsze przerwy szybko stają się widoczne podczas długotrwałych testów połączeń. Proponowane rozwiązania, takie jak passt, trochę zmniejszały problem, ale przy średnim i dużym obciążeniu pgbench nadal widzieliśmy zrywanie połączeń.
I wygląda na to, że nie byliśmy sami. KubeVirt ma publiczne issue i dyskusje społeczności dotyczące problemów sieciowych po migracji. Na przykład istnieje długo znany raport, że po migracji może zrywać się łączność na interfejsie masquerade. Inni członkowie społeczności opisywali utratę połączeń, ponieważ podczas migracji zmienia się tożsamość podu/sieci.
Potrzebowaliśmy prawdziwego overlay networkingu.
Podwójne rozliczanie zasobów: Pod kontra VM
Kolejna pułapka: kontrola zasobów odbywa się na wielu warstwach stosu.
- Poziom maszyny wirtualnej to to, co QEMU uważa za dostępne dla VM.
- Poziom poda/Cgroup to to, co Kubernetes narzuca na pod virt-launcher (QEMU).
W naszych eksperymentach okazało się, że przydziały CPU i pamięci muszą być zarządzane skutecznie na poziomie VM i poda. Sama aktualizacja poziomu poda prowadziła do problemów out-of-memory wewnątrz VM. To jest powiązane z opisanym wyżej problemem skalowania.
Aby złagodzić część problemu i umożliwić live resizing, musieliśmy obchodzić KubeVirt i używać libvirt do bezpośredniej aktualizacji VM. Trzeba było uważać, żeby nie zepsuć systemu, bo pojedyncze zdarzenie reconciliacji na zasobie VM KubeVirt unieważniało każdą „ręczną” zmianę.
Potrzebowaliśmy bezpieczniejszego sposobu działania.
Czas ruszyć dalej
Wielokrotnie trafialiśmy na sytuacje, w których potrzebne były workaroundy, które nie mieściły się ładnie w wspieranej powierzchni API, a następna reconciliacja i tak by je cofnęła. Patchowanie KubeVirt oznaczałoby dużo pracy, a my nie chcieliśmy nosić długowiecznego forka tak centralnego projektu tylko po to, by dalej się poruszać.
Zadaliśmy sobie więc pytania:
- „Czy KubeVirt to dobra API wirtualizacji dla Kubernetes?” Tak.
- „Czy KubeVirt to dobra abstrakcja dla naszego lifecycle’u branchy i modelu skalowania?” Uważamy, że nie.
Zrobiliśmy więc to, co robią builderzy open source. Poszukaliśmy innego podejścia, które lepiej odpowiada naszym wymaganiom. Tak naprawdę były tylko dwie opcje: znaleźć lepsze istniejące rozwiązanie albo napisać wszystko od zera, pod konkretny cel.
Nasza pierwsza myśl była taka, żeby zbudować własną abstrakcję bezpośrednio nad libvirt albo QEMU. Ale gdy przyjrzeliśmy się rozmiarowi kodu źródłowego KubeVirt i zaczęliśmy rozpisywać potrzebne funkcje, zrozumieliśmy skalę zadania.
Połączenie maszyny wirtualnej z Kubernetes to ciężka praca. Zbyt wiele pojęć się rozjeżdża i musi zostać ponownie zintegrowanych. To nas przestraszyło. Dlatego postanowiliśmy najpierw poszukać innych rozwiązań. Czegoś bliższego temu, czego potrzebowaliśmy. I mieliśmy szczęście.
Pivot: przejście na Autoscaling od Neona
Lepszym podejściem jest szukanie innego rozwiązania, jeśli możesz znaleźć takie, które lepiej spełnia twoje wymagania. I właśnie to zrobiliśmy.
Podejście było proste i oczywiste, kiedy się nad tym zastanowić. Trzeba spojrzeć na firmy z sąsiedniego obszaru i ich rozwiązania. Na szczęście istnieje wiele baz danych. Wiele z nich jest open source. Wiele jest powiązanych z Postgresem.
Kiedy znaleźliśmy projekt Autoscaling od Neona, zrozumieliśmy też, że nie byliśmy pierwszymi, którzy natknęli się na powyższe ograniczenia. Oni również napotkali wiele tych samych problemów i zdecydowali się napisać własne rozwiązanie. Podejście Neona było bezwstydnie „database-shaped”. Zostało zaprojektowane wokół wertykalnego autoscalingu Postgresa wewnątrz zarządzanych przez K8s mikro-VM (opartych o QEMU). Rozwiązali też najtrudniejszą część: „nie zrywaj sesji TCP, kiedy zmieniasz zasoby albo przenosisz workload”.
Najciekawsza część Autoscalingu to sposób podejmowania decyzji skalujących i sposób działania samego skalowania.
Po pierwsze, Autoscaling wykorzystuje Cgroups do wyznaczania zasobów (CPU i pamięci) na potrzeby raportowania użycia. Aby uchwycić wykorzystanie „hosta” (gościnnej VM), używa metryk zbieranych przez Prometheus. Co kilka sekund bieżące użycie jest oceniane pod kątem potencjalnych zdarzeń scale up lub scale down. Co więcej, agent działający wewnątrz maszyny wirtualnej może proaktywnie prosić o decyzje skalujące, choć takie żądania mogą zostać zawetowane.
Ponieważ Autoscaling używa pod spodem QEMU, CPU i pamięć mogą być hot-plugowane. Oznacza to, że podczas działania rdzenie CPU są dołączane do maszyny wirtualnej lub od niej odłączane w zależności od potrzeb. Z pamięcią działa to podobnie, z wykorzystaniem urządzeń virtio-mem, które można dodawać i usuwać w runtime. Jądro Linuxa przenosi obszary pamięci przeznaczone do usunięcia, aby zwolnić urządzenie virtio-mem przed jego odłączeniem (podobnie jak działa memory ballooning).
“We want to dynamically change the amount of CPUs and memory of running Postgres instances, without breaking TCP connections to Postgres.” Neon Autoscaling README (GitHub)
Komponenty Autoscalingu
Sam Autoscaling to zestaw komponentów współpracujących ze sobą, aby umożliwić serverless Postgresa na Kubernetes.
- Controller (neonvm-controller) zarządzający zasobami maszyn wirtualnych (CRD).
- Scheduler oceniający pojemność węzłów i podejmujący decyzje o placementcie oraz replacementcie VM.
- Agent per-node (daemonset), który zbiera i raportuje użycie zasobów VM.
- VM monitor działający obok workloadu i raportujący użycie przez Prometheus, z konfiguracją specyficzną dla cgroups.
- VXLAN manager, który wraz z Flannel zapewnia stabilną łączność przez wirtualne interfejsy sieciowe i overlay networking.
- Runtime image, który opakowuje VM, udostępnia obraz VM, uruchamia QEMU, obsługuje DHCP/port forwarding i zarządza mountami.
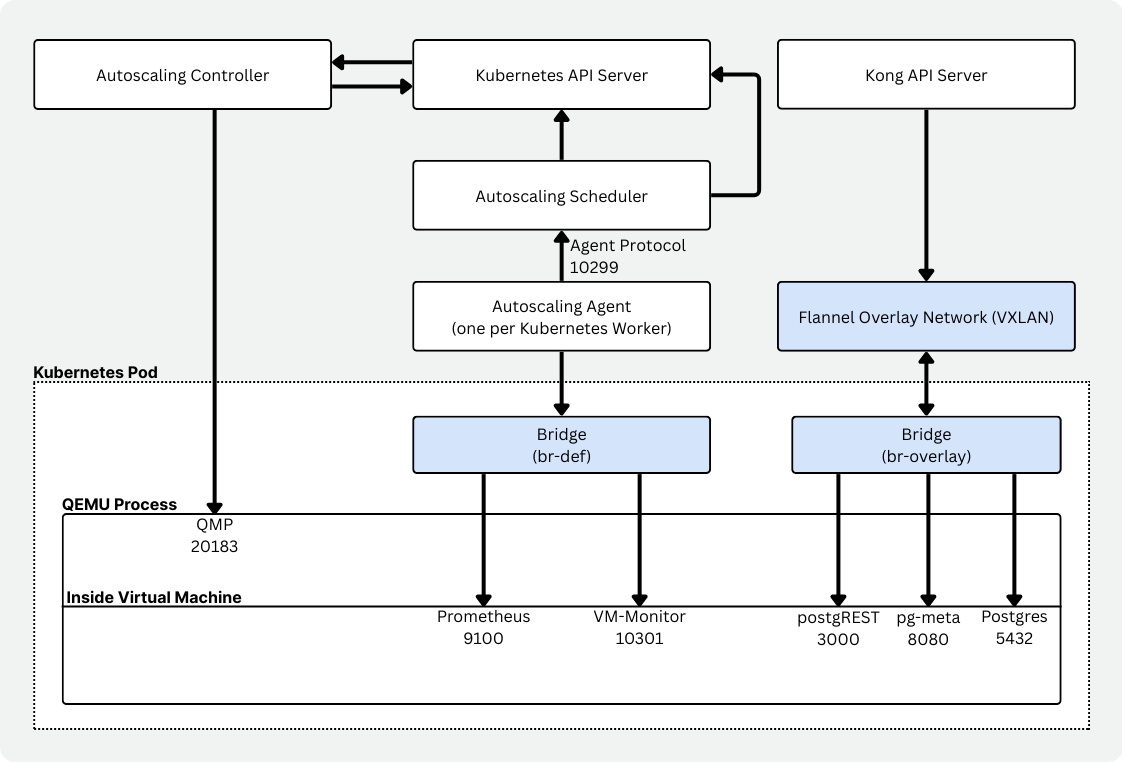
Widać tu ten sam konceptualny podział: własny scheduler, autoscaling-agent na każdym węźle i vm-monitor zdolny reagować natychmiast na presję pamięci. Dla Veli był to dużo lepszy fit.
Dziękujemy zespołowi Neon stojącemu za Autoscalingiem za tę świetną pracę.
Mimo to nadal potrzebne były zmiany
Ale mimo że Autoscaling już trafiał w sedno, nadal były pewne „szorstkie krawędzie” wynikające z różnic między implementacją Neona a Veli.
Po pierwsze, ponieważ simplyblock jest główną warstwą storage, potrzebowaliśmy wsparcia do podpinania jednego lub wielu PVC (Persistent Volume Claims) do maszyny wirtualnej.
Następnie chcieliśmy ograniczyć użycie CPU i RAM bez usuwania możliwości live update limitów. Niestety QEMU musi znać maksymalną wartość CPU i RAM, którą można dołączyć w dowolnym momencie. Potrzebowaliśmy, aby te wartości były dużo wyższe niż to, do czego realnie spodziewamy się skalowania. Dlatego rozszerzyliśmy proces decyzyjny o soft limit. Obecne VM mają hard limit 128 vCPU i 256 GB pamięci. Soft limit opisuje natomiast bieżące maksymalne współczynniki skali, np. 8 vCPU albo 16 GB pamięci. Żądania przekraczające soft limit są odrzucane.
Na koniec dodaliśmy prosty PowerState, który pozwala nam uruchamiać i zatrzymywać VM przez zwykłą zmianę wartości w CRD. Czysta wygoda.
Wygrana na czasie bootu: zabicie „Dockera w VM”
Gdy Autoscaling rozwiązał dużą część tarcia związanego z lifecyclem i skalowaniem, wróciliśmy do prawdziwego problemu: czasu bootu. Prawdziwy przełom przyszedł, kiedy uczciwie spojrzeliśmy na to, co robiliśmy. To było po prostu głupie. Wybraliśmy naszą wygodę ponad doświadczenie użytkownika. Bootowaliśmy ogólną dystrybucję Linuksa, potem Dockera, a następnie orkiestrację wielu usług przez obrazy kontenerów. Usunęliśmy więc całą wewnętrzną warstwę kontenerową.
VelaOS: własny kernel Linuxa i rootfs na bazie Buildroot
Przeszliśmy na własny obraz Linuksa oparty o Buildroot. Buildroot to framework do budowy kerneli Linuxa i minimalnego root filesystemu. Pierwotnie zaprojektowany dla urządzeń embedded, wspiera obrazy tylko do odczytu, aktualizatory urządzeń i inne elementy.
Nawet jeśli wcześniej nie słyszałeś o samym Buildroot, to w praktyce jest to szeroko używany system. Bardziej znani użytkownicy to OpenWRT, Home Assistant OS (HAOS) oraz producenci urządzeń embedded, jak Google Fiber. Buildroot jest znany z bardzo małych root filesystemów.
Przejście na Buildroot dało nam kilka szybkich wygranych poza samym pozbyciem się Dockera:
- Proces bootu stał się deterministyczny dzięki użyciu inittab jako bazowego systemu init do precyzyjnego kontrolowania, co i kiedy się uruchamia.
- Koniec z Docker pullami, ponieważ wszystkie usługi są zintegrowane z obrazem bootowym.
- Większa szybkość bootu, bo nie używamy ogólnego obrazu systemu operacyjnego, tylko zoptymalizowanego kernela Linuxa.
- Reproducible builds, ponieważ każdy komponent jest przypięty do konkretnej wersji lub commita i checksumy, co zapewnia budowanie wyłącznie niezmienionych komponentów.
Z drugiej strony straciliśmy trochę velocity. Buildroot jako framework buduje większość komponentów finalnego obrazu samodzielnie. Dzięki temu może osiągać bardzo małe obrazy dyskowe, ale kosztem czasu builda. Na szczęście dzięki CCache i innym technikom optymalizacji nadal dało się tym rozsądnie zarządzać.
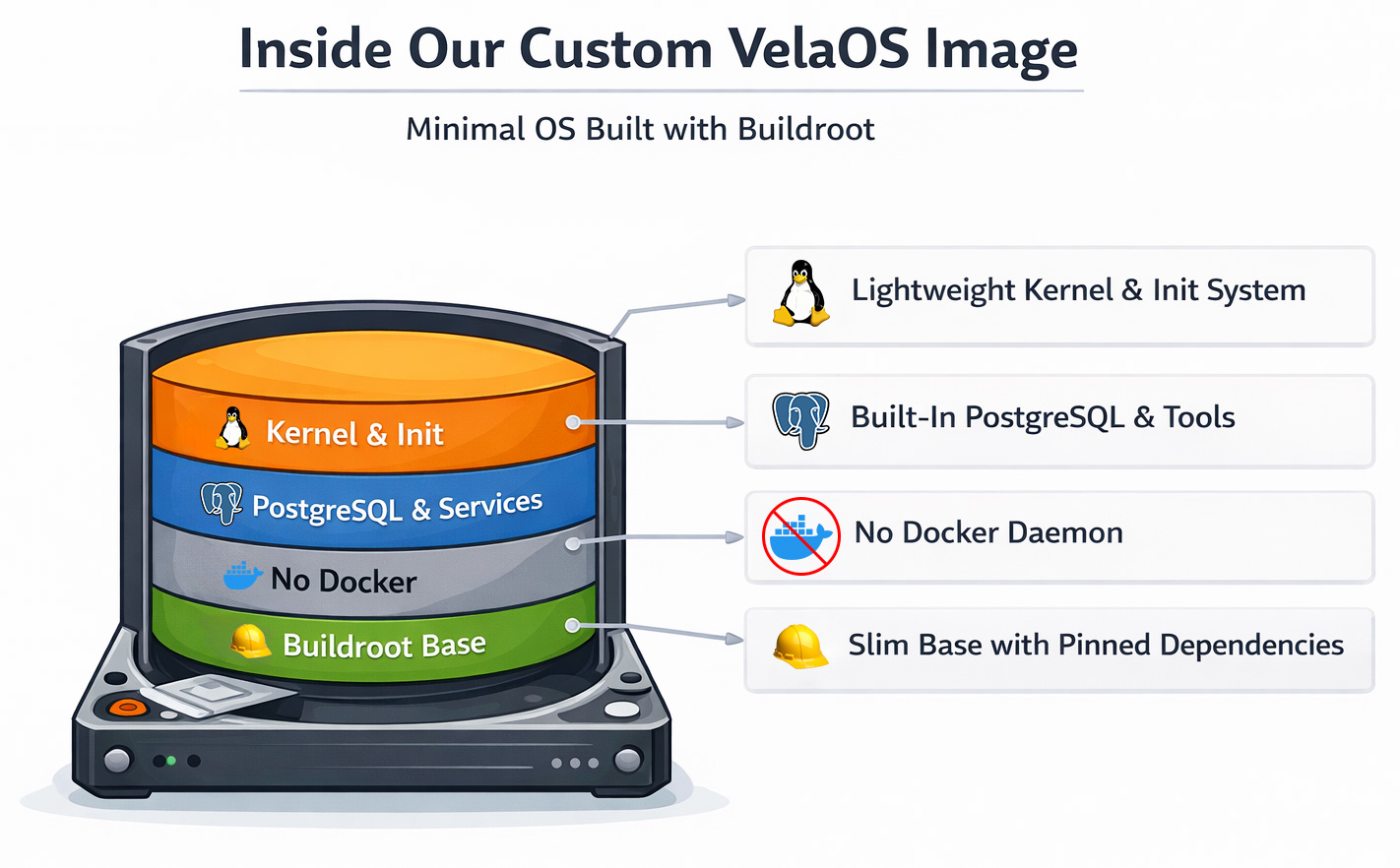
Powstała ścieżka bootu jest prosta:
- Kubernetes schedule’uje pod VM zgodnie z decyzjami schedulera Autoscalingu.
- Runtime uruchamia QEMU z naszym obrazem VM.
- Gość bootuje minimalny OS z już zainstalowanymi usługami.
- Postgres i usługi wspierające branch wstają natychmiast (bez downloadów).
Nadal jest miejsce na ulepszenia. Ale na ten moment uważamy, że <10 sekund jest wystarczająco dobre. Wartość Veli polega na tym, że „branche pojawiają się szybko, zachowują się spójnie i izolują naprawdę mocno”.
Izolacja i skalowalność: dlaczego to nadal czuje się jak Kubernetes
Naturalna obawa brzmi: „Skoro porzuciliście KubeVirt i zaczęliście uruchamiać własną VM plumbing, to czy nie straciliście ergonomii Kubernetes?”
W praktyce zachowaliśmy te części Kubernetes, które wszyscy lubią. Nadal mamy deklaratywną kontrolę przez CRD i controllery, które reconcilują desired state. Scheduling jest realizowany przez Kubernetes, a placement jest dodatkowo wpływany przez scheduler i agenta Autoscalingu. Ograniczenia zasobów na poziomie node’ów dostarczają podstaw do decyzji o placementcie, skalowaniu i migracji na bazie rzeczywistej pojemności węzła i faktycznego użycia VM. A na końcu granice izolacji są egzekwowane przez to, że każdy branch bazy danych ma własną granicę VM.
Wszystko to przy zachowaniu możliwości pełnej live migration brancha Veli z jednego workera Kubernetes na innego, bez niszczenia istniejących połączeń Postgresa.
Szybki boot to także cecha control plane’u
Boot time poniżej 10 sekund nie poprawia tylko doświadczenia użytkownika. Zmienia też to, co i jak budujesz:
- Vela może skalować się bardziej agresywnie, ponieważ dodawanie pojemności jest tanie, zarówno poziomo przez kolejne maszyny wirtualne, jak i pionowo przez live-resizing limitów VM.
- Vela może traktować środowiska jako efemeryczne, ponieważ koszt ich odtworzenia jest niski, a storage i compute są całkowicie rozdzielone.
- Vela może absorbować awarie przez replacement VM zamiast jej naprawy.
Taki kształt ma system, który docelowo może obsługiwać użytkowników, agentów i workflow CI bez zmuszania użytkownika do czekania.
Wnioski: Zawsze jest bardziej skomplikowane, niż myślisz!
Debatą nie jest „VM kontra kontenery”, tylko deterministyczny boot path.
Zaczęliśmy od VM z dobrych powodów (dojrzałość migracji, silna izolacja), ale nasze największe opóźnienia wynikały z naszej własnej miłości do wygody i szybkiej iteracji. Start Dockera plus image pulle. W momencie, gdy usunęliśmy „ciągnij obrazy przy boocie”, czas do gotowości przestał być loterią.
Reconciliation Kubernetes jest przyjacielem i wrogiem jednocześnie.
Jeśli łapiesz się na „pracowaniu wokół reconcilerów”, potraktuj to jako sygnał, że jesteś poza zamierzonym modelem rozszerzania, i albo wróć bliżej wspieranych wzorców, albo wybierz substrat lepiej dopasowany do twoich potrzeb kontroli.
Najszybsza optymalizacja polega najczęściej na usunięciu czegoś.
Tak jak najszybszy kod to ten, który nigdy się nie wykonuje, tak najszybsza optymalizacja to usunięcie zbędnych komponentów. W naszym przypadku całkowite wyeliminowanie Docker Compose i image pulli usunęło minuty zmienności.
Live migration nie jest jedną funkcją, ale całą powierzchnią produktu.
KubeVirt i Autoscaling podchodzą do migracji bardzo różnie. W KubeVirt prawie każda zmiana CPU lub pamięci kończy się live migration, podczas gdy Autoscaling stara się zrobić jak najwięcej na istniejącej instancji VM i migruje dopiero wtedy, gdy zaczyna brakować fizycznych zasobów. Drugą dużą różnicą jest stabilna tożsamość sieciowa osiągnięta dzięki prawdziwej sieci overlay, a nie hackom na plane’ie sieciowym Kubernetes. Jeśli twój workload ma charakter bazy danych, zdarzenie „to zostało zmigrowane” musi być niewidoczne dla klientów, inaczej całe życie spędzisz walcząc z reconnect stormami i tail latency.
Minimalne obrazy systemowe nie dają tylko szybkości. Zmniejszają też operacyjną entropię.
Mały, purpose-built obraz ma mniej ruchomych części. To oznacza mniej zaskakujących interakcji, mniej demonów w tle robiących „pomocne” rzeczy i mniejszą powierzchnię debugowania, gdy coś pójdzie źle. Dzięki VelaOS opartemu o Buildroot osiągnęliśmy też reproducible builds i możliwość dokładnego określenia, co znajduje się wewnątrz VM w danym momencie (poza danymi).
Nie bój się tego, że się boisz. Czasem prowadzi to do świetnych rezultatów.
Kiedy badaliśmy możliwość zbudowania własnej alternatywy dla KubeVirt, skala zadania była przerażająca. Na tyle, że poświęciliśmy czas na szukanie innych, już istniejących rozwiązań. To doprowadziło nas do Autoscalingu. I cieszymy się, że ten strach mieliśmy.
KubeVirt robi ważną robotę dla ekosystemu Kubernetes.
Gdyby KubeVirt nie wykonał pierwszych kroków w przeniesieniu maszyn wirtualnych do Kubernetes, być może nie byłoby nas dziś tutaj. Warto powiedzieć to wprost: KubeVirt wykonuje ważną pracę dla całego ekosystemu. Nawet tam, gdzie natrafiliśmy na ograniczenia, projekt aktywnie się rozwija. Na przykład sama społeczność KubeVirt śledzi usprawnienia dotyczące migration targetingu i powiązania resize z migracją, co widać w issue takich jak #15625. KubeVirt nadal dokumentuje też realne integracje, jak współpraca z Cluster Autoscalerem w środowiskach chmurowych.
Dokąd chcemy pójść dalej
Nie widzimy tego jako „KubeVirt vs Neon Autoscaling”. Istnieje wiele poprawnych sposobów uruchamiania VM na Kubernetes, a najlepszy wybór zależy od kształtu workloadu.
KubeVirt jest potężną, ogólną warstwą wirtualizacji dla Kubernetes i nadal uważnie śledzimy jego rozwój.
Jednak dla głównych celów Veli, takich jak szybkie, efemeryczne branche bazodanowe z silną izolacją, potrzebowaliśmy control plane’u i ścieżki runtime bezkompromisowo zoptymalizowanych pod bazy danych.
Autoscaling od Neona dał nam właściwy fundament, a Vela OS uczynił czas bootu przewidywalnym.
Jeśli budujesz coś w tej przestrzeni, chętnie porozmawiamy o twoich doświadczeniach, decyzjach i dodatkowych edge case’ach. Szczególnie wokół networkingu, zachowania migracji albo projektowania obrazów VM.
W niedalekiej przyszłości zaczniemy upstreamować wprowadzone przez nas ulepszenia. Wierzymy w zdrowy ekosystem open source i chcemy dzielić się zmianami zamiast trzymać je prywatnie.
Jeśli chcesz przetestować nasze instancje Vela Postgres, załóż darmowe konto na https://demo.vela.run. Vela jest w pełni open source i przeznaczona do self-hostingu we własnym data center lub private cloudzie. W tej chwili czyścimy codebase, poprawiamy pozostałe bugi i wdrażamy procedurę instalacji po stronie użytkownika.