
Krótka wersja: gdy zapytania są wolne, większość ludzi najpierw myśli o indeksach. PostgreSQL ma ich sporo: multi-column, partial, expression indexes. Problem w tym, że każdy dodatkowy indeks kosztuje storage, zapis i utrzymanie. Tymczasem wiele osób ignoruje CREATE STATISTICS. Extended statistics potrafią poprawić plan przy niemal zerowym koszcie pamięci.
W wielu złych planach prawdziwy problem nie polega na tym, że planner jest leniwy. Problem polega na tym, że pracuje na złym obrazie danych. Gdy kilka predykatów jest skorelowanych, statystyki per kolumna przestają wystarczać. I właśnie tu wchodzą extended statistics.
Krótka wersja
CREATE STATISTICS pozwala Postgresowi zebrać dodatkowe informacje, których zwykłe statystyki kolumnowe nie potrafią dobrze oddać.
W praktyce pomaga to szczególnie w czterech sytuacjach:
- skorelowane filtry na wielu kolumnach,
- wielokolumnowe estymacje
DISTINCT, - mocno skośne kombinacje wartości,
- wyrażenia, dla których normalnie kusiłby nas expression index.
–-- Alternative to index on expressions CREATE STATISTICS stats_expr ON (date_trunc(‘day’, created_at)) FROM events; --- What people normally mean by --- extended statistics CREATE STATISTICS stats_multi (dependencies, ndistinct, mcv) ON plan_tier, region, billing_status FROM tenants; |
Pierwsza forma przydaje się np. dla date_trunc albo ekstrakcji JSONB. Druga to właśnie to, co większość ludzi ma na myśli, mówiąc o extended statistics.
Najważniejsze typy to dependencies, ndistinct i mcv. I jak zwykle, CREATE STATISTICS tylko definiuje obiekt, a ANALYZE dopiero zbiera dane.
Dlaczego extended statistics?
Domyślnie PostgreSQL przechowuje przede wszystkim statystyki per kolumna. To działa dobrze, gdy filtry można traktować niezależnie. Problem zaczyna się wtedy, gdy zależności między kolumnami są istotne.
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
W realnych danych takie predykaty są często skorelowane. Bez dodatkowych statystyk PostgreSQL zachowuje się jednak tak, jakby każda klauzula niezależnie zmniejszała zbiór wynikowy. Skutek: matematycznie schludne, operacyjnie absurdalne estymacje.
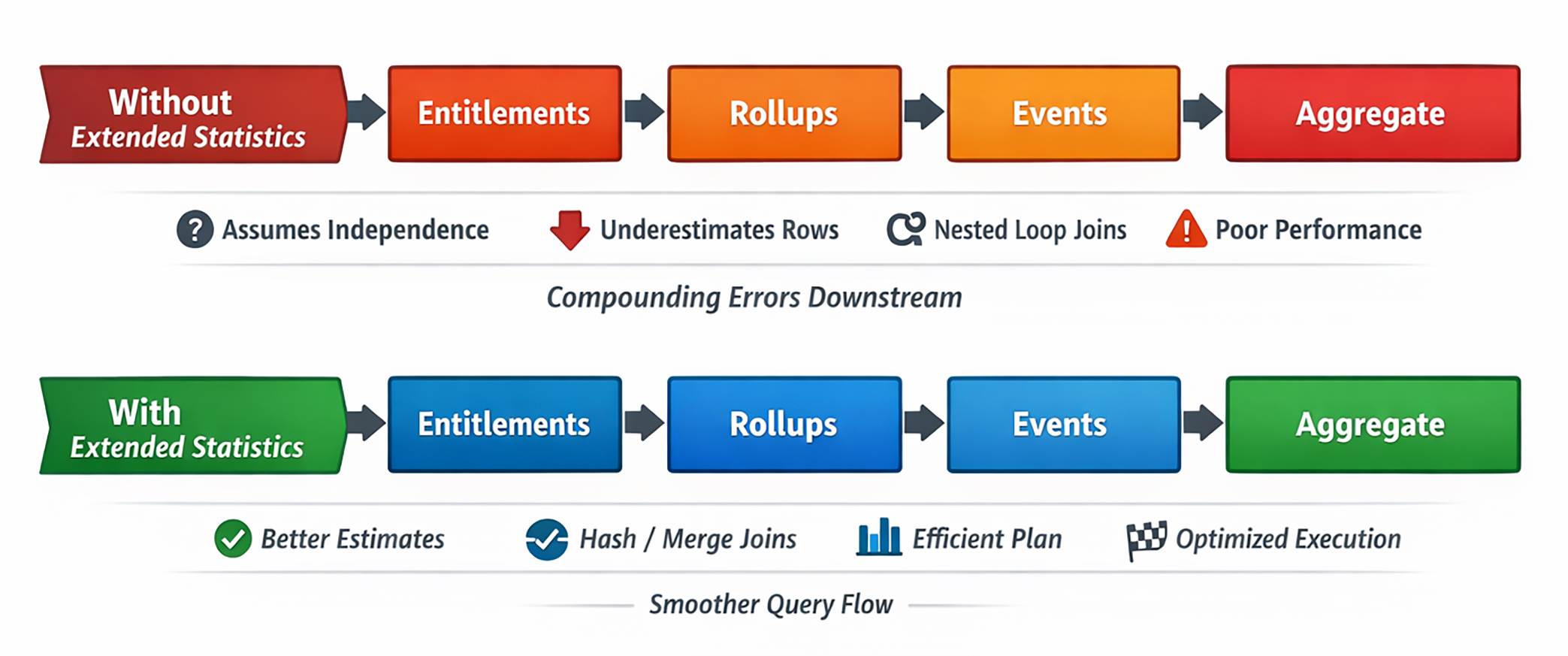
A kiedy pierwsza estymacja jest zła, wszystko dalej zaczyna się chwiać: kolejność joinów, metoda joina, paralelizm, rozmiary hashy, strategia sortowania i ryzyko spillu.
Co Postgres wie domyślnie
Przy każdym ANALYZE PostgreSQL zapisuje dla każdej kolumny takie informacje jak udział nulli, histogramy, częste wartości czy liczby distinct. To bardzo przydatne, ale nadal tylko wiedza lokalna dla pojedynczej kolumny.
Załóżmy tabelę z milionem wierszy i taki rozkład:
plan_tier = 'enterprise'trafia w 6 %region = 'eu-central'trafia w 25 %billing_status = 'active'trafia w 80 %
1,000,000 * 0.06 * 0.25 * 0.80 = 12,000 rows |
Problem polega na tym, że w realnym świecie te kolumny rzadko są niezależne. Prawdziwa odpowiedź może wynosić 40 000, 60 000 albo 5 000 wierszy. Zwykłe statystyki kolumnowe nie potrafią tego uchwycić.
Benchmark extended statistics
Żeby to pokazać konkretnie, zbudowałem syntetyczny, ale celowo realistyczny workload analityczny typu SaaS z czterema tabelami: tenants, tenant_entitlements, usage_rollups i analytics_events.
Dane zostały ukształtowane tak, by odsłonić ślepe punkty plannera: korelacje między planem, regionem i statusem billingowym, koncentrację premium entitlements i nierandomowe kombinacje (tenant, feature, day).
To dane syntetyczne, ale syntetyczne w tym samym sensie co tunel aerodynamiczny: kontrolowane po to, by wyizolować realne zjawisko.
Izolowanie problemu przez kształt danych
Tabela: tenants
Kolumny segmentujące są skorelowane w sposób typowy dla realnych danych SaaS.
Tabela: tenant_entitlements
Premium features jak sso, audit_logs czy workflows są częściej skupione po stronie enterprise tenantów.
Tabela: usage_rollups
Ta tabela modeluje realistyczny fanout czasowy dla kombinacji tenant-feature.
Tabela: analytics_events
To tu następuje eksplozja kardynalności. Na każdą pasującą kombinację tenant-feature może przypadać wiele surowych zdarzeń.
Zapytanie raportowe
Pytanie biznesowe brzmi prosto: „które premium features generują najwięcej ostatniej aktywności wśród aktywnych enterprise tenantów w ważnym regionie?”
SELECT e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.region = 'eu-central' AND t.billing_status = 'active' AND te.entitlement IN ('sso', 'audit_logs') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY e.feature_name ORDER BY rolled_requests DESC; |
Dla wielu regionów mamy też nieco rozszerzoną wersję z CTE i końcową agregacją.
WITH regional_feature_totals AS ( SELECT t.region, e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') AND te.entitlement IN ('sso', 'audit_logs', 'workflows') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY t.region, e.feature_name ) SELECT region, feature_name, total_events, rolled_requests FROM ( SELECT region, feature_name, total_events, rolled_requests, row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank FROM regional_feature_totals ) ranked WHERE regional_rank <= 3 ORDER BY region, regional_rank; |
Rozbijmy kształt tej kwerendy
Etap 1: zdefiniowanie tenant slice
WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') |
Jeśli PostgreSQL pomyli się już tutaj, to cały dalszy plan opiera się na złej populacji wejściowej.
Etap 2: ograniczenie do dozwolonych features
JOIN tenant_entitlements te ON te.tenant_id = t.id ... AND te.entitlements IN (...) |
Tabela entitlementów działa tu jednocześnie jako cel joina i skorelowany filtr feature’ów.
Etap 3: związanie ostatniego usage z dozwolonymi features
JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement ... AND r.rollup_day >= CURRENT_DATE - 30 |
W tym miejscu zaczyna się mnożenie. Jeden tenant może mieć wiele pasujących entitlementów, a jedna kombinacja tenant-feature może mieć wiele ostatnich dni rollupów.
Etap 4: rozszerzenie do raw events
JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name ... AND e.event_type IN (...) |
Na tym etapie złe estymacje zaczynają naprawdę boleć. Nested Loops mogą wyglądać tanio tylko na papierze.
Etap 5: ponowne zwinięcie eksplozji do małego wyniku
GROUP BY e.feature_name ORDER BY rolled_requests DESC |
GROUP BY t.region, e.feature_name |
Końcowy wynik jest mały, ale droga do niego wcale nie jest mała. To właśnie czyni tę kwerendę świetną demonstracją plannera.
Etap 6: ranking w wersji multi-region
row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank ... --- followed by WHERE regional_rank <= 3 |
Tu dochodzą dodatkowe sorty i większa presja na temp I/O. To już nie tylko problem joinów i agregacji, ale również rankingu.
Extended statistics na ratunek
Naturalnym odruchem przy takich problemach jest dorzucenie kolejnych indeksów multi-column, partial albo expression. Tutaj zamiast tego tworzymy trzy obiekty statystyczne, które uderzają w podstawowe błędne założenia plannera.
- skorelowane kolumny tenantów,
- kombinacje tenant-entitlement,
- kombinacje rollupów.
Po utworzeniu oczywiście trzeba uruchomić ANALYZE.
Typ: dependencies
Statystyki zależności funkcyjnych pomagają PostgreSQL zrozumieć, że pewne kolumny przewidują inne na tyle silnie, że założenie niezależności jest błędne.
- Kraj często silnie przewiduje walutę.
- Stan silnie przewiduje strefę czasową.
- Segment tenantów silnie przewiduje rodziny entitlementów.
CREATE STATISTICS stats_tl_segment_dependencies (dependencies) ON id, plan_tier, region, billing_status FROM tenants; |
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
Prosty skrót myślowy: dependencies naprawia „te filtry nie są niezależne”.
Typ: mcv
MCV oznacza „most common values”, ale przy extended statistics lepiej myśleć o tym jako o „najczęstszych kombinacjach”.
CREATE STATISTICS stats_tl_segment_mcv (mcv) ON plan_tier, region, billing_status FROM tenants; |
Dzięki temu PostgreSQL uczy się, że pewne kombinacje są wyjątkowo częste, wyjątkowo rzadkie albo wręcz niemożliwe. Skrót myślowy: mcv naprawia „ta konkretna kombinacja zachowuje się inaczej niż średnia”.
Typ: ndistinct
ndistinct mówi PostgreSQL-owi, ile różnych kombinacji wielu kolumn rzeczywiście istnieje, zamiast znać tylko distinct dla każdej kolumny osobno.
CREATE STATISTICS stats_tel_entitlement_ndistinct (ndistinct) ON tenant_id, entitlement FROM tenant_entitlements; CREATE STATISTICS stats_url_feature_ndistinct (ndistinct) ON tenant_id, feature_name, rollup_day FROM usage_rollups; |
Prosty skrót: ndistinct naprawia „tych kombinacji group-by albo joinów nie ma aż tyle, ile planner myśli”.
Co PostgreSQL faktycznie przechowuje
Tu robi się naprawdę ciekawie. Wszystkie opisane wyżej problemy można by też próbować rozwiązywać dodatkowymi indeksami. Tyle że indeksy są drogie zarówno w utrzymaniu, jak i w storage.
Extended statistics są z kolei bardzo tanie. Ich definicje żyją w pg_statistic_ext, a zebrane dane w pg_statistic_ext_data.
pg_statistic_extmówi, jakie obiekty statystyczne istnieją.pg_statistic_ext_datamówi, jakie dane naprawdę zostały zebrane.
W tym benchmarku całkowity footprint obiektów statystycznych wyniósł około 2 059 bajtów:
- Tenant-Segment
mcv: ~1 049 bajtów - Tenant-Segment
dependencies: ~518 bajtów - Entitlement
ndistinct: ~220 bajtów - Rollup
ndistinct: ~272 bajty
I o to właśnie chodzi: to nie są wielkie „cienie indeksów”, tylko małe metadane, które sprawiają, że planner mniej się myli.
Naprawianie execution plans
Kiedy zaczynałem pisać ten tekst, chciałem przede wszystkim pokazać lepsze czasy wykonania. Owszem, poprawiły się. Ale dużo ważniejsze okazało się to, że poprawiły się estymacje.
| Scenario | Average Time | Worst Estimate | Additional Storage |
|---|---|---|---|
| Extended statistics | 2,857.896 ms | 48.27x | 2.0 KiB |
| Baseline + Composite Join-Key Indexes | 5,882.659 ms | 106.48x | 37.64 MiB |
| Baseline + Events (feature_name, event_type, tenant_id) | 4,781.551 ms | 108.7x | 31.45 MiB |
| Baseline + Partial Hot-Path Indexes | 4,765.351 ms | 106.22x | 30.20 MiB |
| Extended Statistics + Partial Hot-Path Indexes | 4,876.187 ms | 46.65x | 30.21 MiB |
Każde zapytanie uruchomiono pięć razy. Pełne plany i wyniki znajdują się w repozytorium.
Zapytanie dla jednego regionu
Schema bazowe używa indeksów pojedynczych kolumn. To pozwala uniknąć pełnego skanu sekwencyjnego, ale planner nadal musi zgadywać przecięcia skorelowanych predykatów na tenants, entitlements, rollups i events.
| Metric | Value |
|---|---|
| Average execution time | 14,168.174 ms |
| Average planning time | 4.134 ms |
| Execution samples | 31,093.955 ms, 29,065.788 ms, 3,564.811 ms, 3,570.114 ms, 3,546.200 ms |
| Planning samples | 5.058 ms, 3.952 ms, 8.969 ms, 1.899 ms, 0.793 ms |
| Join chain | Nested Loop:Inner -> Nested Loop:Inner -> Nested Loop:Inner |
| Scan nodes | Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Nested Loop: 178,389 estimated / 18,774,720 actual (105.25x) |
| Worst estimate path | Sort -> Aggregate -> Nested Loop |
Z extended statistics wygląda to dużo lepiej:
| Metric | Value |
|---|---|
| Average execution time | 2,857.896 ms |
| Average planning time | 3.025 ms |
| Execution samples | 4,318.854 ms, 2,612.261 ms, 2,396.848 ms, 2,467.702 ms, 2,493.816 ms |
| Planning samples | 6.719 ms, 2.067 ms, 2.128 ms, 2.243 ms, 1.970 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Hash: 12,966 estimated / 625,824 actual (48.27x) |
| Worst estimate path | Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash |
Planner przestaje zachowywać się tak, jakby wolumeny pośrednie były malutkie. Ważna subtelność: szacowany koszt całkowity rośnie. To nie regresja, tylko sygnał, że PostgreSQL wreszcie uwierzył w bardziej realistyczny model danych.
Zapytanie multi-region
W wersji multi-region różnica w czasie wykonania jest jeszcze bardziej widoczna.
Baseline:
| Metric | Value |
|---|---|
| Average execution time | 24,933.705 ms |
| Average planning time | 3.648 ms |
| Execution samples | 84,815.859 ms, 12,696.190 ms, 11,819.487 ms, 8,482.936 ms, 6,854.054 ms |
| Planning samples | 6.125 ms, 5.681 ms, 2.067 ms, 2.181 ms, 2.187 ms |
| Join chain | Merge Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Sort: 53,580 estimated / 17,164,496 actual (320.35x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Merge Join -> Sort |
Z extended statistics:
| Metric | Value |
|---|---|
| Average execution time | 7,289.319 ms |
| Average planning time | 2.875 ms |
| Execution samples | 7,503.924 ms, 8,261.715 ms, 7,433.035 ms, 8,181.565 ms, 5,066.357 ms |
| Planning samples | 9.244 ms, 0.932 ms, 1.039 ms, 1.801 ms, 1.359 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Nested Loop: 68,387 estimated / 1,113,566 actual (16.28x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash -> Nested Loop |
To nie jest drobny tuning. To jest PostgreSQL wracający mniej więcej do tego samego kodu pocztowego co rzeczywistość.
Czy zapytania faktycznie przyspieszyły?
Czasem tak, czasem nie. Właśnie dlatego warto podchodzić do tego tematu ostrożnie.
Runtime dla jednego regionu
- Średnia baseline: 14,168.174 ms
- Średnia z extended statistics: 2,857.896 ms
Na pierwszy rzut oka wygląda to spektakularnie, ale baseline jest mocno zaburzony przez dwa ekstremalnie wolne pierwsze uruchomienia. Ostrożniejsza teza brzmi więc: lepsza wiedza plannera przełożyła się tu na lepsze zachowanie w stanie ustalonym.
Runtime multi-region
- Tylko statistics: 7,289.319 ms
- Najlepsza strategia tylko z indeksami: 6,886.473 ms
To nie osłabia argumentu za CREATE STATISTICS. Po prostu go doprecyzowuje. Statystyki poprawiają estymacje, a indeksy tworzą fizyczne ścieżki dostępu.
Dlaczego porównanie z indeksami ma znaczenie
Jednym z ciekawszych wyników było to, że scenariusze bogate w indeksy potrafiły wyglądać atrakcyjnie pod względem kosztu czy runtime, a jednocześnie pozostawały znacznie gorsze pod względem jakości estymacji.
- Extended statistics: około 2.0 KiB
- Alternatywy oparte o indeksy: około 30.20 MiB do 37.64 MiB

I właśnie to jest niedocenione: za około 2 KiB metadanych PostgreSQL staje się dużo mniej błędny, podczas gdy alternatywy z indeksami potrafią zużyć dziesiątki MiB więcej i nadal nie rozwiązać problemu plannera.
Dlaczego „użyj obu” nie wygrało automatycznie
Oczywiście sprawdziłem też najbardziej oczywiste pytanie: czy połączenie extended statistics i dobrych indeksów daje automatycznie najlepszy wynik?
Nie zawsze.
Single-region:
- Tylko statistics: 2,857.896 ms
- Statistics + Partial Hot-Path Indexes: 4,876.187 ms
Multi-region:
- Tylko statistics: 7,289.319 ms
- Statistics + Partial Hot-Path Indexes: 8,950.207 ms
Więcej indeksów nie tworzy tylko nowych możliwości. Zmienia też przestrzeń wyszukiwania plannera. „Użyj obu” nie jest więc prawem natury, tylko kolejnym pytaniem benchmarkowym.
Praktyczne caveaty
Warto jasno powiedzieć o kilku ograniczeniach:
- Extended statistics działają tylko w obrębie jednej relacji.
- PostgreSQL nie używa ich bezpośrednio do estymacji selectivity joinów między tabelami.
- Nie każdy workload skorzysta. Jeśli kolumny są naprawdę bliskie niezależności, efekt może być mały.
- Nie zastępują dobrego projektu zapytań, sensownych indeksów, partycjonowania, rozsądnych ustawień pamięci ani szybkiego storage.
To funkcja informacyjna dla plannera, a nie uniwersalny talizman wydajnościowy.
Kiedy sięgać po CREATE STATISTICS
Praktyczna reguła jest prosta: jeśli plan wygląda źle, a źródłem problemu wydaje się wspólne filtrowanie lub grupowanie wielu kolumn w sposób, którego planner źle modeluje, pomyśl o extended statistics zanim odruchowo zbudujesz kolejny indeks.
Dobre kandydatury to:
- silnie skorelowane kolumny filtrujące,
- atrybuty wymiarów napędzane segmentem,
- group-by workloads z ewidentnie błędną kardynalnością,
- problemy multi-column fanout,
- silnie skośne kombinacje częstych wartości,
- plany, w których jedna zła estymacja pojedynczej relacji zatruwa całą resztę.
Słabsi kandydaci to zapytania z brakującą ścieżką dostępu, workloady z oczywistym bottleneckiem I/O albo przypadki, w których kolumny są faktycznie prawie niezależne.
Użyj EXPLAIN (ANALYZE, VERBOSE, BUFFERS). Jeśli estimated rows i actual rows mocno się rozjeżdżają, extended statistics mogą być dokładnie tym, czego potrzeba.
Prawda jest lepsza niż sztuczki
Najlepsza rzecz w CREATE STATISTICS polega na tym, że daje plannerowi więcej prawdy zamiast dokładania kolejnych struktur na dane.
Benchmarki nie mówią „extended statistics zawsze wygrywają”. Mówią coś bardziej użytecznego:
- sprawiły, że PostgreSQL był dużo mniej błędny,
- zmieniły kształt planu w sensowny sposób,
- kosztowały prawie nic w storage,
- i często trafiały w problem plannera bardziej bezpośrednio niż dziesiątki MiB dodatkowych indeksów.
Benchmark, kwerendy i wyniki są na GitHubie. Możesz też sam przetestować je w Vela Postgres Sandbox.
A jeśli kiedykolwiek patrzyłeś na plan i myślałeś: „nie ma świata, w którym ten join powinien być zagnieżdżony trzy razy i udawać dorosłego w prochowcu”, to bardzo możliwe, że właśnie szukałeś extended statistics.