
우리가 Vela를 만들기 시작했을 때, 아주 구체적이고 조금은 고집스러운 목표가 하나 있었습니다. 새로운 Postgres 환경은 너무 빨리 준비되어야 해서, 사용자가 그것을 “프로비저닝”처럼 느끼지 않아야 한다는 것이었습니다. 우리가 말한 것은 “VM 부팅치고 빠르다”가 아니라, 가능한 한 가장 빠르다는 뜻이었습니다. 플랫폼 엔지니어가 거의 즉시 제공된다고 말할 수 있을 정도로 빨라야 했고, 동시에 완전한 격리도 유지해야 했습니다.
다만 그와 함께 세 가지 제약이 있었습니다.
- 데이터베이스 간 완전한 격리. 단순한 “namespace 수준의 격리”가 아니라 강한 경계가 필요했습니다.
- noisy neighbor에 대한 강한 내성. CPU, RAM, 디스크 활동에 대한 하드 리소스 제한이 필요했습니다.
- Kubernetes 네이티브 스케일링. 자동 배치와 중단 없는 교체(live migration)가 필요했습니다.
Vela의 초기 목표는 겉으로 보기엔 간단하고 직관적이지만, 실제로는 짜증날 정도로 어려웠습니다. Vela의 각 데이터베이스(branch)는 강한 격리를 가지면서도, 동적으로 독립적으로 스케일할 수 있어야 했습니다. 즉 Kubernetes 위의 데이터베이스처럼 느껴지되, 격리 보장은 가상 머신처럼 제공해야 했습니다.
이 글은 우리가 어떻게 거기서 출발해 10초 미만 부팅에 도달했는지, 그 과정에서 데이터베이스 간 완전한 격리와 Kubernetes 안에서 자연스럽게 작동하는 스케일링 동작을 어떻게 유지했는지에 대한 이야기입니다. 그 과정에서 우리는 KubeVirt의 모델과 그 날카로운 모서리들, VM 오토스케일링이 pod 오토스케일링과 미묘하게 다른 이유, 그리고 아주 작은 커스텀 OS 이미지가 거의 어떤 튜닝 플래그보다도 더 큰 성능 레버가 될 수 있다는 점을 배웠습니다.
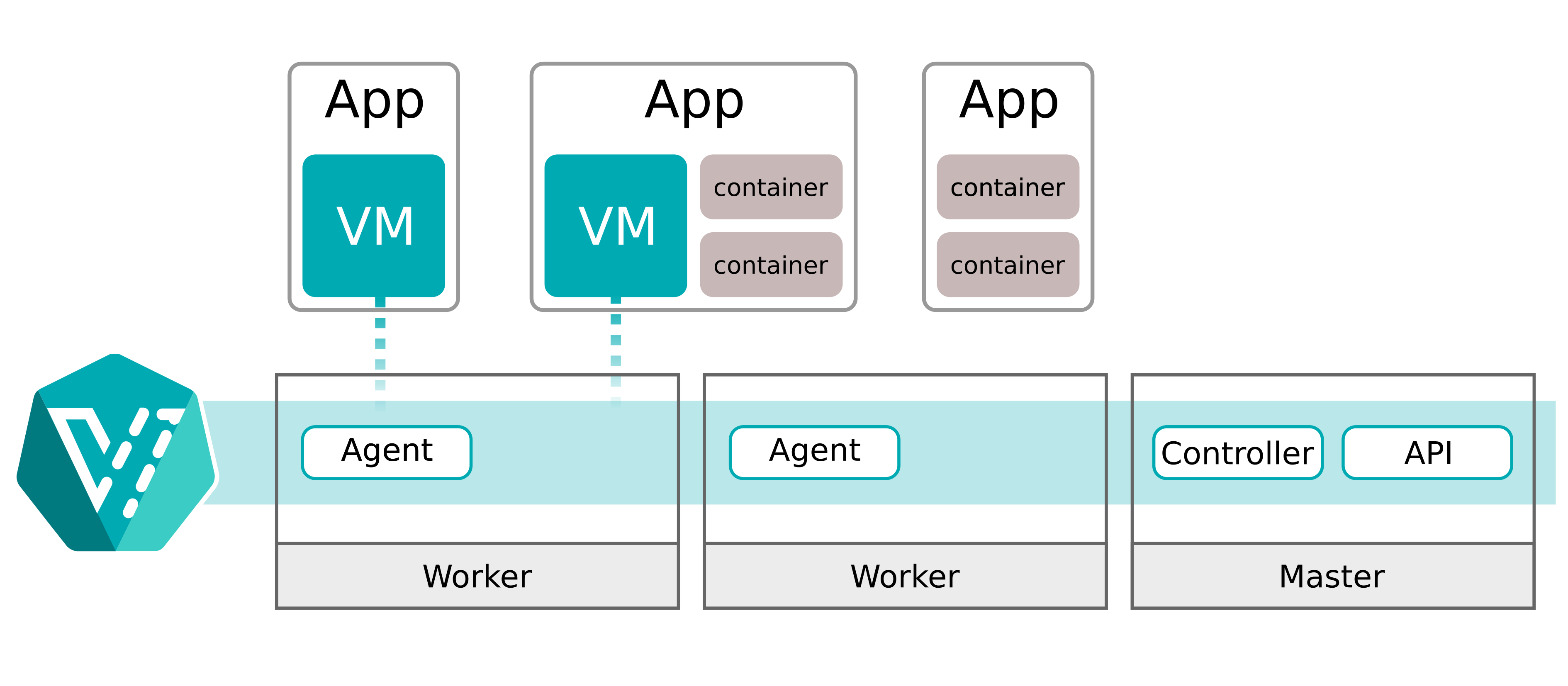
왜 가상 머신을 선택했는가
처음에 우리가 VM을 선택한 이유는 실용적인 하나의 이유였습니다. VM live migration은 이미 해결된 문제이기 때문입니다. 대부분의 하이퍼바이저가 이를 지원하고 있으며, 컨테이너 live migration보다 여전히 성숙도가 훨씬 높습니다. 우리는 컨테이너 마이그레이션 관련 작업들(예: zeropod)도 살펴봤지만, 우리의 제약에는 맞지 않았습니다. scale-to-zero까지 포함한 스케일링은 부드럽게 처리했지만, 우리가 요구한 “중단 없는 live migration”은 충족하지 못했습니다.
Kubernetes 역시 타협할 수 없는 조건이었습니다. 대부분의 플랫폼 팀에게 Kubernetes는 “기반 레이어”이며, 나머지 모든 것은 그 스케줄링, 가시성, 운영 수명주기 안으로 통합되어야 합니다.
그래서 우리는 당연한 선택을 했습니다. Postgres를 VM 안에서 실행하되, 그 VM은 여전히 Kubernetes 오브젝트로 제어하는 방식입니다. KubeVirt는 정확히 그 목적을 위해 설계되어 있습니다. Kubernetes API를 VM 타입으로 확장하고, QEMU/KVM을 실행하는 pod를 통해 VM “payload”를 구동합니다.
첫 번째 시도: KubeVirt, Docker, 그리고 답답한 부팅 시간
Kubernetes 위의 가상 머신? 그건 KubeVirt 입니다. 우리도 모두와 마찬가지로 그렇게 생각했습니다. 그렇게까지 어렵겠어?
우리의 첫 번째 구현은 좋은 날에는 약 2분, 나쁜 날에는 최대 5분이 걸렸습니다. 거의 즉시라고 해도 되겠죠? 🫣
VM 자체의 부팅 시간은 사실 그렇게까지 나쁘지 않았습니다. 하지만 VM을 부팅하는 것은 시작에 불과했습니다. 우리는 VM 안에서 Docker(Compose)를 시작한 뒤, 각 branch마다 여러 컨테이너 이미지를 pull하고 load했습니다. 사실상 Postgres, PGBouncer, PostgREST 등 branch별 모든 서비스를 VM 안에서 올린 셈입니다. Docker Hub throttling과 “image pull lottery”는 tail latency의 잔인한 원인이 되었습니다.
부팅 경로는 이렇게 생겼습니다.
- Kubernetes가 KubeVirt VM 리소스를 생성한다
- VM 리소스가 QEMU를 부팅한다
- 게스트 OS가 부팅한다
- Docker 서비스가 사용 가능해진다
- Docker가 각 컨테이너 이미지를 다운로드한다
- Docker가 의존성 그래프에 따라 컨테이너를 하나씩 시작한다
- 컨테이너가 올라오고 healthy 상태가 된다
- 우리가 branch를 active(healthy)로 표시한다
VM이 시작할 때마다 이미지를 다시 다운로드하는 것이 비효율적이라는 점은 알고 있었지만, 이렇게까지 심각할 줄은 몰랐습니다. 핵심 문제는 Docker가 이미지 다운로드와 컨테이너 시작을 처리하는 방식에 있었습니다. 기본적으로 먼저 모든 이미지를 내려받고, 그다음 의존성 그래프에 따라 시작합니다. 큰 이미지 하나, 혹은 throttling 때문에 느린 이미지 하나만 있어도 끝입니다. 이미지가 추가될수록 운 나쁜 날을 맞을 확률도 커집니다.
결국 우리는 지연을 증폭시키는 요소를 영향도 순서대로 세 가지로 정리했습니다.
- branch 서비스 이미지를 가져오기 위한 image pull과 registry throttling
- VM과 그 안의 Docker 컨테이너라는 2단계 시작 구조
- DNS 등록, 새 디스크 프로비저닝, Postgres의 initdb 실행 같은 추가 설정 단계
Docker 이미지를 미리 캐시하자
가장 먼저 없애야 했던 것은 매번 다운로드하는 문제였습니다. 부팅 경로에 “의존성 다운로드”가 들어가 있다면, 그것은 부팅 시간이 아니라 확률 분포입니다.
우리는 어차피 VM 이미지를 만들고 있었으니, 그 과정에서 필요한 Docker 이미지를 전부 미리 다운로드해 넣으면 되지 않을까 생각했습니다.
말한 대로 실행했습니다. 즉, 빌드 과정에 필요한 모든 Docker 이미지를 다운로드하고, 그것을 최종 가상 머신 부팅 이미지 안에 묶는 단계를 넣었습니다.
이 방법은 훌륭하게 작동했습니다. 부팅 시간 변동의 가장 큰 원인이 사라졌습니다. 우리는 꽤 안정적으로 90~100초 수준까지 내려왔습니다. 여전히 Linux 이미지를 부팅하고 Docker 서비스가 가능해질 때까지 기다리는 데 많은 시간이 들어갔고, 실제 branch 서비스를 시작하는 것은 그 이후였습니다. 하지만 첫 번째 시도로는 충분히 괜찮았습니다. 단순히 일반적인 Linux 이미지를 부팅하는 대신, 부팅 절차 자체를 최적화하면 더 줄일 여지가 있다는 것도 분명했습니다.
왜 하필 Docker였을까?
남아 있던 질문 중 하나는 “도대체 왜 VM 안에서 Docker를 썼느냐?”였습니다.
짧은 답은 한 단어입니다. 편의성입니다.
긴 답은, 서로 다른 Docker 이미지와 Pgpool-II, PGBouncer 같은 여러 잠재적 서비스 옵션을 시험하면서 더 빠른 반복 주기를 돌릴 수 있는 편의성 때문이었습니다.
우리는 가상 머신을 매번 다시 빌드하지 않고 실험할 수 있어야 했고, 당시 Docker는 완벽한 해결책이었습니다. 데이터베이스 업그레이드 역시 훨씬 쉽게 만들어 줄 수 있었습니다. Postgres의 메이저 버전 업그레이드에서는 새 버전과 기존 버전, 두 버전이 모두 필요합니다. Docker라면 이것은 다운로드 한 번이면 됐습니다. 새 버전의 베이스 이미지를 쓰고, 부팅 후에 이전 버전을 빠르게 다운로드하고, 마이그레이션을 실행한 뒤 이전 컨테이너 이미지를 제거하면 끝이었습니다.
어쨌든 다른 지연 요인들로 돌아가기도 전에, 또 다른 문제들이 우리 쪽으로 밀려오기 시작했습니다.
KubeVirt가 우리를 막기 시작했을 때
여기서 분명히 하고 싶습니다. 아래 문제들은 단순히 “KubeVirt가 나쁘다”는 이야기가 아닙니다. 사실 KubeVirt는 아주 어려운 문제를 해결하고 있고, 그것도 가장 Kubernetes다운 방식으로 해내고 있습니다.
문제는 우리의 목표 동작(빠르고, 자주 생성되고, 탄력적이며, 데이터베이스 형태를 띤 VM)이 시스템의 다른 부분들을 압박했다는 점입니다. 그것은 전형적인 “수명이 긴” VM, 즉 사용 방식이 거의 바뀌지 않는 VM이 아니었습니다. KubeVirt는 Kubernetes의 편의성과 전형적인 가상 머신의 수명주기와 격리를 원한다면 훌륭한 솔루션입니다. 하지만 우리는 그 상태에서 벗어나 있었고, 그 차이가 드러나기 시작했습니다.
가상 머신을 스케일하는 것은 pod를 스케일하는 것과 다르다
첫 번째 마찰 지점은 CPU와 RAM에 대한 VM 리소스 스케일링이 우리에게는 드문 일이 아니라는 점이었습니다. 우리는 가능한 한 자주, 가능한 한 빠르게 동적으로 scale up/down 하고 싶었습니다. 이상적으로는 scale-to-zero까지 포함해서 말입니다.
KubeVirt에서는 이런 변경이 즉시 live migration을 유발합니다. 현재 호스트에 충분한 리소스가 남아 있어도 마찬가지입니다. 핵심적인 고통은 live migration이 항상 VM을 다른 Kubernetes worker로 옮긴다는 점이었습니다. live migration의 성능 영향 자체는 제한적이지만, 가상 머신을 계속 옮기는 방식은 우리에게 맞지 않았습니다.
“Current hotplug implementation involves live-migration of the VM workload.” KubeVirt Authors, “Memory Hotplug” documentation (KubeVirt.io)
전형적인 VM 수명주기에는 이 설계 결정이 충분히 타당합니다. 하지만 우리에게는 모든 “resize”가 곧 “세상을 옮기는 일”이 되었고, 네트워크 복잡성과 데이터베이스 연결 유지 문제로 이어졌습니다.
우리는 리소스가 정말 부족할 때만 live migration을 하고, 그렇지 않을 때는 CPU와 RAM을 로컬에서 scale up/down 할 수 있는 해법이 필요했습니다.
live migration과 TCP 세션은 아주 거친 조합이다
우리는 또 하나의 더 거친 진실도 마주했습니다. live migration이 “매끄럽게” 보이려면, 네트워크 스택과 migration 파이프라인이 워크로드가 기대하는 불변 조건을 유지해야만 합니다. Postgres 클라이언트는 긴 정지를 용서하지 않습니다.
데이터베이스는 지연에 민감하고 연결 지향적입니다. 내부 테스트 결과, 아주 작은 불연속성도 지속적인 연결 테스트 동안 금방 눈에 띄었습니다. passt 같은 제안된 해결책은 부담을 조금 줄여주었지만, 중간 이상 수준의 pgbench 부하에서는 여전히 연결이 끊어졌습니다.
그리고 이 문제는 우리만의 것도 아닌 것 같았습니다. KubeVirt에는 migration 이후 네트워킹 문제에 대한 공개 이슈와 커뮤니티 논의가 있습니다. 예를 들어 migration 후에 masquerade 인터페이스에서 연결이 깨질 수 있다는 오래된 보고가 있습니다. 다른 커뮤니티 구성원들은 migration 중에 pod/network identity가 바뀌면서 연결이 사라지는 문제를 설명했습니다.
우리에겐 진짜 overlay networking이 필요했습니다.
이중 자원 회계: Pod 대 VM
또 다른 함정은 자원 제어가 스택의 여러 층에서 일어난다는 점이었습니다.
- 가상 머신 수준은 QEMU가 VM에 제공한다고 인식하는 자원입니다.
- Pod/Cgroup 수준은 Kubernetes가 virt-launcher(QEMU) pod에 실제로 강제하는 자원입니다.
우리 실험에서는 CPU와 메모리 할당을 VM 수준과 pod 수준에서 모두 효과적으로 관리해야 한다는 사실을 확인했습니다. pod 수준만 업데이트하면 VM 안에서 out-of-memory 문제가 발생했습니다. 이는 앞서 언급한 스케일링 문제와도 연결됩니다.
문제의 일부를 완화하고 live resizing을 가능하게 하기 위해, 우리는 KubeVirt를 우회해 libvirt를 사용하여 VM을 직접 업데이트해야 했습니다. 하지만 시스템을 망가뜨리지 않도록 조심해야 했습니다. KubeVirt 가상 머신 리소스에 대한 reconciliation 이벤트가 한 번이라도 발생하면, 그런 “수동” 변경은 즉시 무효화되기 때문입니다.
더 안전한 방법이 필요했습니다.
이제는 옮겨갈 때였다
우리는 여러 번, 지원되는 API 표면에 깔끔하게 들어맞지 않는 workaround가 필요하고, 다음 reconciliation이 그것을 다시 되돌려 버리는 상황에 부딪혔습니다. KubeVirt를 패치하는 것은 상당한 작업이었고, 단지 앞으로 나아가기 위해 이렇게 중심적인 프로젝트의 장기 fork를 유지하고 싶지는 않았습니다.
우리는 스스로에게 물었습니다.
- “KubeVirt는 Kubernetes를 위한 좋은 가상화 API인가?” 그렇다.
- “KubeVirt는 우리의 branch lifecycle과 scaling model에 맞는 좋은 추상화인가?” 우리는 아니라고 생각했다.
그래서 우리는 오픈소스 빌더라면 하는 행동을 했습니다. 우리의 요구에 더 잘 맞는 다른 접근을 찾은 것입니다. 기본적인 선택지는 둘이었습니다. 더 나은 기존 솔루션을 찾거나, 목적에 맞게 전부 처음부터 작성하거나.
처음 생각은 libvirt나 QEMU 위에 우리만의 추상화를 만드는 것이었습니다. 하지만 KubeVirt 소스의 규모를 살피고 필요한 기능을 설계하다 보니, 우리 앞에 놓인 스코프를 깨달았습니다.
가상 머신과 Kubernetes를 결혼시키는 일은 어려운 작업입니다. 서로 갈라지는 개념이 너무 많고, 그것들을 다시 통합해야 합니다. 우리는 겁이 났습니다. 그래서 먼저 다른 솔루션을 찾기로 했습니다. 우리가 필요로 하는 것에 더 가까운 무언가를. 그리고 운 좋게도 그것을 찾았습니다.
전환점: Neon의 Autoscaling 채택
요구사항을 더 잘 만족하는 다른 솔루션을 찾을 수 있다면, 그것을 찾는 것이 더 나은 접근입니다. 그리고 우리는 그렇게 했습니다.
접근 자체는 단순하고, 생각해 보면 명확했습니다. 인접한 회사들과 그들의 솔루션을 살펴보는 것입니다. 운 좋게도 세상에는 수많은 데이터베이스가 있습니다. 많은 것이 오픈소스이고, 많은 것이 Postgres와 관련되어 있습니다.
Neon의 Autoscaling 프로젝트를 찾았을 때, 우리는 위에서 언급한 한계에 처음 부딪힌 사람이 아니라는 것도 깨달았습니다. 그들도 비슷한 문제를 많이 겪었고, 그 문제를 해결하기 위해 자신들만의 해법을 썼습니다. Neon의 접근은 철저히 데이터베이스 형태였습니다. 그것은 K8s 관리하의 micro-VM(QEMU 기반) 안에서 Postgres를 수직 오토스케일링하도록 설계되어 있었습니다. 그리고 가장 까다로운 부분도 해결했습니다. “리소스를 바꾸거나 워크로드를 옮길 때 TCP 세션을 끊지 않는 것” 말입니다.
Autoscaling에서 가장 흥미로운 부분은 스케일링 결정이 어떻게 내려지고, 실제 스케일링이 어떻게 작동하는가입니다.
먼저 Autoscaling은 사용량 보고를 위해 Cgroups를 사용해 CPU와 메모리 리소스 범위를 정합니다. “호스트”(게스트 VM)의 사용량을 포착하기 위해 Prometheus를 통해 수집한 메트릭을 사용합니다. 몇 초마다 현재 사용량을 평가해 스케일업 또는 스케일다운 여부를 결정합니다. 또한 가상 머신 내부의 에이전트가 선제적으로 스케일링 결정을 요청할 수도 있지만, 거부될 수도 있습니다.
Autoscaling은 내부적으로 QEMU를 사용하므로 CPU와 메모리를 hot-plug 할 수 있습니다. 즉 런타임에 필요에 따라 CPU 코어를 가상 머신에 붙였다 떼었다 할 수 있습니다. 메모리도 비슷하게 작동하며, virtio-mem 장치를 런타임에 추가하거나 제거합니다. Linux 커널은 virtio-mem 장치를 떼기 전에 제거 대상 메모리 영역을 먼저 비워서 옮깁니다(메모리 ballooning과 비슷한 방식입니다).
“We want to dynamically change the amount of CPUs and memory of running Postgres instances, without breaking TCP connections to Postgres.” Neon Autoscaling README (GitHub)
Autoscaling 구성 요소
Autoscaling 자체는 Kubernetes 위에서 serverless Postgres를 가능하게 하는 여러 구성 요소의 집합입니다.
- 가상 머신 리소스(CRD)를 관리하는 controller(neonvm-controller)
- 노드 용량을 평가하고 VM 배치와 교체를 결정하는 scheduler
- VM 자원 사용량을 수집하고 보고하는 per-node agent(daemonset)
- 워크로드 옆에서 돌며 Prometheus를 통해 사용량을 보고하는 VM monitor(cgroup 전용 설정 포함)
- Flannel과 함께 가상 네트워크 인터페이스와 overlay networking을 통해 지속적인 연결성을 보장하는 VXLAN manager
- VM을 감싸는 runtime image. VM 이미지를 제공하고, QEMU를 시작하고, DHCP/port forwarding을 처리하고, mount를 관리한다
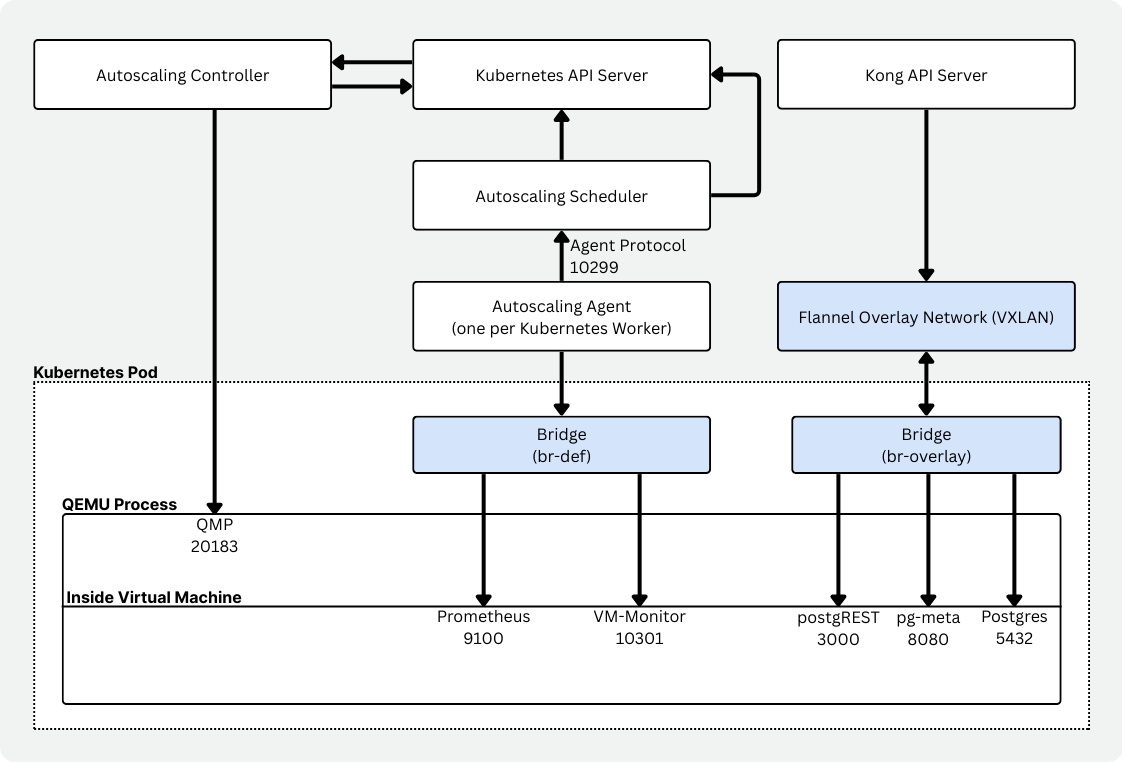
여기서도 동일한 개념적 분리가 보입니다. 맞춤형 scheduler, 노드별 autoscaling-agent, 그리고 메모리 압박에 즉시 반응할 수 있는 vm-monitor입니다. Vela에는 훨씬 더 잘 맞는 구조였습니다.
Autoscaling을 만든 Neon 팀에게 감사드립니다.
그래도 몇 가지 변경은 필요했다
하지만 Autoscaling이 꽤 잘 들어맞았음에도, Neon과 Vela의 구현 방식 차이 때문에 몇 가지 “거친 부분”은 남아 있었습니다.
먼저, 기반 스토리지로 simplyblock을 사용하기 때문에 가상 머신에 하나 이상의 PVC(Persistent Volume Claim)를 붙일 수 있어야 했습니다.
또한 CPU와 RAM 사용량에 제한을 두면서도, 그 제한을 live update하는 기능은 유지하고 싶었습니다. 안타깝게도 QEMU는 어느 시점이든 연결 가능한 최대 CPU와 RAM 값을 알아야 합니다. 우리는 사용자가 실제로 스케일할 것이라고 예상하는 수준보다 훨씬 높은 값을 넣어야 했습니다. 그래서 의사결정 과정에 soft limit을 추가했습니다. 현재 VM의 hard limit은 128 vCPU와 256 GB 메모리입니다. 반면 soft limit은 예를 들어 8 vCPU나 16 GB 메모리처럼, 현재 허용하는 최대 스케일링 범위를 설명합니다. soft limit을 넘는 요청은 거부됩니다.
마지막으로, 우리는 간단한 PowerState 를 추가했습니다. 이 값만 CRD에서 바꾸면 가상 머신을 시작하거나 멈출 수 있게 해줍니다. 순전히 편의성을 위한 기능입니다.
부팅 시간에서 승리하기: “VM 안의 Docker” 없애기
Autoscaling이 lifecycle과 scaling 마찰의 큰 부분을 해결한 뒤, 이제 다시 진짜 문제로 돌아갈 수 있었습니다. 바로 부팅 시간입니다. 부팅 시간의 진짜 돌파구는 우리가 스스로에게 솔직해졌을 때 왔습니다. 시작 시점에 우리가 하던 일은 솔직히 말해 멍청했습니다. 사용자 경험보다 우리의 편의성을 우선했기 때문입니다. 우리는 범용 Linux 배포판을 부팅하고, 그 안에서 Docker를 부팅하고, 여러 서비스를 컨테이너 이미지로 오케스트레이션하고 있었습니다. 그래서 내부 컨테이너 레이어 전체를 제거했습니다.
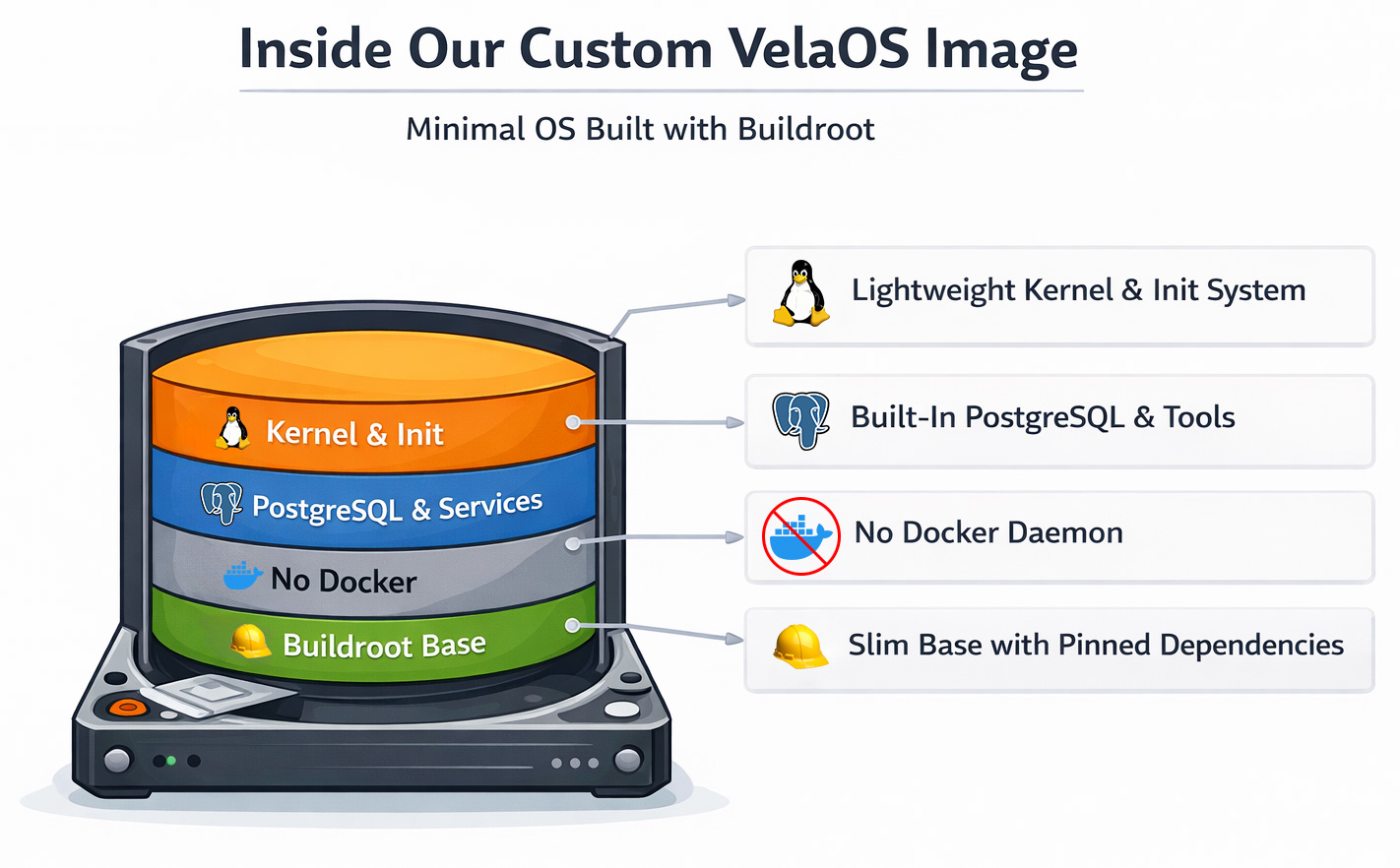
VelaOS: Buildroot 기반의 커스텀 Linux 커널과 rootfs
우리는 Buildroot 기반의 커스텀 Linux 이미지로 전환했습니다. Buildroot는 Linux 커널과 최소한의 root filesystem을 빌드하기 위한 프레임워크입니다. 원래는 임베디드 장치를 위해 설계되었고, 읽기 전용 filesystem 이미지, 디바이스 업데이터 등도 지원합니다.
Buildroot라는 이름 자체는 익숙하지 않을 수 있지만, 실제로는 널리 사용되는 시스템입니다. 더 잘 알려진 사용처로는 OpenWRT, Home Assistant OS(HAOS), 그리고 Google Fiber 같은 임베디드 디바이스 제조사가 있습니다. Buildroot는 최소 크기의 root filesystem으로 잘 알려져 있습니다.
Buildroot로 전환하면서 Docker를 없앤 것 외에도 몇 가지 빠른 이점을 얻었습니다.
- 부팅 과정이 결정적이 되었다. inittab을 기본 init 시스템으로 사용해 무엇이 언제 시작되는지를 정확히 통제할 수 있었기 때문입니다.
- 더 이상 Docker pull이 필요 없다. 모든 서비스가 부팅 이미지에 통합되어 있기 때문입니다.
- 더 빠른 부팅 속도. 범용 운영체제 이미지가 아니라 최적화된 Linux 커널을 사용하기 때문입니다.
- 재현 가능한 빌드. 모든 구성 요소를 특정 버전이나 커밋, 체크섬에 고정해 수정되지 않은 컴포넌트만 빌드되도록 했기 때문입니다.
반대편에는 속도 저하가 있었습니다. Buildroot는 빌드 프레임워크로서 최종 이미지의 대부분 구성 요소를 스스로 빌드합니다. 그 덕분에 매우 작은 디스크 이미지를 얻을 수 있지만, 대가로 빌드 시간이 필요합니다. 그래도 CCache와 기타 최적화 기법 덕분에 충분히 관리 가능한 수준이었습니다.
그 결과 부팅 경로는 매우 단순해졌습니다.
- Kubernetes가 autoscaling scheduler 결정에 따라 VM pod를 스케줄링한다
- runtime이 우리의 VM 이미지로 QEMU를 시작한다
- 게스트는 이미 필요한 서비스가 설치된 최소 OS를 부팅한다
- Postgres와 branch 지원 서비스가 즉시 올라온다(다운로드 없음)
아직도 개선의 여지는 있습니다. 하지만 지금 시점에서는 <10초면 충분히 좋다고 생각합니다. Vela의 가치는 “branch가 빠르게 나타나고, 일관되게 동작하며, 강하게 격리된다”는 데 있습니다.
격리와 확장성: 왜 여전히 Kubernetes처럼 느껴지는가
합리적인 우려는 이런 것입니다. “KubeVirt를 떠나서 커스텀 VM plumbing을 돌리기 시작했다면, Kubernetes의 인체공학을 잃은 것 아닌가?”
실제로 우리는 Kubernetes의 중요한 부분들을 그대로 유지했습니다. 여전히 원하는 상태를 reconciliation 하는 CRD와 controller를 통한 선언적 제어가 있습니다. scheduling은 Kubernetes를 통해 구현되고, 배치는 autoscaling scheduler와 agent의 영향을 받습니다. 노드 수준의 자원 제약은 실제 노드 용량과 실제 VM 사용량에 기반한 배치, 스케일링, migration 판단의 근거를 제공합니다. 그리고 마지막으로 각 데이터베이스 branch가 자체 VM 경계를 가지면서 격리 경계가 강제됩니다.
이 모든 것을 유지하면서도, 기존 Postgres 연결을 끊지 않고 한 Kubernetes worker에서 다른 worker로 Vela branch를 완전히 live-migrate할 가능성도 보존했습니다.
빠른 부팅은 control plane 기능이기도 하다
하지만 10초 미만 부팅은 단순히 사용자 경험에만 영향을 주는 것이 아닙니다. 그것은 무엇을 어떻게 만들 것인지 자체를 바꿉니다.
- Vela는 더 공격적으로 스케일 업할 수 있습니다. 용량을 추가하는 비용이 저렴하기 때문입니다. 더 많은 가상 머신을 통한 수평 확장에서도, VM limit의 live-resizing을 통한 수직 확장에서도 마찬가지입니다.
- Vela는 환경을 ephemeral하게 다룰 수 있습니다. 재생성 비용이 낮고 스토리지와 컴퓨트가 완전히 분리되어 있기 때문입니다.
- Vela는 고장을 수리하는 대신 VM 교체로 흡수할 수 있습니다.
이것이 결국 사용자, 에이전트, CI 워크플로를 기다리게 하지 않고도 서비스할 수 있는 시스템의 형태입니다.
배운 점: 항상 생각보다 더 복잡하다!
“VM vs 컨테이너”가 진짜 논쟁이 아니다. 중요한 것은 부팅 경로의 결정성이다.
우리는 좋은 이유(마이그레이션 성숙도, 강한 격리)로 VM에서 시작했습니다. 하지만 최악의 지연은 우리 자신의 편의성과 빠른 반복에 대한 사랑에서 나왔습니다. Docker 시작과 이미지 pull 말입니다. “부팅할 때 이미지 pull”을 제거한 순간, 준비 시간은 더 이상 도박이 아니게 되었습니다.
Kubernetes reconciliation은 친구이자 적이다.
자신이 “reconciler를 피해 가며 일하고 있다”는 느낌이 든다면, 그것을 의도된 확장 모델 바깥에 있다는 신호로 받아들이고, 지원되는 패턴 쪽으로 돌아가거나, 자신의 제어 요구에 맞는 substrate를 선택해야 합니다.
가장 빠른 최적화는 대개 무언가를 제거하는 것이다.
가장 빠른 코드가 아예 실행되지 않는 코드인 것처럼, 가장 빠른 최적화는 불필요한 구성 요소를 없애는 것입니다. 우리 경우에는 Docker Compose와 이미지 pull을 완전히 제거함으로써 수 분 단위의 변동성을 없앴습니다.
live migration은 하나의 기능이 아니라 전체 제품 표면이다.
KubeVirt와 Autoscaling은 migration에 접근하는 방식이 매우 다릅니다. KubeVirt에서는 거의 모든 CPU 또는 메모리 변경이 live migration으로 이어지는 반면, Autoscaling은 가능한 한 기존 VM 인스턴스 안에서 처리하고, 물리 자원이 부족해질 때만 migration으로 넘어갑니다. 또 하나의 큰 차이는 Kubernetes 네트워크 평면 위의 꼼수가 아니라 실제 overlay network를 사용해 안정적인 네트워크 identity를 얻는다는 점입니다. 워크로드가 데이터베이스에 가깝다면, “이것이 migrate되었다”는 이벤트는 클라이언트에게 보이지 않아야 합니다. 그렇지 않으면 reconnect storm과 tail latency와 싸우는 데 모든 시간을 쓰게 됩니다.
최소 OS 이미지는 속도만을 위한 것이 아니다. 운영 엔트로피도 줄여 준다.
작고 목적 지향적인 이미지는 움직이는 부품이 적습니다. 그 말은 예상치 못한 상호작용이 적고, 뒤에서 “도와주는” 일을 하는 데몬도 적으며, 문제가 생겼을 때 디버깅해야 할 표면도 더 작다는 뜻입니다. Buildroot 기반의 VelaOS 덕분에 우리는 재현 가능한 빌드와, 특정 시점의 VM 안에 무엇이 들어 있는지를 정확히 인증할 수 있는 옵션도 얻었습니다(데이터는 제외).
겁나는 것을 두려워하지 말자. 때로는 그것이 좋은 결과로 이어진다.
우리만의 KubeVirt 대안을 만드는 것을 검토했을 때, 그 작업 범위는 무서울 정도였습니다. 그 두려움 덕분에 우리는 이미 존재할지 모르는 다른 솔루션을 조사하는 데 시간을 쓰게 되었고, 그 결과 Autoscaling을 발견했습니다. 그리고 우리는 겁을 먹었기 때문에 오히려 잘됐다고 생각합니다.
KubeVirt는 Kubernetes 생태계에서 중요한 일을 하고 있다.
KubeVirt가 가상 머신을 Kubernetes로 가져오는 첫걸음을 내딛지 않았다면, 우리는 오늘 여기 없었을지도 모릅니다. 명시적으로 말할 가치가 있습니다. KubeVirt는 생태계에 중요한 일을 하고 있습니다. 우리가 한계를 느낀 부분조차 프로젝트는 여전히 활발히 진화하고 있습니다. 예를 들어 KubeVirt 커뮤니티는 migration targeting과 resize coupling에 대한 개선을 #15625 같은 이슈에서 추적하고 있습니다. 또한 KubeVirt는 클라우드 환경에서 Cluster Autoscaler와 함께 동작하는 실제 통합 사례를 계속 문서화하고 있습니다.
우리가 다음에 가고 싶은 방향
우리는 이것을 “KubeVirt vs Neon Autoscaling”으로 보지 않습니다. Kubernetes에서 VM을 실행하는 방법은 여러 가지가 있고, 최선의 선택은 워크로드의 형태에 달려 있습니다.
KubeVirt는 Kubernetes를 위한 강력하고 범용적인 가상화 계층이며, 우리는 여전히 그 진전을 면밀히 지켜보고 있습니다.
하지만 Vela의 핵심 목표, 예를 들면 강한 격리를 가진 빠르고 일시적인 데이터베이스 branch를 위해서는, 데이터베이스에 맞게 철저히 최적화된 control plane과 runtime 경로가 필요했습니다.
Neon의 Autoscaling은 올바른 기반을 제공했고, Vela OS는 부팅 시간을 예측 가능하게 만들었습니다.
이 영역에서 무언가를 만들고 있다면, 여러분의 경험과 결정, 그리고 추가적인 edge case에 대해 꼭 이야기해 보고 싶습니다. 특히 네트워킹, migration 동작, VM 이미지 설계에 대해서요.
가까운 미래에 우리는 우리가 만든 개선 사항을 upstream하기 시작할 것입니다. 우리는 건강한 오픈소스 생태계를 믿고 있으며, 변화를 사적으로 숨기기보다 공유하고 싶습니다.
우리의 Vela Postgres 인스턴스를 직접 경험하고 시험해 보고 싶다면 https://demo.vela.run 에서 무료 계정을 만들 수 있습니다. Vela는 완전한 오픈소스이며, 자체 데이터센터나 프라이빗 클라우드에서 self-hosting하는 것을 목표로 합니다. 현재는 코드베이스를 정리하고, 남은 버그를 수정하고, 사용자용 설치 절차를 구현하는 중입니다.