
짧게 말하면, 쿼리가 느릴 때 대부분의 사람은 먼저 인덱스를 생각합니다. PostgreSQL에는 multi-column, partial, expression index 등 많은 선택지가 있습니다. 문제는 비용입니다. 인덱스가 늘수록 저장 공간과 쓰기 비용, 유지 비용도 늘어납니다. 여기서 많은 사람이 놓치는 것이 CREATE STATISTICS 입니다. 확장 통계는 거의 무시할 수 있는 저장 공간으로 planner를 훨씬 덜 틀리게 만들 수 있습니다.
많은 나쁜 실행 계획의 진짜 문제는 planner가 게으르기 때문이 아니라, 잘못된 데이터 그림을 보고 합리적인 결정을 내리고 있기 때문입니다. 여러 조건이 서로 상관되어 있을 때는 열 단위 통계만으로는 부족합니다. 바로 여기에 확장 통계가 들어옵니다.
짧은 버전
CREATE STATISTICS 는 일반적인 열 단위 통계로는 표현하기 어려운 추가 정보를 PostgreSQL이 수집하도록 해 줍니다.
실제로 특히 도움이 되는 경우는 다음과 같습니다.
- 여러 컬럼에 걸친 상관 필터,
- 다중 컬럼 distinct 추정,
- 심하게 치우친 값 조합,
- 보통 expression index를 만들고 싶어지는 식.
–-- Alternative to index on expressions CREATE STATISTICS stats_expr ON (date_trunc(‘day’, created_at)) FROM events; --- What people normally mean by --- extended statistics CREATE STATISTICS stats_multi (dependencies, ndistinct, mcv) ON plan_tier, region, billing_status FROM tenants; |
첫 번째 형태는 date_trunc 이나 JSONB 추출 같은 표현식 통계에 유용합니다. 두 번째가 사람들이 흔히 “extended statistics”라고 부르는 형태입니다.
핵심 유형은 dependencies, ndistinct, mcv 세 가지입니다. 그리고 일반 통계와 마찬가지로 CREATE STATISTICS 는 정의만 만들고, 실제 값을 채우는 것은 ANALYZE 입니다.
왜 확장 통계가 필요한가
기본적으로 PostgreSQL은 컬럼별 통계를 중심으로 동작합니다. 단일 컬럼 필터에서는 잘 작동하지만, 컬럼 간 관계가 중요한 순간부터 문제가 생깁니다.
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
현실의 데이터에서는 이런 조건들이 자주 서로 상관되어 있습니다. 하지만 추가 통계가 없으면 PostgreSQL은 각 조건이 독립적으로 행 수를 줄인다고 가정합니다. 그 결과 수학적으로는 깔끔하지만 운영적으로는 터무니없는 추정이 나옵니다.
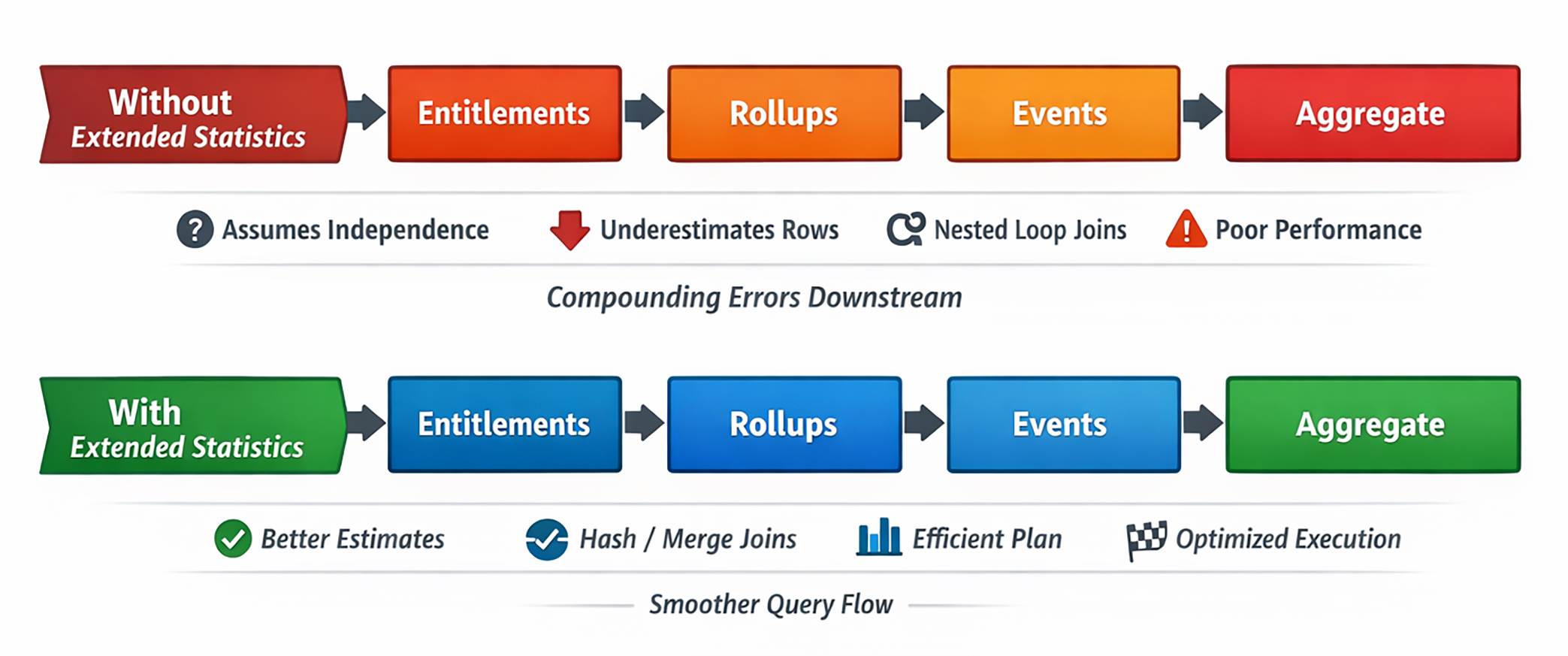
그리고 처음 추정이 틀어지면 이후 join 순서, join 방식, 병렬화, hash 크기, sort 전략, spill 위험까지 다 함께 흔들립니다.
Postgres가 기본적으로 알고 있는 것
ANALYZE 가 실행될 때마다 PostgreSQL은 각 컬럼에 대해 null 비율, 히스토그램, 자주 등장하는 값, distinct 수 등을 저장합니다. 모두 유용하지만 어디까지나 컬럼 단위 지식입니다.
예를 들어 100만 행짜리 테이블이 다음 분포를 가진다고 해 봅시다.
plan_tier = 'enterprise'는 6 %region = 'eu-central'는 25 %billing_status = 'active'는 80 %
1,000,000 * 0.06 * 0.25 * 0.80 = 12,000 rows |
문제는 현실에서 이 컬럼들이 독립적인 경우가 드물다는 점입니다. 실제 답은 40,000행일 수도, 60,000행일 수도, 5,000행일 수도 있습니다. 단일 컬럼 통계만으로는 알 수 없습니다.
확장 통계 벤치마킹
이를 구체적으로 보여 주기 위해, tenants, tenant_entitlements, usage_rollups, analytics_events 로 구성된 비교적 현실적인 SaaS analytics workload를 만들었습니다.
이 데이터셋은 planner의 맹점을 드러내도록 의도적으로 설계되었습니다. 요금제, 리전, 청구 상태의 상관관계, enterprise tenant에 집중된 premium entitlement, 그리고 무작위가 아닌 (tenant, feature, day) 조합 등이 그것입니다.
물론 합성 데이터이지만, 풍동 실험처럼 실제 현상을 분리해서 보기 위한 통제된 합성입니다.
데이터 형태로 문제를 분리하기
테이블: tenants
요금제, 리전, 청구 상태는 실제 SaaS 데이터에서 흔히 보이는 방식으로 상관되어 있습니다.
테이블: tenant_entitlements
sso, audit_logs, workflows 같은 premium feature는 enterprise tenant에 더 많이 집중됩니다.
테이블: usage_rollups
이 테이블은 tenant-feature 조합당 시간 축 fanout을 현실적으로 모델링합니다.
테이블: analytics_events
여기가 고카디널리티 폭발 지점입니다. 앞단 필터를 통과한 tenant-feature 조합마다 많은 raw event가 붙을 수 있습니다.
리포팅 쿼리
비즈니스 질문은 단순합니다. “중요한 리전에 있는 active enterprise tenant 중 어떤 premium feature가 최근 가장 많은 활동을 만들었는가?”
SELECT e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.region = 'eu-central' AND t.billing_status = 'active' AND te.entitlement IN ('sso', 'audit_logs') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY e.feature_name ORDER BY rolled_requests DESC; |
여러 리전을 동시에 다룰 때는 CTE와 후단 집계를 추가한 확장 버전을 사용합니다.
WITH regional_feature_totals AS ( SELECT t.region, e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') AND te.entitlement IN ('sso', 'audit_logs', 'workflows') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY t.region, e.feature_name ) SELECT region, feature_name, total_events, rolled_requests FROM ( SELECT region, feature_name, total_events, rolled_requests, row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank FROM regional_feature_totals ) ranked WHERE regional_rank <= 3 ORDER BY region, regional_rank; |
쿼리 형태를 단계별로 쪼개기
1단계: tenant slice 정의
WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') |
PostgreSQL이 이 첫 모집단을 틀리게 추정하면, 이후 모든 fanout은 잘못된 기반 위에 세워집니다.
2단계: 사용할 권한이 있는 feature로 제한
JOIN tenant_entitlements te ON te.tenant_id = t.id ... AND te.entitlements IN (...) |
entitlement 테이블은 단순한 join 대상이 아니라, 상관된 feature 필터 역할도 동시에 합니다.
3단계: 최근 사용량과 결합
JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement ... AND r.rollup_day >= CURRENT_DATE - 30 |
여기서 multiplicity가 시작됩니다. 하나의 tenant는 여러 entitlement를 가질 수 있고, 하나의 tenant-feature 쌍에 여러 recent rollup day가 있을 수 있습니다.
4단계: raw event까지 확장
JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name ... AND e.event_type IN (...) |
이 시점에서 행 수 추정이 잘못되면 비용이 크게 튀기 시작합니다. Nested Loop가 종이 위에서는 싸 보일 수 있어도 실제로는 아닐 수 있습니다.
5단계: 다시 작은 결과로 접기
GROUP BY e.feature_name ORDER BY rolled_requests DESC |
GROUP BY t.region, e.feature_name |
최종 결과는 작지만, 거기에 도달하기까지의 작업량은 작지 않습니다. 이 점이 이 쿼리를 planner 데모로 좋게 만듭니다.
6단계: multi-region 쿼리의 ranking
row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank ... --- followed by WHERE regional_rank <= 3 |
여기서는 추가적인 sort 압력과 temp I/O가 발생합니다. 즉, 이 문제는 단순한 join/aggregate 문제를 넘어 ranking 문제이기도 합니다.
확장 통계가 구해 주는 부분
이런 문제를 보면 보통은 multi-column index, partial index, expression index를 더 추가하고 싶어집니다. 하지만 여기서는 planner의 잘못된 믿음을 바로잡기 위해 세 개의 통계 객체를 만듭니다.
- tenant 컬럼 간 상관관계,
- tenant-entitlement 조합,
- rollup 조합.
물론 생성 후에는 ANALYZE 를 다시 실행해야 합니다.
유형: dependencies
함수적 종속성 통계는 특정 컬럼이 다른 컬럼을 충분히 강하게 예측하므로, 독립이라고 가정하는 것이 틀렸다는 사실을 PostgreSQL에 알려줍니다.
- 국가는 통화를 강하게 예측한다.
- 주는 시간대를 강하게 예측한다.
- tenant 세그먼트는 entitlement family를 강하게 예측한다.
CREATE STATISTICS stats_tl_segment_dependencies (dependencies) ON id, plan_tier, region, billing_status FROM tenants; |
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
기억하기 쉽게 말하면, dependencies 는 “이 필터들은 독립이 아니다”를 고쳐 줍니다.
유형: mcv
MCV 는 “most common values”지만, 여기서는 “most common combinations”라고 이해하는 편이 더 좋습니다.
CREATE STATISTICS stats_tl_segment_mcv (mcv) ON plan_tier, region, billing_status FROM tenants; |
그러면 PostgreSQL은 어떤 조합이 유난히 흔한지, 드문지, 아예 존재하지 않는지를 배울 수 있습니다. 기억하기 쉽게 말하면, mcv 는 “이 정확한 조합은 평균과 다르다”를 고쳐 줍니다.
유형: ndistinct
ndistinct 는 여러 컬럼 조합이 실제로 몇 가지 존재하는지를 PostgreSQL에 알려 줍니다. 각 컬럼의 개별 distinct 수만 아는 것과는 다릅니다.
CREATE STATISTICS stats_tel_entitlement_ndistinct (ndistinct) ON tenant_id, entitlement FROM tenant_entitlements; CREATE STATISTICS stats_url_feature_ndistinct (ndistinct) ON tenant_id, feature_name, rollup_day FROM usage_rollups; |
기억하기 쉽게 말하면, ndistinct 는 “이 group이나 join 조합은 planner가 생각하는 것만큼 많지 않다”를 고쳐 줍니다.
PostgreSQL이 실제로 저장하는 것
여기서 특히 흥미로워집니다. 물론 이런 문제를 추가 인덱스로 해결할 수도 있습니다. 하지만 인덱스는 유지 비용과 저장 비용이 큽니다.
반면 확장 통계는 놀랄 만큼 저렴합니다. 정의는 pg_statistic_ext 에, 실제 데이터는 pg_statistic_ext_data 에 저장됩니다.
pg_statistic_ext는 통계 객체 정의를 저장합니다.pg_statistic_ext_data는 수집된 실제 데이터를 저장합니다.
이 벤치마크에서 전체 통계 객체의 footprint는 약 2,059바이트였습니다.
- Tenant-Segment
mcv: 약 1,049바이트 - Tenant-Segment
dependencies: 약 518바이트 - Entitlement
ndistinct: 약 220바이트 - Rollup
ndistinct: 약 272바이트
핵심은 이것입니다. 거대한 그림자 인덱스가 아니라, planner를 덜 틀리게 만드는 작은 메타데이터라는 점입니다.
실행 계획 고치기
처음 이 글을 쓰기 시작했을 때 가장 보여 주고 싶었던 것은 runtime 개선이었습니다. 물론 개선은 있었지만, 더 중요한 것은 추정 품질이 훨씬 좋아졌다는 점이었습니다.
| Scenario | Average Time | Worst Estimate | Additional Storage |
|---|---|---|---|
| Extended statistics | 2,857.896 ms | 48.27x | 2.0 KiB |
| Baseline + Composite Join-Key Indexes | 5,882.659 ms | 106.48x | 37.64 MiB |
| Baseline + Events (feature_name, event_type, tenant_id) | 4,781.551 ms | 108.7x | 31.45 MiB |
| Baseline + Partial Hot-Path Indexes | 4,765.351 ms | 106.22x | 30.20 MiB |
| Extended Statistics + Partial Hot-Path Indexes | 4,876.187 ms | 46.65x | 30.21 MiB |
각 쿼리는 5번 실행했습니다. 전체 계획과 결과는 repository 에 있습니다.
단일 리전 쿼리
기본 스키마는 단일 컬럼 인덱스를 사용합니다. 완전한 순차 실행은 피하지만, planner는 여전히 tenants, entitlements, rollups, events 사이의 상관관계를 추정해야 합니다.
| Metric | Value |
|---|---|
| Average execution time | 14,168.174 ms |
| Average planning time | 4.134 ms |
| Execution samples | 31,093.955 ms, 29,065.788 ms, 3,564.811 ms, 3,570.114 ms, 3,546.200 ms |
| Planning samples | 5.058 ms, 3.952 ms, 8.969 ms, 1.899 ms, 0.793 ms |
| Join chain | Nested Loop:Inner -> Nested Loop:Inner -> Nested Loop:Inner |
| Scan nodes | Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Nested Loop: 178,389 estimated / 18,774,720 actual (105.25x) |
| Worst estimate path | Sort -> Aggregate -> Nested Loop |
확장 통계를 넣으면 상황이 확실히 좋아집니다.
| Metric | Value |
|---|---|
| Average execution time | 2,857.896 ms |
| Average planning time | 3.025 ms |
| Execution samples | 4,318.854 ms, 2,612.261 ms, 2,396.848 ms, 2,467.702 ms, 2,493.816 ms |
| Planning samples | 6.719 ms, 2.067 ms, 2.128 ms, 2.243 ms, 1.970 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Hash: 12,966 estimated / 625,824 actual (48.27x) |
| Worst estimate path | Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash |
planner는 더 이상 중간 결과가 아주 작다고 착각하지 않습니다. 중요한 디테일 하나는, 추정 총 비용이 오히려 올라간다는 점입니다. 이것은 회귀가 아니라, PostgreSQL이 드디어 좀 더 현실적인 비용을 믿기 시작했다는 뜻입니다.
다중 리전 쿼리
multi-region 버전에서는 실행 시간 개선이 더 분명했습니다.
기본값:
| Metric | Value |
|---|---|
| Average execution time | 24,933.705 ms |
| Average planning time | 3.648 ms |
| Execution samples | 84,815.859 ms, 12,696.190 ms, 11,819.487 ms, 8,482.936 ms, 6,854.054 ms |
| Planning samples | 6.125 ms, 5.681 ms, 2.067 ms, 2.181 ms, 2.187 ms |
| Join chain | Merge Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Sort: 53,580 estimated / 17,164,496 actual (320.35x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Merge Join -> Sort |
확장 통계 적용 후:
| Metric | Value |
|---|---|
| Average execution time | 7,289.319 ms |
| Average planning time | 2.875 ms |
| Execution samples | 7,503.924 ms, 8,261.715 ms, 7,433.035 ms, 8,181.565 ms, 5,066.357 ms |
| Planning samples | 9.244 ms, 0.932 ms, 1.039 ms, 1.801 ms, 1.359 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Nested Loop: 68,387 estimated / 1,113,566 actual (16.28x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash -> Nested Loop |
이건 사소한 개선이 아닙니다. PostgreSQL이 드디어 현실과 비슷한 우편번호로 돌아온 수준입니다.
정말 더 빨라졌는가?
그럴 때도 있고 아닐 때도 있습니다. 그래서 이 주제는 더 신중하게 다뤄야 합니다.
단일 리전 런타임
- 기본 평균: 14,168.174 ms
- 확장 통계 평균: 2,857.896 ms
겉보기에는 극적이지만, baseline의 처음 두 번이 특히 느렸기 때문입니다. 따라서 조심스럽게 말하면, planner의 이해가 좋아졌고 이 workload에서는 안정 상태의 동작도 함께 좋아졌다고 보는 편이 맞습니다.
다중 리전 런타임
- 통계만 사용: 7,289.319 ms
- 가장 좋은 index-only 전략: 6,886.473 ms
이것은 CREATE STATISTICS 의 가치를 약하게 만들지 않습니다. 통계는 cardinality 추정을 고치고, 인덱스는 물리적 접근 경로를 만든다는 차이를 더 선명하게 보여 줄 뿐입니다.
왜 인덱스 비교가 중요한가
흥미로웠던 점은 인덱스를 많이 쌓은 시나리오가 비용이나 runtime 면에서는 괜찮아 보여도, 추정 품질에서는 훨씬 더 나빴다는 것입니다.
- 확장 통계: 약 2.0 KiB
- 인덱스 중심 대안: 약 30.20 MiB ~ 37.64 MiB

바로 이것이 과소평가된 부분입니다. 약 2 KiB의 메타데이터로 PostgreSQL을 훨씬 덜 틀리게 만들 수 있었고, 반대로 인덱스 중심 대안은 수십 MiB를 더 쓰고도 planner 문제 자체는 해결하지 못하는 경우가 많았습니다.
왜 “둘 다 쓰기”가 자동으로 이기지 않았는가
당연히 “확장 통계와 좋은 인덱스를 같이 쓰면 더 좋지 않을까?”도 테스트했습니다.
하지만 항상 그렇지는 않았습니다.
Single-region:
- 통계만: 2,857.896 ms
- 통계 + Partial Hot-Path Indexes: 4,876.187 ms
Multi-region:
- 통계만: 7,289.319 ms
- 통계 + Partial Hot-Path Indexes: 8,950.207 ms
인덱스가 늘어나면 기회만 늘어나는 것이 아니라 planner의 탐색 공간도 바뀝니다. “둘 다 쓰면 무조건 이긴다”는 자연 법칙이 아니라 또 다른 벤치마크 주제일 뿐입니다.
실무적인 주의점
명확히 짚고 넘어가야 할 제약이 몇 가지 있습니다.
- 확장 통계는 단일 relation 내부 에서만 적용됩니다.
- PostgreSQL은 이를 테이블 간 join selectivity 추정 에 직접 사용하지 않습니다.
- 모든 workload가 혜택을 보는 것은 아닙니다. 컬럼이 정말 독립적이면 얻는 것이 적습니다.
- 좋은 쿼리 설계, 유용한 인덱스, 파티셔닝, 적절한 메모리 설정, 빠른 스토리지를 대체하지는 못합니다.
이 기능은 planner에 더 좋은 정보를 주는 기능이지, 만능 성능 부적이 아닙니다.
언제 CREATE STATISTICS를 꺼내야 하나
실무 규칙은 단순합니다. 계획이 이상해 보이고, 그 이상함이 여러 컬럼이 함께 필터링되거나 그룹핑되는 방식과 관련 있어 보인다면, 반사적으로 새 인덱스를 만들기 전에 확장 통계를 먼저 떠올려야 합니다.
좋은 후보는 다음과 같습니다.
- 강하게 상관된 필터 컬럼,
- 세그먼트에 의해 좌우되는 속성,
- cardinality가 분명히 틀린 group-by workload,
- multi-column fanout 문제,
- 치우친 조합의 common values,
- 단일 relation의 나쁜 추정이 나머지 계획 전체를 오염시키는 경우.
반대로 좋지 않은 후보는 물리적 접근 경로가 부족한 경우, 명확한 I/O 병목이 있는 경우, 그리고 컬럼이 실제로 거의 독립적인 경우입니다.
EXPLAIN (ANALYZE, VERBOSE, BUFFERS) 를 사용해 보세요. estimated rows와 actual rows의 차이가 크다면, 확장 통계가 정답일 가능성이 높습니다.
트릭보다 진실을 선택하기
CREATE STATISTICS 의 가장 좋은 점은 데이터 위에 구조물을 더 쌓는 대신, planner에게 더 많은 진실을 준다는 점입니다.
이 벤치마크가 말하는 것은 “확장 통계는 항상 이긴다”가 아닙니다. 더 유용한 말은 다음과 같습니다.
- PostgreSQL을 훨씬 덜 틀리게 만들었다.
- 계획 형태를 의미 있게 바꾸었다.
- 저장 공간 비용이 거의 없었다.
- 그리고 종종 수십 MiB의 추가 인덱스보다 planner 문제를 더 직접적으로 해결했다.
벤치마크, 쿼리, 결과는 GitHub 에 있습니다. Vela Postgres Sandbox 에서 직접 실행해 볼 수도 있습니다.
그리고 만약 실행 계획을 보고 “이 join이 도대체 왜 trench coat를 입고 세 번 중첩돼 있어야 하지?”라고 생각한 적이 있다면, 어쩌면 당신이 찾고 있던 기능은 바로 확장 통계일지도 모릅니다.