
私たちが Vela を作り始めたとき、非常に具体的で、少し頑固なくらいの目標がありました。新しい Postgres 環境は、「プロビジョニングしている」と感じないほど速く立ち上がるべきだということです。私たちが意味していたのは「VM の起動としては速い」ではなく、可能な限り速い、ということでした。プラットフォームエンジニアが「ほぼ瞬時」と言えるくらい速く、それでいて完全な分離を保つ必要がありました。
その前提として、私たちには 3 つの制約がありました。
- データベース間の完全な分離。単なる「namespace レベルの分離」ではなく、明確で硬い境界が必要でした。
- noisy neighbor への完全な耐性。CPU、RAM、ディスク I/O に対して厳密なリソース制限をかける必要がありました。
- Kubernetes ネイティブなスケーラビリティ。自動配置と、停止を伴わない置き換え(live migration)が必要でした。
Vela の最初の目標は簡単でまっすぐに見えるかもしれませんが、実際には驚くほど難しいものでした。Vela のすべてのデータベース(branch)は、強い分離と、独立して動的にスケールする能力を持ちます。つまり Kubernetes 上のデータベースらしい振る舞いをしながら、分離保証は仮想マシン並みでなければならなかったのです。
この記事では、そこからどうやって 10 秒未満のブートにたどり着いたのか、その過程を紹介します。しかも、データベース間の完全な分離と、Kubernetes の中で自然に機能するスケーリング動作を保ったままです。その途中で、KubeVirt のモデルとその癖、VM のオートスケーリングが pod のオートスケーリングと微妙に違う理由、そして小さなカスタム OS イメージがほとんどどんなチューニングフラグよりも大きな性能レバーになり得る理由を学びました。
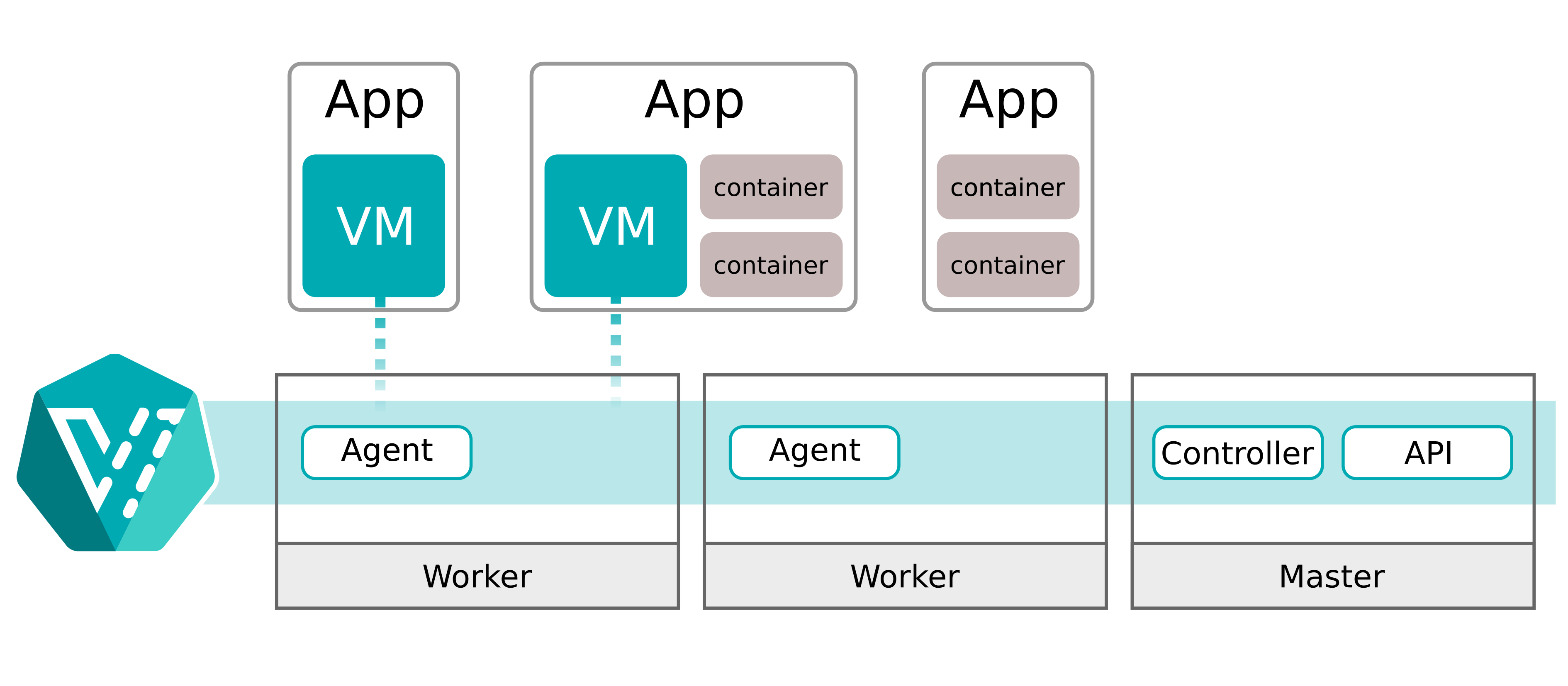
なぜ仮想マシンを選んだのか
最初に VM を選んだ理由は、ひとつの実務的な判断でした。VM の live migration は、すでに解かれている問題だからです。ほとんどのハイパーバイザが対応しており、成熟度の面でもコンテナの live migration より一歩先にあります。もちろん、コンテナ移行の試み(たとえば zeropod)も見ましたが、私たちの制約には合いませんでした。ゼロまでスケールダウンするような動きはうまく扱えても、接続を切らさない live migration という要求は満たせなかったのです。
Kubernetes もまた、妥協できない前提でした。多くのプラットフォームチームにとって、Kubernetes は「土台」であり、それ以外のものはスケジューリング、可観測性、運用ライフサイクルの中に統合されることが期待されます。
そこで私たちは、当然の選択をしました。Postgres を VM の中で動かしつつ、その VM 自体は Kubernetes オブジェクトとして制御する、という方法です。KubeVirt はまさにそのために設計されています。Kubernetes API に VM タイプを追加し、QEMU/KVM を起動する pod を通じて VM のペイロードを動かします。
最初の試み: KubeVirt、Docker、そして苛立たしいブート時間
Kubernetes 上の仮想マシン? それなら KubeVirt です。私たちも、他のみんなと同じようにそう答えました。そんなに難しいはずがない、と。
最初の実装では、調子の良い日で約 2 分、悪い日には最大 5 分かかっていました。十分に瞬時ですよね? 🫣
VM 自体のブート時間は、実のところそれほど悪くありませんでした。問題は、VM の起動が始まりにすぎなかったことです。VM の中で Docker(Compose)を立ち上げ、branch ごとに複数のコンテナイメージを pull して load していました。つまり Postgres、PGBouncer、PostgREST など、各 branch に必要なサービス一式です。Docker Hub のスロットリングと「image pull の運試し」は、非常に厳しい tail latency の原因になりました。
ブートの流れはこうでした。
- Kubernetes が KubeVirt の VM リソースを作成する
- VM リソースが QEMU を起動する
- ゲスト OS が起動する
- Docker サービスが利用可能になる
- Docker が個別のコンテナイメージをダウンロードする
- Docker が依存関係グラフに従ってコンテナを順番に起動する
- コンテナが立ち上がり healthy になる
- branch を active(healthy)としてマークする
VM が起動するたびに毎回イメージをダウンロードするのが最適でないことは分かっていましたが、ここまで悪いとは思っていませんでした。主な問題は、Docker がイメージのダウンロードとコンテナの起動をどう処理するかにあります。基本的には最初に全イメージをダウンロードし、その後で依存関係グラフに従って起動します。巨大なイメージや、スロットリングで遅いイメージがひとつあるだけでアウトです。イメージが増えるほど、悪い日を引く確率も上がっていきます。
最終的に、レイテンシを増幅していた要素は大きく 3 つありました。影響の大きい順に並べるとこうです。
- サービス用イメージを取得するための image pull と registry throttling
- VM と、その中の Docker コンテナという二段構えの起動
- DNS 名の登録、新しいディスクの用意、Postgres の initdb 実行などの追加セットアップ
Docker イメージを事前にキャッシュしよう
まず、毎回ダウンロードする問題を消す必要がありました。ブートパスに「依存関係をダウンロードする」が含まれているなら、それはブート時間ではありません。確率分布です。
どうせ VM イメージをビルドしているのだから、そのビルドの中で必要なコンテナイメージを全部事前にダウンロードしてしまえばいいのではないか、という話になりました。
そうして実際にやりました。つまり、必要な Docker イメージを全部ダウンロードし、それを最終的な仮想マシンのブートイメージの中に同梱するステップを build プロセスに追加しました。
これはとてもよく効きました。ブート時間のばらつきの最大要因が消えたのです。だいたい 90〜100 秒でかなり安定するようになりました。とはいえ、Linux イメージの起動と Docker サービスが使えるようになるまでを待つ時間には、まだ多くを費やしていました。実際の branch サービスを立ち上げるのはその後です。それでも最初の一歩としては十分でした。典型的な Linux イメージを起動するのではなく、ブート手順そのものを最適化すれば、まだ余地があると分かっていました。
なぜ Docker だったのか
よく聞かれた疑問のひとつが、「そもそも、なぜ VM の中で Docker を使ったのか?」というものです。
短い答えは一語です。便利だったからです。
長い答えは、異なる Docker イメージを使い、Pgpool-II や PGBouncer のような候補サービスを試しながら、より速い反復サイクルを回せたからです。
VM を毎回作り直さずに実験できる余地が必要で、その時点では Docker が最適解でした。しかもデータベースのアップグレードも非常に簡単になるはずでした。Postgres のメジャーアップグレードでは、新バージョンと現行バージョンの両方が必要です。Docker ならそれはダウンロードひとつ分の距離でした。新しいバージョンのベースイメージを使い、ブート後に古いバージョンをすぐに取得し、マイグレーションを実行して、古いコンテナイメージを消す。それで終わりです。
とはいえ、ほかのレイテンシ要因に戻る前に、別の問題がこちらへにじり寄ってきました。
KubeVirt がつまずき始めたとき
ここは明確にしておきたいのですが、以下の問題は単純に「KubeVirt が悪い」という話ではありません。 実際、KubeVirt は非常に難しい問題を解いており、それをきわめて Kubernetes らしい形で実現しています。
ただし、私たちが目指していた振る舞い、つまり高速・高頻度・弾力的で、しかもデータベースらしい VM は、システムの別の部分に負荷をかけていました。それは典型的な「長寿命 VM」ではなく、用途がずっと変わらないワークロードでもありませんでした。KubeVirt は、Kubernetes の利便性と典型的な VM のライフサイクル、隔離を得たい場合には素晴らしいです。しかし私たちはそこから外れており、その差が見え始めたのです。
仮想マシンのスケーリングは pod のスケーリングではない
最初の摩擦点は、CPU と RAM の VM リソーススケーリングが、私たちにとって珍しい操作ではなかったことです。できるだけ頻繁に、できるだけ速く、動的にスケールアップとスケールダウンをしたかったのです。可能なら scale-to-zero まで含めて。
KubeVirt では、こうした変更が即座に live migration を引き起こします。たとえ現在のホストに十分な余力があっても、です。最大の痛みは、live migration が常に VM を別の Kubernetes worker へ移してしまうことでした。live migration 自体の性能影響は限定的とはいえ、VM を絶えず動かし続けるのは受け入れられませんでした。
“Current hotplug implementation involves live-migration of the VM workload.” KubeVirt Authors, “Memory Hotplug” documentation (KubeVirt.io)
典型的な VM ライフサイクルであれば、この設計判断は確かに理にかなっています。しかし私たちにとっては、あらゆる「リサイズ」が「世界を動かすこと」になり、ネットワークの複雑化やデータベース接続維持の問題へと波及してしまいました。
本当にリソースが不足したときだけ live migration を行い、それ以外は CPU と RAM のローカルなスケールアップ/スケールダウンを可能にする仕組みが必要でした。
live migration と TCP セッションは相性が悪い
さらに私たちは、もっと厳しい真実にもぶつかりました。live migration が「シームレス」になるのは、ネットワークスタックと migration パイプラインが、ワークロードが前提としている不変条件を保てるときだけです。Postgres クライアントは長い停止を許してくれません。
データベースはレイテンシに敏感で、接続指向です。内部テストでは、ごく小さな途切れでも、継続的な接続テストの最中にはすぐ可視化されることが分かりました。passt のような提案された解決策は多少役に立ちましたが、中程度から高負荷の pgbench では依然として接続断が起きました。
そして、これは私たちだけの問題でもなさそうでした。KubeVirt には、migration 後のネットワーク問題に関する公開 issue やコミュニティの議論があります。たとえば、migration 後に masquerade インターフェースで接続性が壊れることがある という古くからの報告があります。別のメンバーは、migration 中に pod/network identity が変わることで接続が失われる と説明しています。
私たちに必要だったのは、本物の overlay networking でした。
二重のリソース会計: Pod と VM
もうひとつの落とし穴は、リソース制御がスタックの複数レイヤーで行われることでした。
- 仮想マシンのレベルは、QEMU が VM に対して利用可能だと認識しているものです。
- Pod/Cgroup のレベルは、Kubernetes が virt-launcher(QEMU)pod に対して実際に強制するものです。
私たちの実験では、CPU とメモリの割り当ては VM と pod の両レベルで適切に管理しなければならないことが分かりました。pod 側だけを更新すると VM 内で out-of-memory が発生しました。これは先ほど触れたスケーリングの問題とつながっています。
この問題の一部を緩和し、live resizing を可能にするために、私たちは KubeVirt を迂回して libvirt を使い、VM を直接更新しなければなりませんでした。ただし、システムを壊さないように注意が必要でした。KubeVirt の仮想マシンリソースに対するリコンシリエーションが一度でも走れば、そうした「手動」の更新は無効になるからです。
もっと安全なやり方が必要でした。
次へ進む時が来た
私たちは何度も、サポートされた API サーフェスにきれいに収まらない workaround が必要になる場面に遭遇しました。そして次のリコンシリエーションがそれを元に戻してしまうのです。KubeVirt をパッチするには大きな作業が必要で、これほど中心的なプロジェクトの長期 fork を抱えたくはありませんでした。
そこで私たちはこう自問しました。
- 「KubeVirt は Kubernetes 向け仮想化 API として優れているか?」 はい。
- 「KubeVirt は 私たちの branch lifecycle と scaling model にとって良い抽象化か?」 私たちはそうは思いませんでした。
そこで私たちは、オープンソースを作る人間らしく動きました。要件により近い別のアプローチを探したのです。基本的な選択肢は 2 つでした。よりよい既存の解決策を見つけるか、あるいは目的特化でゼロから全部書くかです。
最初は libvirt や QEMU の上に自前の抽象化を作ることも考えました。しかし KubeVirt のソースコード規模を見て、必要な機能を切り出して設計していくうちに、目の前にあるスコープの大きさを実感しました。
仮想マシンと Kubernetes を結婚させるのは、本当に大変な仕事です。多くの概念が食い違い、それを再び統合しなければならないからです。私たちは怖くなりました。だからこそ、まず別の解決策を探すことにしたのです。私たちの要件にもっと近いものを。そして運よく、それが見つかりました。
方向転換: Neon の Autoscaling を採用する
より良い解決策が見つかるなら、それを探すのが賢い方法です。そして、私たちはそうしました。
アプローチは単純で、考えてみれば当然でした。近い領域の会社とその解決策を見ることです。幸運なことに、世の中には多くのデータベースがあります。多くがオープンソースで、多くが Postgres 関連です。
Neon の Autoscaling プロジェクトを見つけたとき、私たちは上で挙げた制約にぶつかった最初の人たちではないことにも気づきました。彼らも同じような問題に直面し、それを解くために自分たちのソリューションを書いていました。Neon のアプローチは徹底してデータベース型でした。K8s 管理下の micro-VM(QEMU ベース)の中で Postgres を縦方向にオートスケールさせる ために設計されていたのです。しかも一番難しい部分、つまり 「リソース変更やワークロード移動時に TCP セッションを壊さない」 ところまで解いていました。
Autoscaling で最も興味深いのは、スケーリング判断がどう下され、実際のスケーリングがどう機能するかです。
まず、Autoscaling は CPU とメモリの利用報告のために Cgroups を使ってリソース範囲を定義します。「ホスト」(ゲスト VM)の利用状況を把握するために、Prometheus 経由で収集したメトリクスを利用します。数秒ごとに現在の利用状況を評価し、スケールアップまたはスケールダウンが必要か判断します。さらに、仮想マシン内のエージェントがプロアクティブにスケーリング要求を出すこともできますが、それが拒否されることもあります。
Autoscaling は内部で QEMU を使っているため、CPU とメモリを hot-plug できます。つまり実行中に必要に応じて CPU コアを仮想マシンへ追加・削除できます。メモリも同様で、virtio-mem デバイスを使って実行時に追加・削除します。Linux カーネルは、virtio-mem デバイスを取り外す前に、その対象メモリ領域を移動させて空にします(memory ballooning に近い動きです)。
“We want to dynamically change the amount of CPUs and memory of running Postgres instances, without breaking TCP connections to Postgres.” Neon Autoscaling README (GitHub)
Autoscaling の構成要素
Autoscaling 自体は、Kubernetes 上で serverless Postgres を実現するために連携する複数のコンポーネントからできています。
- 仮想マシンリソース(CRD)を管理する controller(neonvm-controller)
- ノード容量を評価し、VM の配置と置き換えを判断する scheduler
- VM のリソース使用量を収集して報告する per-node agent(daemonset)
- ワークロードの横で動き、Prometheus 経由で使用状況を報告する VM monitor(cgroup 固有設定つき)
- Flannel と組み合わせて、仮想ネットワークインターフェースと overlay networking により継続的な接続性を確保する VXLAN manager
- VM を包み込み、VM イメージの提供、QEMU の起動、DHCP/port forwarding、mount の管理を行う runtime image
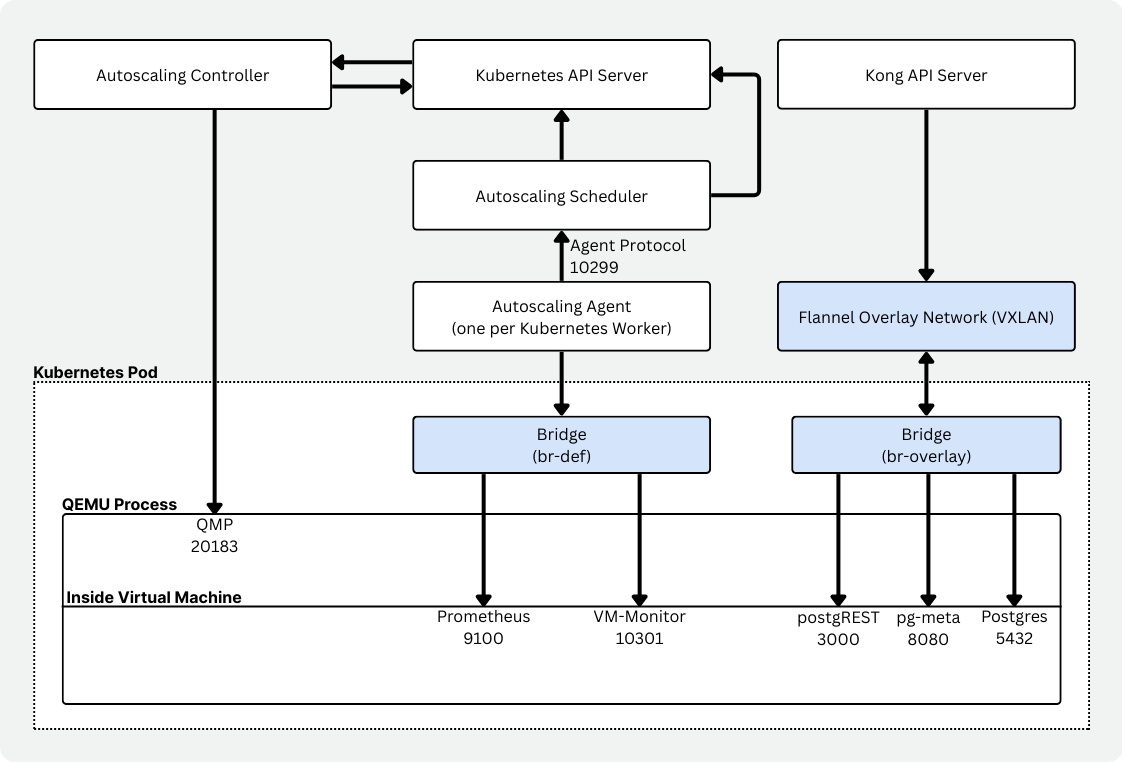
ここにも同じ概念的な分割が見えます。カスタム scheduler、ノードごとの autoscaling-agent、そしてメモリ圧力に即応できる vm-monitor です。Vela にとって、これははるかに良いフィットでした。
Autoscaling を作ってくれた Neon チームに感謝します。
それでも変更は必要だった
ただ、Autoscaling がかなり私たちのニーズに合っていたとはいえ、Neon と Vela の実装の違いからくるいくつかの「粗いところ」は残っていました。
まず、基盤ストレージとして simplyblock を使っている都合上、仮想マシンに 1 つまたは複数の PVC(Persistent Volume Claim)をアタッチできる必要がありました。
次に、CPU と RAM の利用を制限しつつ、その上限を live update できるようにしたいと考えました。残念ながら、QEMU はあらかじめアタッチ可能な最大 CPU と RAM を知っている必要があります。私たちには、実際にユーザーがそこまでスケールするとは思っていなくても、その値をかなり大きく設定する必要がありました。そこで意思決定プロセスに soft limit を追加しました。現在の VM は 128 vCPU、256 GB メモリという hard limit を持っています。一方で soft limit は、たとえば 8 vCPU や 16 GB メモリのような、現時点で許可する最大スケーリング範囲を表します。soft limit を超える要求は拒否されます。
最後に、単純な PowerState を追加しました。これにより CRD の値を更新するだけで仮想マシンを起動・停止できます。純粋な利便性のためです。
ブート時間に勝つ: 「VM 内の Docker」を殺す
Autoscaling がライフサイクルとスケーリングの大きな摩擦を解消した後、ようやく本当の問題に戻ることができました。ブート時間です。真の突破口は、自分たちに正直になったことでした。スタートアップでやっていたことは、率直に言って愚かでした。私たち自身の都合を、ユーザー体験より優先していたのです。汎用 Linux ディストリビューションを起動し、その上で Docker を起動し、さらに複数サービスをコンテナイメージ経由でオーケストレーションしていました。そこで私たちは、その内側のコンテナ層をまるごと取り除きました。
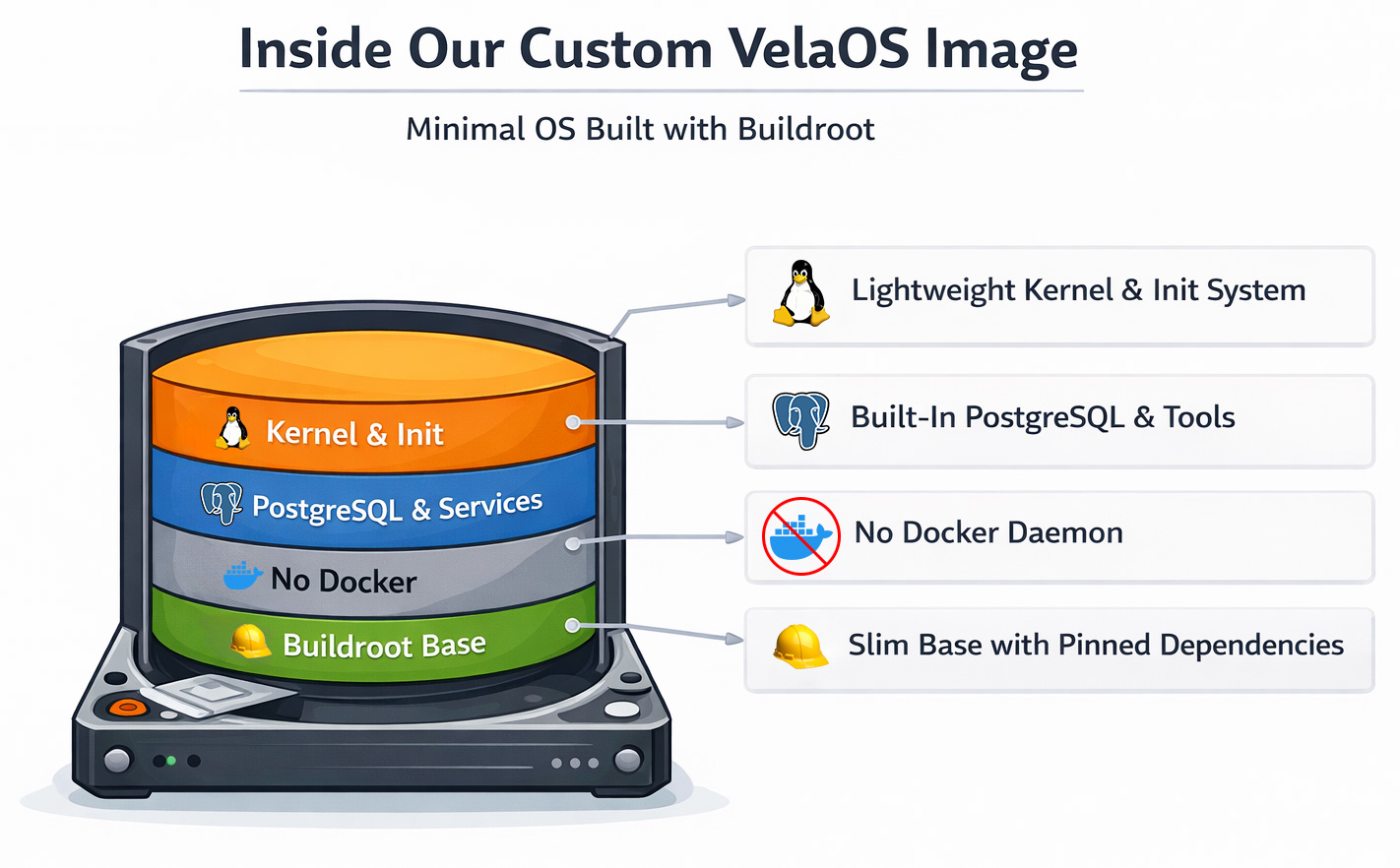
VelaOS: Buildroot ベースのカスタム Linux kernel と rootfs
私たちは Buildroot ベースのカスタム Linux イメージ に移行しました。Buildroot は Linux カーネルと最小限の root filesystem を構築するためのフレームワークです。もともとは組み込み機器向けですが、read-only filesystem イメージや device updater などもサポートしています。
Buildroot という名前自体はあまり聞いたことがないかもしれませんが、実際には広く使われている仕組みです。分かりやすい利用例としては OpenWRT や Home Assistant OS(HAOS)、さらには Google Fiber のような組み込み機器ベンダーがあります。Buildroot は最小サイズの root filesystem で知られています。
Buildroot に切り替えたことで、Docker を消した以上のいくつかの素早い成果が得られました。
- ブートプロセスが決定的になった。inittab をベースの init システムとして使い、何をいつ起動するかを正確に制御できるようになりました。
- Docker pull が不要になった。必要なサービスはすべてブートイメージに組み込まれています。
- ブート速度が向上した。汎用 OS イメージではなく、最適化した Linux kernel を使うからです。
- 再現可能なビルド。各コンポーネントを特定のバージョンやコミット、チェックサムに固定し、改変されていないコンポーネントだけをビルドできるようになりました。
一方で、開発速度は落ちました。Buildroot はフレームワークとして、最終イメージの多くの部品を自分でビルドします。その代わりに非常に小さなディスクイメージを作れますが、代償はビルド時間です。それでも CCache やその他の最適化によって、十分に扱える範囲に収まりました。
結果として、ブートパスはとても単純になりました。
- Kubernetes が autoscaling scheduler の判断に従って VM pod をスケジュールする
- runtime が私たちの VM イメージで QEMU を起動する
- guest が、必要なサービスがすでに入った最小 OS を起動する
- Postgres と branch を支えるサービス群が即座に立ち上がる(ダウンロードなし)
まだ改善の余地はあります。それでも現時点では、<10 秒で十分に良いと考えています。Vela の価値は、「branch がすばやく現れ、一貫して振る舞い、しっかり分離する」ことにあります。
分離とスケーラビリティ: なぜ今でも Kubernetes らしく感じられるのか
当然の疑問があります。「KubeVirt を離れて独自の VM プラミングを使い始めたなら、Kubernetes の使いやすさを失ったのでは?」
実際には、私たちは Kubernetes の大事な部分を維持しています。CRD と controller による宣言的な制御はそのままです。desired state は引き続き reconciliation されます。スケジューリングも Kubernetes によって行われ、配置は autoscaling scheduler と agent に影響されます。ノードレベルのリソース制約は、実際のノード容量と VM の利用状況に基づく配置・スケーリング・migration 判断の根拠になります。そして最後に、各データベース branch がそれぞれ独立した VM 境界を持つことで、分離境界が実現されます。
しかもそのすべてを維持しながら、既存の Postgres 接続を壊さずに Vela branch をある Kubernetes worker から別の worker へ完全 live migration する可能性も残しています。
高速ブートは control plane の機能でもある
しかし 10 秒未満のブートは、単にユーザー体験の話ではありません。それは、何をどう作るかそのものも変えます。
- Vela はより攻めたスケールアップができます。容量追加が安価だからです。複数 VM による水平スケールでも、VM limit の live-resizing による垂直スケールでも同じです。
- Vela は環境を ephemeral として扱えます。再作成コストが低く、ストレージとコンピュートが完全に分離されているからです。
- Vela は障害を修復ではなく VM の置き換えで吸収できます。
それは、最終的にユーザー、エージェント、CI ワークフローに待ち時間を感じさせずにサービスを提供できるシステムの形です。
学んだこと: 思っているより常に複雑だ!
「VM vs コンテナ」が本当の論点ではない。重要なのはブートパスの決定性だ。
私たちは良い理由から VM で始めました(migration の成熟度、強い分離)。しかし最悪の遅延は、私たち自身の「便利さ」と「速い試行錯誤」への執着から来ていました。Docker の起動と image pull です。「起動時にイメージを pull する」をやめた瞬間、time-to-ready は賭けではなくなりました。
Kubernetes の reconciliation は味方でもあり敵でもある。
もし自分が「reconciler を回避するように動いている」と気づいたら、それは意図された拡張モデルの外にいるサインだと考えるべきです。サポートされるパターンへ寄せるか、自分の制御要件に合う substrate を選ぶべきです。
最速の最適化は、たいてい何かを取り除くことだ。
最速のコードが「そもそも実行されないコード」であるのと同じように、最速の最適化は不要な部品を除くことです。私たちの場合、Docker Compose と image pull を丸ごと取り除いたことで、数分単位のばらつきが消えました。
live migration は単一の機能ではなく、ひとつの製品面そのものだ。
KubeVirt と Autoscaling は migration に対する考え方が大きく異なります。KubeVirt ではほぼあらゆる CPU やメモリ変更が live migration につながるのに対し、Autoscaling はできるだけ既存 VM 上で処理し、物理リソースが不足したときだけ migration します。もうひとつ大きい違いは、Kubernetes のネットワークプレーンに対する小手先の hack ではなく、本物の overlay network によって安定した network identity を得ていることです。データベース的なワークロードなら、「migrated された」というイベントはクライアントから見えないものでなければなりません。そうでないと reconnect storm と tail latency との戦いに人生を費やすことになります。
最小限の OS イメージは速いだけではない。運用上のエントロピーを減らしてくれる。
小さく目的特化したイメージは、可動部が少ないです。つまり意外な相互作用が少なく、裏で「親切なこと」をするデーモンも少なく、問題発生時のデバッグ面も小さくなります。Buildroot ベースの VelaOS によって、私たちは再現可能なビルドと、いつどの VM に何が入っているのか(データを除いて)を厳密に把握できる手段も得ました。
怖がることを怖がらなくていい。ときには、それが良い結果につながる。
自前の KubeVirt 代替を作ることを検討したとき、そのスコープは本当に恐ろしいものでした。その恐ろしさがあったからこそ、既存の別解を調べる時間を取ったのです。そしてそれが Autoscaling へと私たちを導きました。怖がったことを、私たちはよかったと思っています。
KubeVirt は Kubernetes エコシステムにとって重要な仕事をしている。
仮想マシンを Kubernetes に持ち込む最初の一歩を KubeVirt が踏み出していなければ、私たちは今日ここにいなかったかもしれません。明示的に言う価値があります。KubeVirt はエコシステムにとって重要な仕事をしています。私たちが限界にぶつかった箇所でも、プロジェクトは今も活発に進化しています。たとえば migration targeting や resize coupling に関する改善は、#15625 のような issue で追跡されています。また KubeVirt は、クラウド環境で Cluster Autoscaler と共存させるような現実的な統合例の文書化も続けています。
次に目指したいこと
私たちはこれを「KubeVirt vs Neon Autoscaling」とは見ていません。Kubernetes 上で VM を動かす方法は複数あり、最適な選択はワークロードの形によって変わります。
KubeVirt は Kubernetes 向けの強力で汎用的な仮想化レイヤーであり、私たちも引き続きその進展を注意深く追っています。
ただし Vela の主要な目標、つまり強い分離を持つ高速で一時的なデータベース branch のためには、データベース向けに徹底的に最適化された control plane と runtime path が必要でした。
Neon の Autoscaling が適切な土台を提供し、Vela OS がブート時間を予測可能にしてくれました。
この領域で何かを作っているなら、あなたの経験や判断、追加の edge case についてぜひ話したいです。特に networking、migration の挙動、VM イメージ設計について。
近いうちに、私たちが加えた改善を upstream し始める予定です。私たちは健全なオープンソース・エコシステムを信じており、変更を私有化するのではなく共有したいと考えています。
Vela の Postgres インスタンスを試したい場合は、https://demo.vela.run で無料アカウントを作成してください。Vela は完全にオープンソースであり、自社データセンターやプライベートクラウドでの self-hosting を前提にしています。現時点ではコードベースを整理し、残るバグを修正し、ユーザー向けのインストール手順を整備しているところです。