
短く言うと、クエリが遅いとき多くの人はまずインデックスを考えます。PostgreSQL には multi-column、partial、expression index など多くの選択肢があります。ただし、インデックスが増えるほどストレージも書き込みコストも増えます。そこで見落とされがちなのが CREATE STATISTICS です。拡張統計は、ほぼ無視できるストレージコストでプラン改善を助けてくれます。
多くの悪いプランで本当の問題は、planner が怠けていることではありません。単にデータ分布の見積もりが間違っているのです。複数の述語が相関していると、列単位の統計だけでは足りません。そこに拡張統計が入ってきます。
短いまとめ
CREATE STATISTICS は、通常の列単位統計では表現しにくい追加情報を Postgres に収集させる仕組みです。
特に役立つのは次のような場面です。
- 複数列にまたがる相関フィルタ、
- 複数列の distinct 推定、
- 偏りの強い値の組み合わせ、
- 本来 expression index を貼りたくなるような式。
–-- Alternative to index on expressions CREATE STATISTICS stats_expr ON (date_trunc(‘day’, created_at)) FROM events; --- What people normally mean by --- extended statistics CREATE STATISTICS stats_multi (dependencies, ndistinct, mcv) ON plan_tier, region, billing_status FROM tenants; |
前者は date_trunc や JSONB 抽出のような式統計に向いています。後者が、多くの人が「extended statistics」と聞いてイメージする形です。
重要な種類は dependencies、ndistinct、mcv の 3 つです。そして通常の統計と同じく、CREATE STATISTICS は定義だけであり、実際に値を集めるのは ANALYZE です。
なぜ拡張統計が必要なのか
Postgres はデフォルトでは主に列ごとの統計を持っています。これは単一列の独立したフィルタにはよく効きます。しかし、列同士の関係性が重要になると問題が出ます。
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
実際のデータでは、こうした条件はしばしば相関しています。しかし追加統計がないと PostgreSQL は各条件が独立に行数を減らすとみなします。その結果、数学的には整っていても、運用上はかなり間違った推定になります。
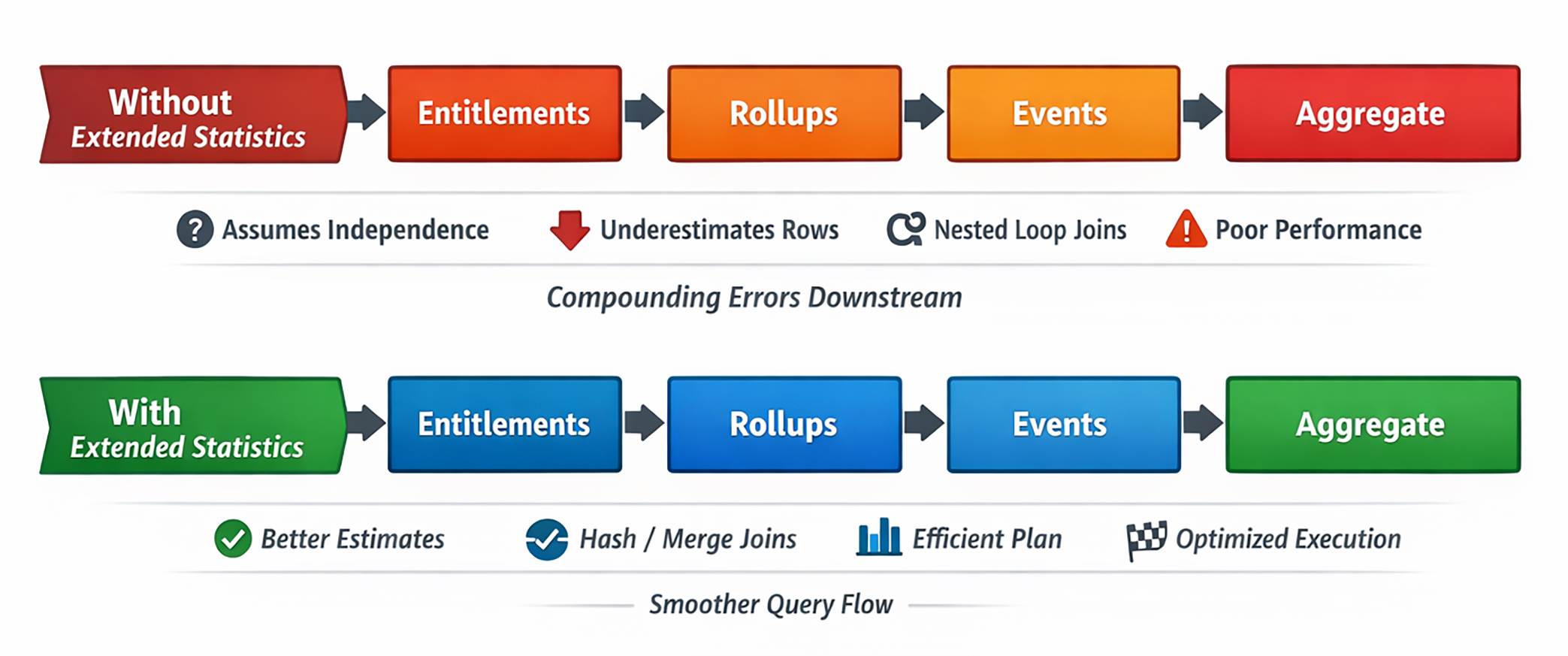
しかも最初の推定が間違うと、その後の join 順序、join 手法、並列化、hash サイズ、sort 戦略、spill リスクまで全部が揺らぎます。
Postgres が標準で知っていること
ANALYZE のたびに、PostgreSQL は各列について null 率、ヒストグラム、頻出値、distinct 数などを保存します。便利ではありますが、あくまで列単位の知識です。
たとえば 100 万行のテーブルで次のような分布があるとします。
plan_tier = 'enterprise'は 6 %region = 'eu-central'は 25 %billing_status = 'active'は 80 %
1,000,000 * 0.06 * 0.25 * 0.80 = 12,000 rows |
しかし現実には、これらの列は独立していないことが多いのです。真の結果は 40,000 行かもしれないし、60,000 行かもしれないし、5,000 行かもしれません。単一列統計だけではわかりません。
拡張統計のベンチマーク
これを具体的に示すために、私はかなり現実的な SaaS analytics workload を模した 4 テーブル構成を作りました。tenants、tenant_entitlements、usage_rollups、analytics_events です。
データセットは、まさに planner の弱点が出るように意図的に形作っています。料金プラン、リージョン、請求状態の相関、premium entitlement の偏り、そしてランダムではない (tenant, feature, day) の分布です。
もちろん合成データではありますが、それは風洞実験のような意味での合成です。実在する現象を切り出して観測するための制御されたデータです。
データの形で問題を切り分ける
テーブル: tenants
料金プラン、リージョン、請求状態は、実際の SaaS データでよくあるように相関しています。
テーブル: tenant_entitlements
sso、audit_logs、workflows のような premium feature は enterprise tenant に集中させています。
テーブル: usage_rollups
ここでは tenant-feature ごとの時間方向の fanout を現実的に表現しています。
テーブル: analytics_events
ここが高カーディナリティの爆発点です。条件に合う tenant-feature ごとに大量の生イベント行が存在し得ます。
レポート用クエリ
ビジネス上の問いはシンプルです。「重要なリージョンにいる active な enterprise tenant の中で、どの premium feature が最近最も使われたか?」
SELECT e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.region = 'eu-central' AND t.billing_status = 'active' AND te.entitlement IN ('sso', 'audit_logs') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY e.feature_name ORDER BY rolled_requests DESC; |
複数リージョンを見る場合は、CTE と後段の集計を足した拡張版を使います。
WITH regional_feature_totals AS ( SELECT t.region, e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') AND te.entitlement IN ('sso', 'audit_logs', 'workflows') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY t.region, e.feature_name ) SELECT region, feature_name, total_events, rolled_requests FROM ( SELECT region, feature_name, total_events, rolled_requests, row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank FROM regional_feature_totals ) ranked WHERE regional_rank <= 3 ORDER BY region, regional_rank; |
クエリの形を分解する
ステージ 1: tenant slice を定義する
WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') |
Postgres がこの最初の母集団を間違えると、その後の fanout 全体が誤った前提に立ってしまいます。
ステージ 2: 利用権のある feature に絞る
JOIN tenant_entitlements te ON te.tenant_id = t.id ... AND te.entitlements IN (...) |
entitlement テーブルは単なる join 相手ではなく、相関した feature フィルタとしても働きます。
ステージ 3: 直近利用をひも付ける
JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement ... AND r.rollup_day >= CURRENT_DATE - 30 |
ここから multiplicity が始まります。1 つの tenant は複数の entitlement を持ち、1 つの tenant-feature 組には複数日の rollup が存在し得ます。
ステージ 4: 生イベントへ展開する
JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name ... AND e.event_type IN (...) |
この時点で行数見積もりが悪いと痛みが表面化します。Nested Loop が安く見えても、実際にはそうでないことが多いからです。
ステージ 5: 爆発した中間結果を再び縮める
GROUP BY e.feature_name ORDER BY rolled_requests DESC |
GROUP BY t.region, e.feature_name |
最終結果は小さくても、そこに至る仕事量は小さくありません。これがこのクエリを planner の教材として優秀にしている理由です。
ステージ 6: multi-region クエリでのランキング
row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank ... --- followed by WHERE regional_rank <= 3 |
ここではさらに sort と temp I/O の圧力が増えます。このクエリは join と集約の問題であるだけでなく、ranking の問題でもあります。
拡張統計が効く場所
こうした問題を見ると、まず multi-column index や partial index を足したくなります。ここではその代わりに、planner の誤った前提を修正する 3 つの統計オブジェクトを作ります。
- tenant 列の相関、
- tenant と entitlement の組み合わせ、
- rollup の組み合わせ。
当然ながら、作成後には ANALYZE が必要です。
種類: dependencies
Functional dependency 統計は、ある列が別の列を強く予測するため、独立とみなすのが誤りだと PostgreSQL に教えます。
- 国は通貨を強く予測する。
- 州はタイムゾーンを強く予測する。
- tenant セグメントは entitlement の傾向を強く予測する。
CREATE STATISTICS stats_tl_segment_dependencies (dependencies) ON id, plan_tier, region, billing_status FROM tenants; |
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
覚え方としては、dependencies は「これらのフィルタは独立ではない」を修正する機能です。
種類: mcv
MCV は “most common values” ですが、拡張統計では “most common combinations” と考えたほうがわかりやすいです。
CREATE STATISTICS stats_tl_segment_mcv (mcv) ON plan_tier, region, billing_status FROM tenants; |
これにより PostgreSQL は、ある組み合わせが特に多い、特に少ない、あるいはそもそも存在しないといった事実を学習できます。覚え方としては、mcv は「この組み合わせは平均とは違う」を修正します。
種類: ndistinct
ndistinct は、各列ごとの distinct 数ではなく、複数列の組み合わせとして何通り存在するかを PostgreSQL に教えます。
CREATE STATISTICS stats_tel_entitlement_ndistinct (ndistinct) ON tenant_id, entitlement FROM tenant_entitlements; CREATE STATISTICS stats_url_feature_ndistinct (ndistinct) ON tenant_id, feature_name, rollup_day FROM usage_rollups; |
覚え方としては、ndistinct は「この group や join の組み合わせは planner が思うほど多くない」を修正します。
PostgreSQL が実際に保存するもの
ここが面白いところです。もちろん、これらの問題を追加インデックスで解決しようとすることもできます。ただしインデックスは維持コストもストレージコストも高いです。
一方、拡張統計は驚くほど安価です。定義は pg_statistic_ext に、収集データは pg_statistic_ext_data に保存されます。
pg_statistic_extは統計オブジェクトの定義を持ちます。pg_statistic_ext_dataは実際のデータを持ちます。
今回のベンチマークでは、全統計オブジェクトのフットプリントは約 2,059 バイトでした。
- Tenant-Segment
mcv: 約 1,049 バイト - Tenant-Segment
dependencies: 約 518 バイト - Entitlement
ndistinct: 約 220 バイト - Rollup
ndistinct: 約 272 バイト
つまり、巨大な影のインデックスではなく、planner をあまり間違えさせないための軽いメタデータです。
Execution Plan を改善する
このブログを書き始めたとき、最初に示したかったのはランタイム改善でした。もちろん改善はありましたが、もっと重要だったのは見積もり精度の改善です。
| Scenario | Average Time | Worst Estimate | Additional Storage |
|---|---|---|---|
| Extended statistics | 2,857.896 ms | 48.27x | 2.0 KiB |
| Baseline + Composite Join-Key Indexes | 5,882.659 ms | 106.48x | 37.64 MiB |
| Baseline + Events (feature_name, event_type, tenant_id) | 4,781.551 ms | 108.7x | 31.45 MiB |
| Baseline + Partial Hot-Path Indexes | 4,765.351 ms | 106.22x | 30.20 MiB |
| Extended Statistics + Partial Hot-Path Indexes | 4,876.187 ms | 46.65x | 30.21 MiB |
各クエリは 5 回実行しました。実行計画や各回の結果は repository に置いてあります。
単一リージョンクエリ
ベースラインのスキーマでは単一列インデックスを使っています。完全なシーケンシャル実行は避けられますが、tenants、entitlements、rollups、events にまたがる相関を planner はまだ推測しなければなりません。
| Metric | Value |
|---|---|
| Average execution time | 14,168.174 ms |
| Average planning time | 4.134 ms |
| Execution samples | 31,093.955 ms, 29,065.788 ms, 3,564.811 ms, 3,570.114 ms, 3,546.200 ms |
| Planning samples | 5.058 ms, 3.952 ms, 8.969 ms, 1.899 ms, 0.793 ms |
| Join chain | Nested Loop:Inner -> Nested Loop:Inner -> Nested Loop:Inner |
| Scan nodes | Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Nested Loop: 178,389 estimated / 18,774,720 actual (105.25x) |
| Worst estimate path | Sort -> Aggregate -> Nested Loop |
拡張統計を入れると次のようになります。
| Metric | Value |
|---|---|
| Average execution time | 2,857.896 ms |
| Average planning time | 3.025 ms |
| Execution samples | 4,318.854 ms, 2,612.261 ms, 2,396.848 ms, 2,467.702 ms, 2,493.816 ms |
| Planning samples | 6.719 ms, 2.067 ms, 2.128 ms, 2.243 ms, 1.970 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Hash: 12,966 estimated / 625,824 actual (48.27x) |
| Worst estimate path | Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash |
ここで planner は、途中結果が小さいと信じ込むのをやめます。重要な点として、推定総コストはむしろ上がります。これは悪化ではなく、PostgreSQL がやっと現実的なコストを信じ始めたことを意味します。
複数リージョンクエリ
multi-region 版では実行時間の改善がさらに明確でした。
ベースライン:
| Metric | Value |
|---|---|
| Average execution time | 24,933.705 ms |
| Average planning time | 3.648 ms |
| Execution samples | 84,815.859 ms, 12,696.190 ms, 11,819.487 ms, 8,482.936 ms, 6,854.054 ms |
| Planning samples | 6.125 ms, 5.681 ms, 2.067 ms, 2.181 ms, 2.187 ms |
| Join chain | Merge Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Sort: 53,580 estimated / 17,164,496 actual (320.35x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Merge Join -> Sort |
拡張統計あり:
| Metric | Value |
|---|---|
| Average execution time | 7,289.319 ms |
| Average planning time | 2.875 ms |
| Execution samples | 7,503.924 ms, 8,261.715 ms, 7,433.035 ms, 8,181.565 ms, 5,066.357 ms |
| Planning samples | 9.244 ms, 0.932 ms, 1.039 ms, 1.801 ms, 1.359 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Nested Loop: 68,387 estimated / 1,113,566 actual (16.28x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash -> Nested Loop |
これは小さな調整ではありません。PostgreSQL がようやく現実と同じ郵便番号に戻ってきた、というレベルの差です。
本当に速くなったのか?
場合によります。だからこそ、この話題は丁寧に扱う価値があります。
単一リージョンの実行時間
- ベースライン平均: 14,168.174 ms
- 拡張統計平均: 2,857.896 ms
見た目は劇的ですが、ベースラインの最初の 2 回が極端に遅いためです。慎重に言えば、planner の理解が改善し、この workload では steady-state でも好影響が出た、ということです。
複数リージョンの実行時間
- 統計のみ: 7,289.319 ms
- 最良の index-only 戦略: 6,886.473 ms
これは CREATE STATISTICS の価値を否定しません。統計は cardinality 推定を改善し、インデックスは物理アクセス経路を提供する、という違いを明確にしているだけです。
なぜインデックス比較が重要なのか
興味深かったのは、インデックスを多く追加したケースではコストやランタイムが魅力的に見えても、推定品質では大きく劣ることがあった点です。
- 拡張統計: 約 2.0 KiB
- インデックス重視の代替案: 約 30.20 MiB から 37.64 MiB

これが見落とされがちなポイントです。約 2 KiB のメタデータで PostgreSQL は大幅に「間違いにくく」なり、一方で index-heavy な代替案は数十 MiB を消費しても planner 問題そのものは解決しない場合があります。
「両方使う」が自動的に勝たなかった理由
もちろん、「拡張統計と最適なインデックスを両方使えばさらに良いのでは?」という問いも試しました。
結果は、必ずしもそうではありませんでした。
Single-region:
- 統計のみ: 2,857.896 ms
- 統計 + Partial Hot-Path Indexes: 4,876.187 ms
Multi-region:
- 統計のみ: 7,289.319 ms
- 統計 + Partial Hot-Path Indexes: 8,950.207 ms
インデックスが増えると、選択肢が増えるだけでなく planner の探索空間そのものも変わります。つまり「両方使えば勝つ」は自然法則ではなく、やはりベンチマークの対象です。
実務上の注意点
明示しておくべき制約はいくつかあります。
- 拡張統計は 単一の relation の中 でしか機能しません。
- PostgreSQL はこれを テーブルをまたぐ join selectivity 推定 に直接は使いません。
- すべての workload が恩恵を受けるわけではありません。列が本当に独立なら効果は小さいです。
- 良いクエリ設計、有用なインデックス、パーティショニング、適切なメモリ設定、高速ストレージを置き換えるものではありません。
これは planner により良い情報を与えるための機能であって、万能な性能お守りではありません。
CREATE STATISTICS を検討すべきタイミング
実務的なルールは単純です。プランが明らかにおかしく見え、その違和感が複数列のフィルタやグルーピングを planner がうまくモデル化できていないことにありそうなら、反射的に新しいインデックスを作る前に extended statistics を考えてみるべきです。
良い候補は次の通りです。
- 強く相関したフィルタ列、
- セグメント依存の属性、
- 明らかに cardinality が外れている group-by workload、
- multi-column fanout の問題、
- 頻出値の歪んだ組み合わせ、
- 単一 relation の悪い推定が残り全体を汚染するケース。
逆に向かないのは、物理アクセス経路が足りないだけのケース、明らかな I/O ボトルネック、そして列が本当に独立しているケースです。
EXPLAIN (ANALYZE, VERBOSE, BUFFERS) を使い、estimated rows と actual rows が大きく乖離しているなら、extended statistics を試す価値があります。
小手先よりも真実を優先する
CREATE STATISTICS の一番良いところは、データにさらに構造を積み増すよりも、planner に真実を与えるところです。
このベンチマークが言っているのは、「拡張統計は常に勝つ」ではありません。もっと有用なことです。
- PostgreSQL を大幅に“間違いにくく”した。
- プラン形状を意味のある方向に変えた。
- ストレージコストはほぼ無視できた。
- そして多くの場合、何十 MiB もの追加インデックスより直接的に planner の問題を解いた。
ベンチマーク、クエリ、結果は GitHub にあります。Vela Postgres Sandbox でも自分で試せます。
そしてもし、プランを見て「この join が三重に trench coat を着てネストされている必要なんてないだろう」と思ったことがあるなら、あなたが探していた機能は extended statistics かもしれません。