
Quand nous avons commencé à construire Vela, nous avions un objectif très précis, et un peu têtu : un nouvel environnement Postgres devait être prêt si vite qu’il ne devait même pas donner l’impression d’un “provisioning”. Nous ne voulions pas dire “rapide pour le boot d’une VM”, nous voulions dire aussi vite que possible. Assez vite pour que les platform engineers parlent de livraison instantanée, tout en gardant une isolation complète.
Cela dit, nous avions trois contraintes :
- Isolation complète entre les bases avec de vraies frontières dures, pas une simple “isolation au niveau du namespace”.
- Résilience totale aux noisy neighbors avec des limites strictes sur le CPU, la RAM et l’activité disque.
- Scalabilité native Kubernetes avec placement automatique et remplacement sans interruption (live migration).
Même si l’objectif initial de Vela paraît simple et direct, il a été terriblement difficile à atteindre. Chaque base de données (branche) dans Vela reçoit une forte isolation et la capacité à se mettre à l’échelle de façon dynamique et indépendante. Cela ressemble à ce qu’une base de données sur Kubernetes devrait être, mais avec les garanties d’isolation d’une machine virtuelle.
Ce billet raconte comment nous sommes passés de là à des démarrages en moins de 10 secondes, tout en conservant une isolation complète entre les bases et un comportement de scalabilité qui fonctionne naturellement dans Kubernetes. En chemin, nous avons beaucoup appris sur le modèle de KubeVirt (et ses arêtes vives), sur la raison pour laquelle l’autoscaling des VM est subtilement différent de l’autoscaling des pods, et sur le fait qu’une toute petite image d’OS personnalisée peut être un levier de performance bien plus puissant que presque n’importe quel flag de tuning.
Pourquoi nous avons choisi les machines virtuelles
Au départ, nous avons choisi les VM pour une raison pragmatique : la live migration des VM est un problème résolu. Elle est prise en charge par la plupart des hyperviseurs et reste nettement plus mature que la live migration des conteneurs. Nous avons bien regardé des travaux autour de la migration de conteneurs (par exemple zeropod), mais cela ne collait pas à nos contraintes. Même si cela gère bien la scalabilité, y compris jusqu’à zéro, cela ne répondait pas à notre exigence de migration sans interruption.
Kubernetes n’était pas non plus négociable. Pour la plupart des équipes plateforme, Kubernetes est “le substrat”, et tout le reste est censé s’intégrer à son scheduling, son observability et son cycle de vie opérationnel.
Nous avons donc fait ce qui semblait évident : exécuter Postgres dans des VM tout en les contrôlant comme des objets Kubernetes. C’est précisément ce pour quoi KubeVirt a été conçu : étendre l’API Kubernetes avec des types de VM et exécuter la charge de la VM via un pod qui lance QEMU/KVM.
Première tentative : KubeVirt, Docker et des boots frustrants
Des machines virtuelles sur Kubernetes ? C’est KubeVirt. Comme tout le monde, c’était aussi notre réponse. À quel point cela pouvait-il être difficile ?
Notre première itération démarrait en environ 2 minutes les bons jours et jusqu’à 5 minutes les mauvais jours. Suffisamment instantané, non ? 🫣
Les timings du boot de la VM elle-même n’étaient même pas si mauvais. Mais démarrer la VM n’était que le début. Nous démarrions Docker (Compose) à l’intérieur de la VM, puis nous tirions et chargions plusieurs images de conteneur par branche, essentiellement tous les services de chaque branche (Postgres, PGBouncer, PostgREST, …). Le throttling de Docker Hub et la “loterie des image pulls” se sont révélés être une source brutale de latence en queue.
Le processus de boot était rude :
- Kubernetes crée les ressources de VM KubeVirt
- La ressource VM démarre QEMU
- Le système invité démarre
- Le service Docker devient disponible
- Docker télécharge les différentes images de conteneur
- Docker démarre les conteneurs un par un selon le graphe de dépendances
- Les conteneurs montent et deviennent healthy
- Nous marquons la branche comme active (healthy)
Nous savions que télécharger les images à chaque démarrage de VM n’était pas optimal, mais nous ne nous attendions pas à ce que ce soit à ce point mauvais. Le problème principal tient à la manière dont Docker gère le téléchargement des images et le démarrage des conteneurs. En gros, il télécharge d’abord toutes les images, puis les démarre selon le graphe de dépendances. Une image volumineuse ou lente (car bridée) suffit à tout gâcher. Et plus on ajoute d’images, plus la probabilité d’avoir une mauvaise journée augmente.
Globalement, nous avons identifié trois composants qui amplifiaient la latence, classés par ordre d’impact (du plus fort au plus faible) :
- Les image pulls et le throttling du registre pour rendre disponibles les images des services de branche.
- Le démarrage en deux niveaux avec la VM et les conteneurs Docker.
- Les étapes de setup supplémentaires, comme l’enregistrement du nom DNS, le provisioning d’un nouveau disque, l’exécution de l’initdb de Postgres, et ainsi de suite.
Pré-cache des images Docker
La première chose à faire était d’éliminer le problème du téléchargement systématique. Si ton chemin de démarrage inclut “télécharger des dépendances”, alors tu n’as pas un temps de boot. Tu as une distribution de probabilités.
Nous construisions déjà une image de VM, alors pourquoi ne pas “simplement” pré-télécharger toutes les images nécessaires pendant le processus de build ?
Aussitôt dit, aussitôt fait. Nous avons donc adapté le processus de build pour y inclure une étape qui télécharge toutes les images Docker nécessaires et les intègre dans l’image finale de démarrage de la machine virtuelle.
Cela a très bien fonctionné. La plus grande source de variabilité au démarrage avait disparu. Nous sommes arrivés à une base assez stable de 90 à 100 secondes. Beaucoup de temps restait néanmoins consacré au démarrage de l’image Linux et à l’attente du service Docker avant de pouvoir enfin lancer nos vrais services de branche. C’était suffisant pour un premier tir. Mais nous savions qu’il restait du potentiel d’optimisation, non pas en démarrant une image Linux classique, mais en optimisant la procédure de boot elle-même.
Pourquoi Docker ?
Une question qui revenait régulièrement était : « Pourquoi diable avoir utilisé Docker à l’intérieur de la VM ? »
La réponse courte tient en un mot : la commodité.
La réponse longue, c’est la commodité de cycles d’itération plus rapides grâce à l’utilisation de différentes images Docker et au test de différentes options de services (comme Pgpool-II, PGBouncer et d’autres).
Nous avions besoin de pouvoir expérimenter sans reconstruire les machines virtuelles, et Docker était alors la solution parfaite. Cela aurait aussi rendu les upgrades de base de données très simples. Pour les upgrades majeurs de Postgres, il faut deux versions installées : la nouvelle et l’actuelle. Avec Docker, cela n’était qu’à un téléchargement de distance. Utiliser l’image de base de la nouvelle version, télécharger rapidement l’ancienne après le boot, lancer la migration puis supprimer l’image de l’ancienne version. Terminé.
Quoi qu’il en soit, avant même de pouvoir revenir aux autres facteurs de latence, nous avons vu d’autres problèmes commencer à nous rattraper.
Quand KubeVirt a commencé à nous freiner
Nous voulons être clairs : aucun des problèmes qui suivent ne se résume à “KubeVirt est mauvais”. En réalité, KubeVirt résout un problème très difficile, et le fait de la manière la plus “Kubernetes” possible.
En revanche, notre comportement cible (des VM rapides, fréquentes, élastiques, au comportement “base de données”) mettait à l’épreuve d’autres parties du système. Ce n’était pas la VM “longue durée” typique qui ne change jamais de cas d’usage. KubeVirt est formidable si l’on veut le confort de Kubernetes avec le cycle de vie et l’isolation classiques d’une machine virtuelle. Nous, en revanche, nous nous éloignions de cet état, et cela a fini par se voir.
Scaler une machine virtuelle, ce n’est pas scaler un pod
Le premier point de friction, c’est que la scalabilité des ressources VM pour le CPU et la RAM n’était pas un cas rare chez nous. Nous voulions pouvoir scaler vers le haut et vers le bas de manière dynamique, aussi souvent et aussi vite que possible. Potentiellement, avec du scale-to-zero.
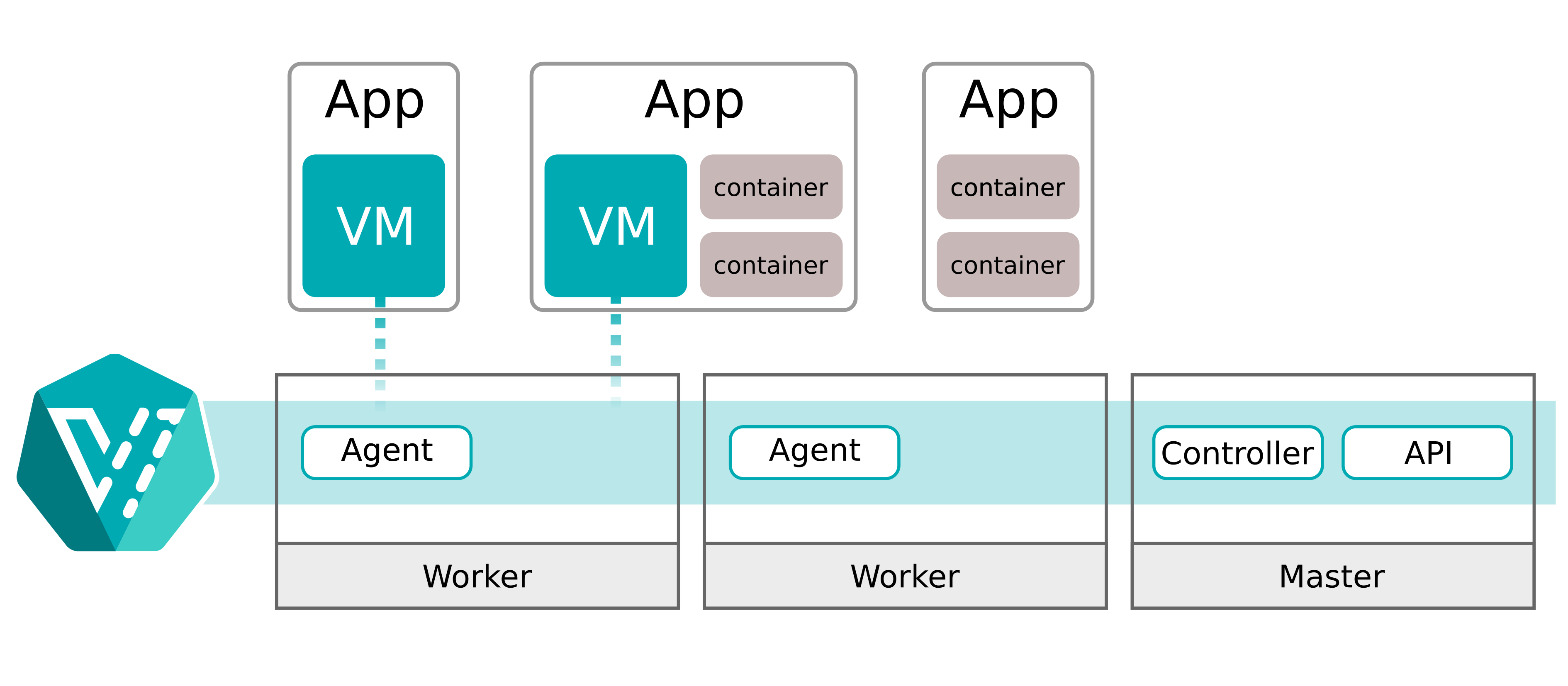
Dans KubeVirt, ces changements déclenchent une live migration immédiate. Même si l’hôte actuel dispose encore de suffisamment de ressources. Le principal problème est que la live migration déplace toujours la VM vers un autre worker Kubernetes. Même si l’impact d’une live migration sur les performances reste limité, déplacer constamment les VM n’était pas acceptable pour nous.
“Current hotplug implementation involves live-migration of the VM workload.” KubeVirt Authors, “Memory Hotplug” documentation (KubeVirt.io)
Pour un cycle de vie typique de VM, cette décision de conception est parfaitement logique. Mais pour nous, cela signifiait qu’un simple “resize” devenait un “on déplace tout”, avec des effets en cascade sur la complexité réseau et la durabilité des connexions à la base.
Nous avions besoin d’une solution qui ne live-migre la machine virtuelle que lorsqu’aucune ressource n’est disponible, et qui permette du scale up/down local pour le CPU et la RAM.
Live migration et sessions TCP : une combinaison brutale
Nous avons aussi découvert une vérité plus dure : la live migration n’est “transparente” que si la pile réseau et le pipeline de migration préservent les invariants supposés par le workload. Les clients Postgres ne pardonnent pas les longues pauses.
Les bases de données sont sensibles à la latence et orientées connexion. Nos tests internes ont montré que même les plus petites discontinuités deviennent rapidement visibles pendant des tests de connexion soutenus. Des solutions suggérées comme passt ont allégé une partie du problème, mais sous une charge pgbench modérée à forte, nous observions toujours des coupures de connexion.
Et il semble que nous n’étions pas seuls. KubeVirt a des issues publiques et des discussions communautaires autour de problèmes réseau post-migration. Par exemple, un rapport ancien explique qu’après migration, la connectivité peut casser sur l’interface masquerade. D’autres membres de la communauté ont décrit la perte de connexions parce que l’identité sous-jacente du pod/réseau change pendant la migration.
Nous avions besoin d’un vrai overlay networking.
Double comptabilité des ressources : pod vs VM
Autre piège : le contrôle des ressources a lieu à plusieurs niveaux dans la stack.
- Le niveau de la machine virtuelle correspond à ce que QEMU pense mettre à disposition de la VM.
- Le niveau pod/cgroup correspond à ce que Kubernetes impose au pod virt-launcher (QEMU).
Dans nos expérimentations, nous avons constaté que les allocations CPU et mémoire devaient être gérées efficacement au niveau VM et au niveau pod. Mettre à jour uniquement le niveau pod provoquait des problèmes d’out-of-memory dans la VM. C’est lié au problème de scalabilité mentionné plus haut.
Pour atténuer une partie du problème et permettre le live resizing, nous avons dû contourner KubeVirt et utiliser libvirt pour mettre à jour les VM directement. Nous devions faire attention à ne pas casser le système, car un seul événement de réconciliation sur une ressource de machine virtuelle KubeVirt invalidait toute mise à jour “manuelle”.
Il nous fallait une manière plus sûre de faire les choses.
Il était temps d’avancer
Nous avons rencontré plusieurs situations dans lesquelles nous avions besoin de contournements qui ne rentraient pas proprement dans la surface d’API supportée, et la réconciliation suivante les annulait. Patcher KubeVirt aurait représenté beaucoup de travail, et nous ne voulions pas porter un fork durable d’un projet aussi central juste pour continuer à avancer.
Nous nous sommes posé les questions suivantes :
- « KubeVirt est-il une bonne API de virtualisation pour Kubernetes ? » Oui, il l’est.
- « KubeVirt est-il une bonne abstraction pour notre cycle de vie de branches et notre modèle de scalabilité ? » Nous pensons que non.
Nous avons donc fait ce que font les builders open source. Nous avons cherché une autre approche qui colle mieux à nos besoins. Et il n’y avait que deux options de base : trouver une meilleure solution existante ou tout écrire from scratch, de manière purpose-built.
Notre première idée était de construire notre propre abstraction au-dessus de libvirt, voire directement sur QEMU. Mais en examinant la taille du code source de KubeVirt et en évaluant les fonctionnalités à reproduire, nous avons compris l’ampleur du chantier.
Marier une machine virtuelle à Kubernetes est un travail difficile. Trop de concepts divergent puis doivent être réintégrés. Cela nous a refroidis. Nous avons donc décidé de chercher d’abord d’autres solutions. Quelque chose de plus proche de nos besoins. Et nous avons eu de la chance.
Le pivot : adopter l’Autoscaling de Neon
La meilleure approche consiste à chercher une autre solution si l’on peut en trouver une qui réponde mieux aux exigences. Et c’est exactement ce que nous avons fait.
L’idée était simple et évidente quand on y pense : regarder les entreprises voisines et leurs solutions. Heureusement pour nous, il existe beaucoup de bases de données. Beaucoup d’open source. Beaucoup liées à Postgres.
Quand nous avons trouvé le projet Autoscaling de Neon, nous avons aussi réalisé que nous n’étions pas les premiers à buter sur les limites décrites plus haut. Ils avaient rencontré beaucoup des mêmes problèmes et choisi d’écrire leur propre solution. L’approche de Neon avait une forme résolument “base de données”. Elle était conçue autour du vertical autoscaling de Postgres dans des micro-VM gérées par K8s (basées sur QEMU). Et ils avaient aussi résolu la partie délicate : “ne pas casser les sessions TCP lorsque l’on change les ressources ou que l’on déplace le workload.”
La partie la plus intéressante d’Autoscaling tient à la manière dont les décisions de scalabilité sont prises et à la manière dont la scalabilité elle-même fonctionne.
D’abord, Autoscaling utilise les cgroups pour borner les ressources (CPU et mémoire) dans le reporting d’usage. Pour capturer l’usage de “l’hôte” (la VM invitée), il s’appuie sur des métriques collectées via Prometheus. Toutes les quelques secondes, l’usage courant est évalué par rapport à d’éventuels événements de scale up ou de scale down. De plus, l’agent à l’intérieur de la VM peut demander proactivement des décisions de scalabilité, même si ces demandes peuvent être refusées.
Comme Autoscaling utilise QEMU sous le capot, CPU et mémoire peuvent être hot-plugged. Autrement dit, à l’exécution, on attache ou détache des cœurs CPU de la machine virtuelle selon les besoins. La mémoire fonctionne de manière similaire, via des dispositifs virtio-mem qui peuvent être ajoutés ou retirés à chaud. Le noyau Linux déplace les régions mémoire à supprimer afin de libérer un dispositif virtio-mem avant son détachement (un peu comme avec le memory ballooning).
“We want to dynamically change the amount of CPUs and memory of running Postgres instances, without breaking TCP connections to Postgres.” Neon Autoscaling README (GitHub)
Les composants d’Autoscaling
Autoscaling est lui-même un ensemble de composants qui coopèrent pour permettre du Postgres serverless sur Kubernetes.
- Un contrôleur (neonvm-controller) pour gérer les ressources de machines virtuelles (CRDs).
- Un scheduler qui évalue la capacité des nœuds et prend les décisions de placement et de remplacement des VM.
- Un agent par nœud (daemonset) qui collecte et remonte l’usage des ressources des VM.
- Un moniteur de VM qui tourne aux côtés du workload et remonte l’usage via Prometheus avec une configuration spécifique aux cgroups.
- Un gestionnaire VXLAN qui garantit une connectivité durable avec des interfaces réseau virtuelles et de l’overlay networking (avec Flannel).
- Une image runtime qui encapsule la VM. Elle met l’image de VM à disposition, démarre QEMU, gère DHCP/port forwarding et les mounts.
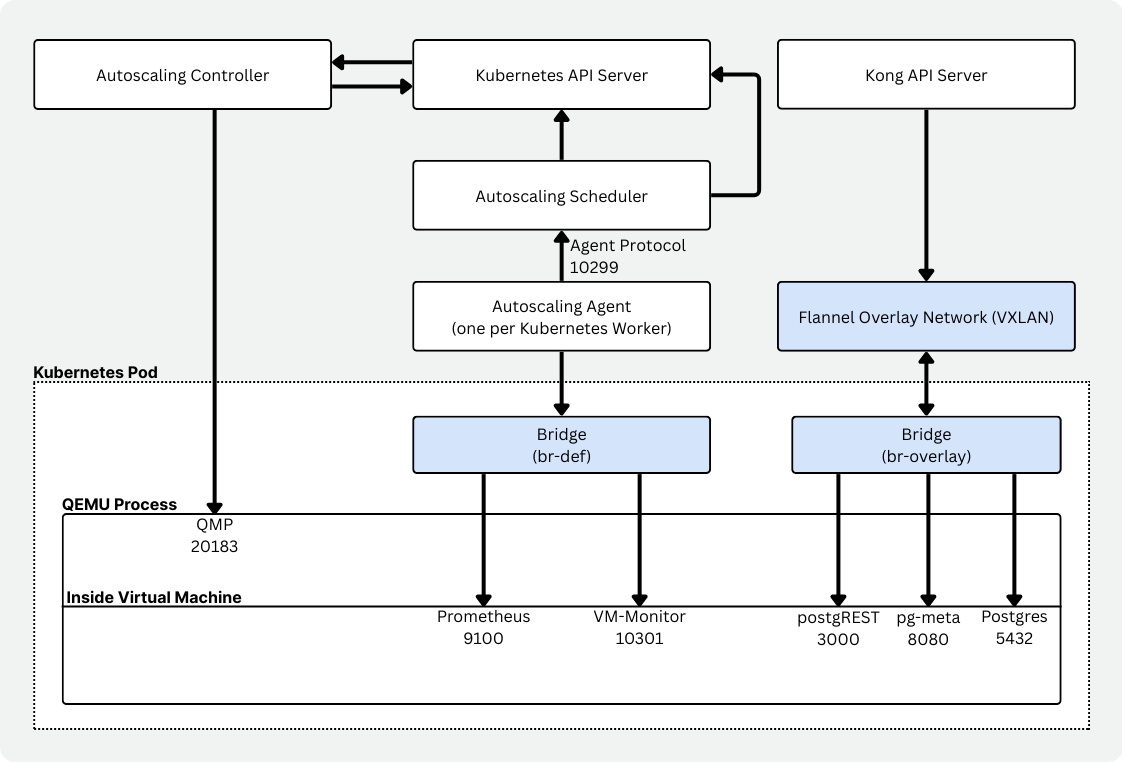
On y retrouve le même découpage conceptuel : un scheduler personnalisé, un autoscaling-agent par nœud et un vm-monitor capable de réagir immédiatement à la pression mémoire. Un bien meilleur ajustement pour Vela.
Merci à l’équipe Neon derrière Autoscaling pour ce travail remarquable.
Des changements restaient nécessaires
Mais même si Autoscaling collait déjà très bien, il restait quelques “angles rugueux” liés aux différences d’implémentation entre Neon et Vela.
D’abord, avec simplyblock comme couche de stockage principale, nous avions besoin de pouvoir attacher un ou plusieurs PVC (Persistent Volume Claims) à la machine virtuelle.
Ensuite, nous voulions limiter l’usage CPU et RAM sans perdre la possibilité de mettre à jour ces limites à chaud. Malheureusement, QEMU doit connaître le maximum de CPU et de RAM pouvant être attachés à un instant donné. Nous avions besoin que ces valeurs soient bien plus élevées que ce à quoi nous nous attendions réellement en production. Nous avons donc ajouté un soft limit au processus de décision. Les VM actuelles ont une limite dure de 128 vCPU et 256 Go de mémoire. Le soft limit, lui, décrit les maxima de scalabilité effectivement autorisés, comme 8 vCPU ou 16 Go de mémoire. Les demandes au-delà de ces soft limits sont refusées.
Enfin, nous avons ajouté un simple PowerState qui nous permet de démarrer ou d’arrêter la machine virtuelle en modifiant simplement cette valeur dans la CRD. Pur confort.
Gagner sur le boot time : tuer le “Docker dans la VM”
Une fois qu’Autoscaling a résolu une grande partie des frictions de cycle de vie et de scalabilité, il était temps de revenir au vrai sujet : le temps de boot. Le véritable tournant est venu quand nous avons été honnêtes avec nous-mêmes. Ce que nous faisions au démarrage était franchement stupide. Nous avions choisi notre confort à nous plutôt que l’expérience utilisateur. Nous démarrions une distribution généraliste, puis Docker, puis plusieurs services orchestrés via des images de conteneur. Nous avons donc supprimé toute cette couche interne de conteneurs.
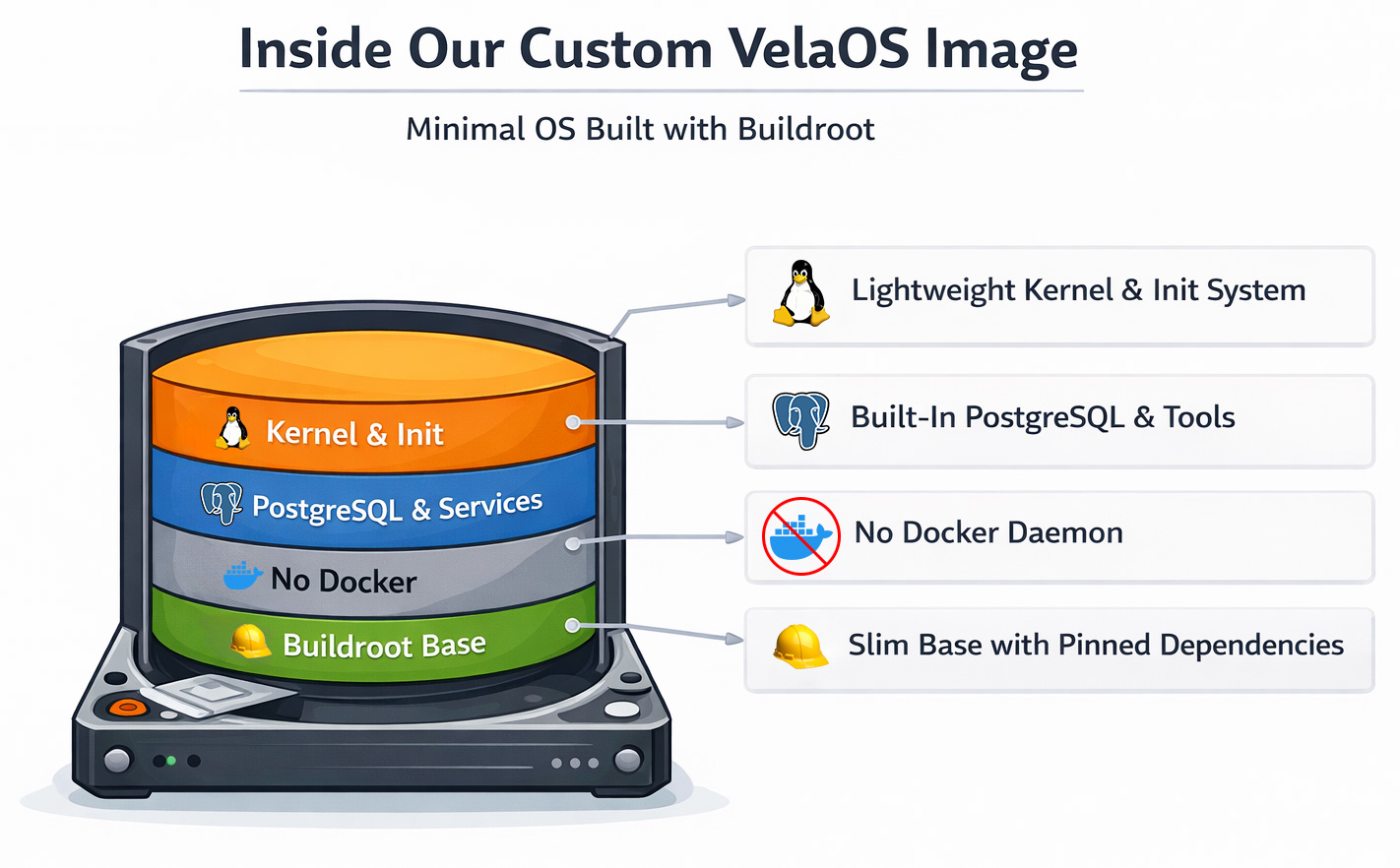
VelaOS : un noyau Linux et un rootfs personnalisés sur base Buildroot
Nous sommes passés à une image Linux custom basée sur Buildroot. Buildroot est un framework servant à construire des noyaux Linux et un système de fichiers racine minimal. Initialement pensé pour les appareils embarqués, il gère des images de systèmes de fichiers en lecture seule, des updaters matériels, etc.
Même si tu n’as peut-être jamais entendu parler directement de Buildroot, c’est en réalité un système largement utilisé. Parmi ses utilisateurs connus figurent OpenWRT, Home Assistant OS (HAOS) ainsi que des fabricants d’appareils embarqués comme Google Fiber. Buildroot est réputé pour ses root filesystems de taille minimale.
Le passage à Buildroot nous a apporté plusieurs gains rapides en plus de la suppression de Docker :
- Le processus de boot est devenu déterministe grâce à l’utilisation de inittab comme système init de base pour contrôler exactement ce qui démarre, et quand.
- Plus de Docker pulls, puisque tous les services sont intégrés à l’image de boot.
- Une vitesse de boot supérieure, car nous n’utilisons pas une image d’OS généraliste, mais un noyau Linux optimisé.
- Des builds reproductibles, chaque composant étant épinglé à une version ou un commit précis avec checksum, ce qui garantit que seuls des composants non modifiés sont construits.
En contrepartie, nous avons perdu en vitesse d’itération. Buildroot, en tant que framework de build, construit lui-même la plupart des composants de l’image finale. Cela lui permet d’obtenir des images disque incroyablement petites, au prix du temps de build. Grâce à CCache et à d’autres techniques d’optimisation, cela reste toutefois gérable.
Le chemin de boot résultant est simple :
- Kubernetes schedule le pod de VM (via les décisions du scheduler Autoscaling).
- Le runtime démarre QEMU avec notre image de VM.
- Le guest démarre un OS minimal avec les services déjà installés.
- Postgres et les services de branche associés montent immédiatement (sans téléchargement).
Il reste de la marge d’amélioration. Mais pour l’instant, nous pensons que <10 secondes est suffisamment bon. La valeur de Vela, c’est : “les branches apparaissent vite, se comportent de façon cohérente et isolent vraiment.”
Isolation et scalabilité : pourquoi cela ressemble toujours à Kubernetes
Une inquiétude raisonnable serait : « Si vous avez quitté KubeVirt et commencé à faire votre propre plomberie VM, avez-vous perdu l’ergonomie Kubernetes ? »
En pratique, nous avons conservé les parties de Kubernetes que nous aimons. Nous avons toujours un contrôle déclaratif via des CRD et des contrôleurs qui réconcilient l’état désiré. Le scheduling est implémenté via Kubernetes, le placement étant influencé par le scheduler et l’agent Autoscaling. Les contraintes de ressources au niveau nœud fournissent les éléments nécessaires pour les décisions de placement, de scalabilité et de migration sur la base de la capacité réelle du nœud et de l’usage réel de la VM. Enfin, les frontières d’isolation sont appliquées en faisant de chaque branche de base de données sa propre frontière VM.
Tout cela en préservant la possibilité de live-migrer complètement une branche Vela d’un worker Kubernetes à un autre, sans détruire les connexions Postgres existantes.
Un boot rapide est aussi une fonction du control plane
Mais un boot en moins de 10 secondes n’améliore pas seulement l’expérience utilisateur. Cela change aussi ce que l’on construit, et comment on le construit :
- Vela peut scaler plus agressivement parce qu’ajouter de la capacité coûte peu, horizontalement avec plus de machines virtuelles, et verticalement avec le live-resizing des limites VM.
- Vela peut traiter les environnements comme éphémères parce que le coût de recréation est faible et que le stockage et le compute sont complètement séparés.
- Vela peut absorber les pannes en remplaçant la VM plutôt qu’en la réparant.
C’est la forme d’un système qui pourra un jour servir des utilisateurs, des agents et des workflows CI sans faire attendre l’utilisateur.
Leçons apprises : c’est toujours plus compliqué qu’on ne le pense !
Le débat n’est pas “VMs vs containers”, mais le déterminisme du chemin de boot.
Nous avons commencé avec des VM pour de bonnes raisons (maturité des migrations, isolation forte), mais nos pires délais venaient de notre propre amour du confort et de l’itération rapide. Le démarrage de Docker et les pulls d’images. À partir du moment où nous avons supprimé “tirer des images au boot”, le temps jusqu’à disponibilité a cessé d’être un pari.
La réconciliation Kubernetes est à la fois amie et ennemie.
Si tu te retrouves à “travailler autour du reconciler”, considère cela comme le signe que tu es hors du modèle d’extension prévu, et rapproche-toi soit de patterns supportés, soit choisis un substrat adapté à tes besoins de contrôle.
L’optimisation la plus rapide consiste le plus souvent à retirer des choses.
De la même façon que le code le plus rapide est celui qui n’est jamais exécuté, l’optimisation la plus rapide consiste à enlever des composants inutiles. Dans notre cas, supprimer complètement Docker Compose et les image pulls a supprimé plusieurs minutes de variabilité.
La live migration n’est pas une feature unique, mais toute une surface produit.
KubeVirt et Autoscaling abordent la migration de manière très différente. Chez KubeVirt, presque tout changement de CPU ou d’allocation mémoire finit en live migration ; Autoscaling, lui, essaie d’en faire le plus possible sur l’instance VM existante, et ne migre que lorsque les ressources physiques deviennent rares. L’autre grande différence, c’est une identité réseau stable obtenue grâce à un vrai réseau overlay plutôt qu’à des hacks sur le plan réseau Kubernetes. Si ton workload est de type base de données, l’événement “ça a migré” doit être invisible pour les clients, sinon tu passeras ta vie à te battre contre les tempêtes de reconnexion et la tail latency.
Les images d’OS minimales ne servent pas seulement à aller plus vite. Elles réduisent l’entropie opérationnelle.
Une petite image construite pour un objectif précis contient moins de pièces mobiles. Cela veut dire moins d’interactions surprenantes, moins de démons de fond faisant des choses “utiles”, et une surface de debug plus petite quand quelque chose tourne mal. Avec VelaOS, basé sur Buildroot, nous avons aussi obtenu des builds reproductibles et la possibilité de certifier précisément ce qui se trouve dans la VM à un instant donné (à l’exception des données).
N’aie pas peur d’avoir peur. Parfois cela mène à un excellent résultat.
Quand nous avons étudié la construction de notre propre alternative à KubeVirt, l’ampleur de la tâche faisait peur. Assez peur pour que nous prenions le temps de rechercher d’autres solutions déjà existantes. C’est ce qui nous a conduits à Autoscaling. Et nous sommes heureux d’avoir eu cette peur.
KubeVirt accomplit un travail important pour l’écosystème Kubernetes.
Sans KubeVirt, qui a fait les premiers pas pour apporter les machines virtuelles à Kubernetes, nous ne serions peut-être pas là aujourd’hui. Il vaut la peine de le dire explicitement : KubeVirt fait un travail important pour l’écosystème. Même là où nous avons rencontré des limites, le projet continue d’évoluer activement. Par exemple, la communauté KubeVirt suit elle-même des améliorations autour du ciblage de migration et du couplage avec le resize, comme on le voit dans des issues telles que #15625. Et KubeVirt continue de documenter des intégrations du monde réel, comme son fonctionnement aux côtés du Cluster Autoscaler dans des environnements cloud.
Là où nous voulons aller ensuite
Nous ne voyons pas cela comme “KubeVirt vs Neon Autoscaling”. Il existe plusieurs manières valides d’exécuter des VM sur Kubernetes, et le meilleur choix dépend de la forme du workload.
KubeVirt est une puissante couche de virtualisation généraliste pour Kubernetes, et nous suivons toujours ses progrès de près.
Pour les objectifs principaux de Vela, comme des branches de base de données éphémères et rapides avec une isolation forte, nous avions besoin d’un control plane et d’un chemin runtime résolument optimisés pour les bases de données.
L’Autoscaling de Neon nous a fourni la bonne fondation, et Vela OS a rendu le boot time prévisible.
Si tu construis quelque chose dans cet espace, nous serions ravis d’échanger sur tes expériences, tes décisions et d’autres edge cases. En particulier autour du networking, du comportement de migration ou du design des images VM.
Dans un futur proche, nous allons commencer à upstreamer les améliorations que nous avons apportées. Nous croyons à un écosystème open source sain et voulons partager ces changements plutôt que les garder privés.
Si tu veux découvrir et tester nos instances Postgres Vela, crée ton compte gratuit sur https://demo.vela.run. Vela est entièrement open source et pensé pour du self-hosting dans ton propre data center ou ton private cloud. En ce moment, nous nettoyons le code, corrigeons les bugs restants et mettons en place la procédure d’installation côté utilisateur.