
Version courte : quand une requête est lente, on pense d’abord aux index. PostgreSQL propose tout ce qu’il faut : multi-colonnes, partiels, index sur expressions. Le problème, c’est le coût. Plus d’espace, plus d’entretien, plus de travail en écriture. Ce que beaucoup négligent, c’est CREATE STATISTICS. Les extended statistics peuvent améliorer fortement le plan avec un coût de stockage presque insignifiant.
Derrière beaucoup de mauvais plans, le vrai problème n’est pas que le planner est “bête”. C’est qu’il prend des décisions logiques à partir d’une image fausse des données. Quand plusieurs prédicats sont corrélés, les statistiques par colonne ne suffisent plus. C’est exactement là que les extended statistics deviennent utiles.
La version courte
CREATE STATISTICS permet à Postgres de collecter des informations supplémentaires que les statistiques classiques par colonne ne savent pas représenter correctement.
En pratique, cela aide surtout pour quatre types de problèmes :
- des filtres corrélés sur plusieurs colonnes,
- des estimations
DISTINCTmulti-colonnes, - des combinaisons de valeurs fortement skewées,
- des expressions pour lesquelles on construirait sinon un index sur expression.
–-- Alternative to index on expressions CREATE STATISTICS stats_expr ON (date_trunc(‘day’, created_at)) FROM events; --- What people normally mean by --- extended statistics CREATE STATISTICS stats_multi (dependencies, ndistinct, mcv) ON plan_tier, region, billing_status FROM tenants; |
La première forme est utile pour des expressions comme date_trunc ou l’extraction JSONB. La seconde est ce à quoi la plupart des gens pensent quand ils parlent d’extended statistics.
Les trois types importants sont dependencies, ndistinct et mcv. Et comme pour les statistiques normales, CREATE STATISTICS ne fait que définir l’objet ; c’est ANALYZE qui remplit réellement les données.
Pourquoi les extended statistics ?
Par défaut, PostgreSQL stocke surtout des statistiques par colonne. Cela fonctionne bien tant que les filtres peuvent être traités de façon indépendante. Le problème apparaît dès que les relations entre colonnes comptent.
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
Dans les données réelles, ce type de prédicats est souvent corrélé. Sans statistiques supplémentaires, PostgreSQL se comporte pourtant comme si chaque filtre réduisait indépendamment la population. Le résultat est une estimation mathématiquement nette, mais opérationnellement absurde.
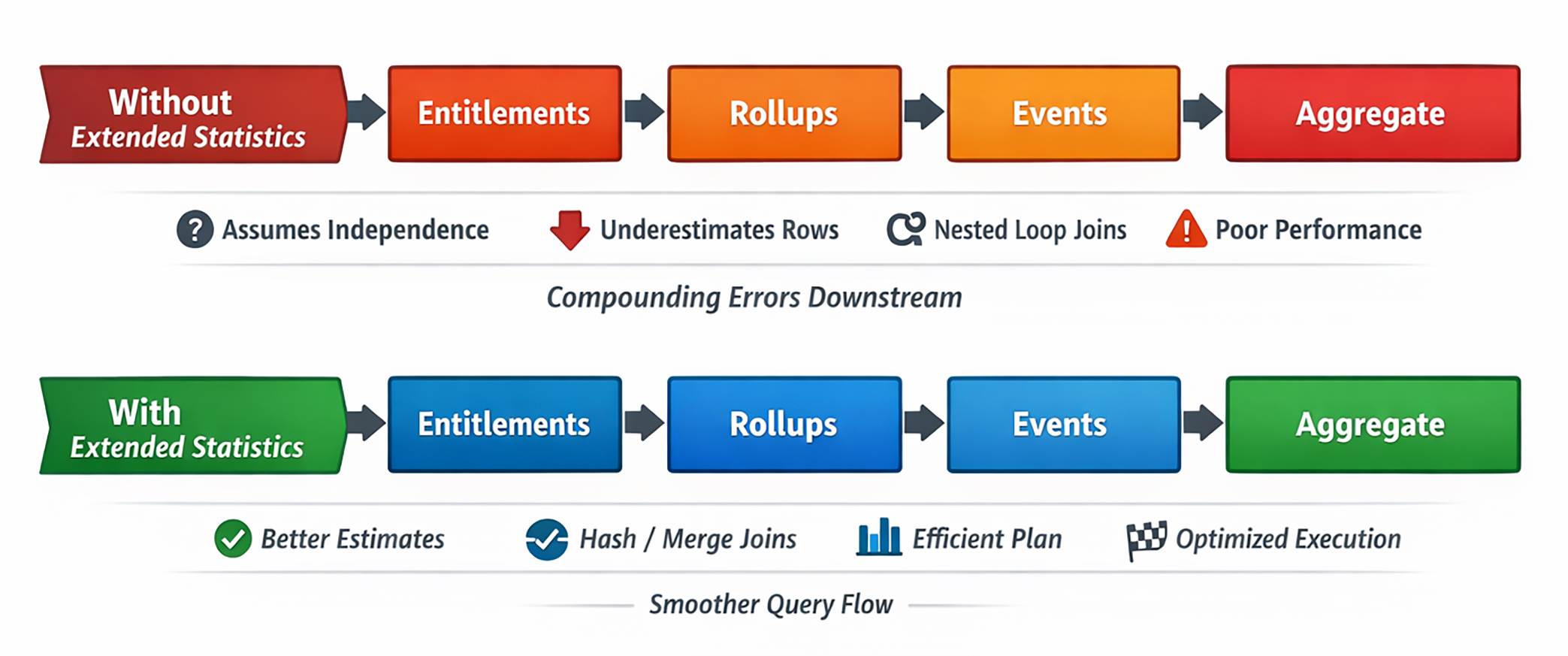
Et une fois que l’estimation est mauvaise au début, tout devient instable : ordre des joins, type de join, parallélisme, taille des hash, stratégie de tri, risque de spill.
Ce que Postgres sait par défaut
À chaque ANALYZE, PostgreSQL enregistre pour chaque colonne des informations comme les fractions de nulls, les histogrammes, les valeurs fréquentes ou les cardinalités. Tout cela est utile, mais reste local à une seule colonne.
Imaginons une table d’un million de lignes avec cette distribution :
plan_tier = 'enterprise'touche 6 %region = 'eu-central'touche 25 %billing_status = 'active'touche 80 %
1,000,000 * 0.06 * 0.25 * 0.80 = 12,000 rows |
Le souci est que ces colonnes ne sont pas indépendantes dans la vraie vie. La vraie réponse peut être 40 000, 60 000 ou 5 000 lignes. Les statistiques mono-colonne ne peuvent pas le savoir.
Benchmarking des extended statistics
Pour rendre cela concret, j’ai construit une charge analytique SaaS synthétique mais volontairement réaliste avec quatre tables : tenants, tenant_entitlements, usage_rollups et analytics_events.
Le dataset a été façonné pour exposer précisément les angles morts du planner : corrélations entre plan, région et statut de facturation, concentration des entitlements premium et distributions non aléatoires de (tenant, feature, day).
Oui, le jeu de données est synthétique. Mais synthétique au sens d’une soufflerie : contrôlé pour isoler un phénomène réel.
Isoler le problème par la forme des données
Table : tenants
Les colonnes de segmentation sont corrélées de façon très proche de ce qu’on observe souvent dans les données SaaS.
Table : tenant_entitlements
Les fonctionnalités premium comme sso, audit_logs ou workflows sont beaucoup plus concentrées chez les tenants enterprise.
Table : usage_rollups
Cette table modélise un fanout temporel réaliste par combinaison tenant-feature.
Table : analytics_events
C’est la table d’explosion de cardinalité : beaucoup d’événements bruts pour chaque combinaison qui survit aux filtres précédents.
La requête de reporting
La question métier est simple : « parmi les tenants enterprise actifs d’une région importante, quelles fonctionnalités premium génèrent le plus d’activité récente ? »
SELECT e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.region = 'eu-central' AND t.billing_status = 'active' AND te.entitlement IN ('sso', 'audit_logs') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY e.feature_name ORDER BY rolled_requests DESC; |
Pour travailler sur plusieurs régions, on utilise une variante un peu plus large avec CTE et agrégation finale.
WITH regional_feature_totals AS ( SELECT t.region, e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') AND te.entitlement IN ('sso', 'audit_logs', 'workflows') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY t.region, e.feature_name ) SELECT region, feature_name, total_events, rolled_requests FROM ( SELECT region, feature_name, total_events, rolled_requests, row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank FROM regional_feature_totals ) ranked WHERE regional_rank <= 3 ORDER BY region, regional_rank; |
Décomposer la forme de la requête
Étape 1 : définir le tenant slice
WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') |
Si PostgreSQL se trompe dès ce premier découpage, tout le reste du plan repose déjà sur une mauvaise population.
Étape 2 : filtrer sur les fonctionnalités autorisées
JOIN tenant_entitlements te ON te.tenant_id = t.id ... AND te.entitlements IN (...) |
La table des entitlements agit à la fois comme cible de join et comme filtre corrélé sur les features.
Étape 3 : lier l’usage récent aux features éligibles
JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement ... AND r.rollup_day >= CURRENT_DATE - 30 |
C’est ici que la multiplicité commence : un tenant peut avoir plusieurs entitlements pertinents et plusieurs jours récents de rollup par feature.
Étape 4 : étendre jusqu’aux événements bruts
JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name ... AND e.event_type IN (...) |
À ce stade, une mauvaise estimation devient très coûteuse. Des nested loops peuvent paraître bon marché sur le papier alors qu’ils ne le sont plus du tout.
Étape 5 : re-réduire l’explosion
GROUP BY e.feature_name ORDER BY rolled_requests DESC |
GROUP BY t.region, e.feature_name |
Le résultat final est petit, mais le travail pour y arriver ne l’est pas. C’est précisément ce qui fait de cette requête une si bonne démonstration du planner.
Étape 6 : ranking dans la version multi-région
row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank ... --- followed by WHERE regional_rank <= 3 |
Ici s’ajoutent du tri, de la pression sur le temp I/O et un problème supplémentaire de ranking. Ce n’est plus seulement une histoire de joins et d’agrégats.
Les extended statistics à la rescousse
Le réflexe naturel face à ce genre de problème est souvent d’ajouter davantage d’index multi-colonnes, partiels ou sur expressions. Ici, nous allons plutôt créer trois objets statistiques pour corriger directement les croyances erronées du planner.
- les colonnes corrélées des tenants,
- les combinaisons tenant-entitlement,
- les combinaisons de rollups.
Et bien sûr, après création, il faut relancer ANALYZE.
Type : dependencies
Les statistiques de dépendance fonctionnelle aident PostgreSQL à comprendre que certaines colonnes prédisent suffisamment les autres pour que l’hypothèse d’indépendance soit fausse.
- Un pays prédit souvent la monnaie.
- Un État prédit souvent le fuseau horaire.
- Le segment du tenant prédit souvent les familles d’entitlements.
CREATE STATISTICS stats_tl_segment_dependencies (dependencies) ON id, plan_tier, region, billing_status FROM tenants; |
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
Règle mentale : dependencies corrige « ces filtres ne sont pas indépendants ».
Type : mcv
MCV signifie “most common values”, mais pour les extended statistics, il vaut mieux le lire comme “most common combinations”.
CREATE STATISTICS stats_tl_segment_mcv (mcv) ON plan_tier, region, billing_status FROM tenants; |
PostgreSQL apprend alors que certaines combinaisons sont particulièrement fréquentes, particulièrement rares ou carrément impossibles. Règle mentale : mcv corrige « cette combinaison exacte se comporte différemment de la moyenne ».
Type : ndistinct
ndistinct indique à PostgreSQL combien de combinaisons distinctes de plusieurs colonnes existent réellement, au lieu de ne connaître que le distinct de chaque colonne prise séparément.
CREATE STATISTICS stats_tel_entitlement_ndistinct (ndistinct) ON tenant_id, entitlement FROM tenant_entitlements; CREATE STATISTICS stats_url_feature_ndistinct (ndistinct) ON tenant_id, feature_name, rollup_day FROM usage_rollups; |
Règle mentale : ndistinct corrige « ces groupes ou combinaisons sont beaucoup moins nombreux que le planner ne l’imagine ».
Ce que PostgreSQL stocke
C’est là que cela devient très intéressant. On pourrait aussi attaquer tous ces problèmes avec davantage d’index. Mais les index coûtent cher à maintenir et coûtent cher en stockage.
Les extended statistics, elles, sont étonnamment peu coûteuses. Elles vivent dans pg_statistic_ext et pg_statistic_ext_data, et sont essentiellement des métadonnées pour le planner.
pg_statistic_extdécrit les objets statistiques.pg_statistic_ext_datacontient les données matérialisées.
Dans ce benchmark, le coût total est d’environ 2 059 octets :
- Tenant-Segment
mcv: ~1 049 octets - Tenant-Segment
dependencies: ~518 octets - Entitlement
ndistinct: ~220 octets - Rollup
ndistinct: ~272 octets
C’est tout l’intérêt : ce ne sont pas de gros index fantômes, mais de petits faits supplémentaires qui empêchent le planner de trop se tromper.
Réparer les execution plans
Au départ, je voulais surtout montrer des gains de runtime. Il y en a eu, mais pas autant que je l’espérais. En revanche, les estimations se sont nettement améliorées, et c’est souvent plus important.
| Scenario | Average Time | Worst Estimate | Additional Storage |
|---|---|---|---|
| Extended statistics | 2,857.896 ms | 48.27x | 2.0 KiB |
| Baseline + Composite Join-Key Indexes | 5,882.659 ms | 106.48x | 37.64 MiB |
| Baseline + Events (feature_name, event_type, tenant_id) | 4,781.551 ms | 108.7x | 31.45 MiB |
| Baseline + Partial Hot-Path Indexes | 4,765.351 ms | 106.22x | 30.20 MiB |
| Extended Statistics + Partial Hot-Path Indexes | 4,876.187 ms | 46.65x | 30.21 MiB |
Chaque requête a été exécutée cinq fois. Les plans complets et les résultats détaillés sont disponibles dans le repository.
Requête mono-région
Le schéma de base utilise des index mono-colonne. Cela évite l’exécution purement séquentielle, mais oblige toujours le planner à deviner l’intersection de prédicats corrélés sur tenants, entitlements, rollups et events.
| Metric | Value |
|---|---|
| Average execution time | 14,168.174 ms |
| Average planning time | 4.134 ms |
| Execution samples | 31,093.955 ms, 29,065.788 ms, 3,564.811 ms, 3,570.114 ms, 3,546.200 ms |
| Planning samples | 5.058 ms, 3.952 ms, 8.969 ms, 1.899 ms, 0.793 ms |
| Join chain | Nested Loop:Inner -> Nested Loop:Inner -> Nested Loop:Inner |
| Scan nodes | Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Nested Loop: 178,389 estimated / 18,774,720 actual (105.25x) |
| Worst estimate path | Sort -> Aggregate -> Nested Loop |
Avec les extended statistics, le tableau change nettement :
| Metric | Value |
|---|---|
| Average execution time | 2,857.896 ms |
| Average planning time | 3.025 ms |
| Execution samples | 4,318.854 ms, 2,612.261 ms, 2,396.848 ms, 2,467.702 ms, 2,493.816 ms |
| Planning samples | 6.719 ms, 2.067 ms, 2.128 ms, 2.243 ms, 1.970 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Hash: 12,966 estimated / 625,824 actual (48.27x) |
| Worst estimate path | Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash |
Le planner cesse alors de se comporter comme si les volumes intermédiaires étaient minuscules. Détail subtil mais important : le coût total estimé augmente. Ce n’est pas un signal négatif, c’est au contraire le signe qu’il croit enfin en un modèle plus réaliste.
Requête multi-région
Sur la version multi-région, le gain de runtime est encore plus visible.
Baseline :
| Metric | Value |
|---|---|
| Average execution time | 24,933.705 ms |
| Average planning time | 3.648 ms |
| Execution samples | 84,815.859 ms, 12,696.190 ms, 11,819.487 ms, 8,482.936 ms, 6,854.054 ms |
| Planning samples | 6.125 ms, 5.681 ms, 2.067 ms, 2.181 ms, 2.187 ms |
| Join chain | Merge Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Sort: 53,580 estimated / 17,164,496 actual (320.35x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Merge Join -> Sort |
Avec extended statistics :
| Metric | Value |
|---|---|
| Average execution time | 7,289.319 ms |
| Average planning time | 2.875 ms |
| Execution samples | 7,503.924 ms, 8,261.715 ms, 7,433.035 ms, 8,181.565 ms, 5,066.357 ms |
| Planning samples | 9.244 ms, 0.932 ms, 1.039 ms, 1.801 ms, 1.359 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Nested Loop: 68,387 estimated / 1,113,566 actual (16.28x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash -> Nested Loop |
Ce n’est pas une petite amélioration. C’est PostgreSQL qui revient enfin à peu près dans le même code postal que la réalité.
Les requêtes sont-elles vraiment devenues plus rapides ?
Parfois oui, parfois non. C’est exactement pour cela que ce sujet mérite une lecture sobre.
Runtime mono-région
- Baseline moyenne : 14,168.174 ms
- Extended statistics moyenne : 2,857.896 ms
Cela semble spectaculaire, mais le baseline est très influencé par deux premiers runs particulièrement lents. L’affirmation prudente est donc : une meilleure compréhension du planner s’est ici corrélée à un bien meilleur comportement stable.
Runtime multi-région
- Statistics seules : 7,289.319 ms
- Meilleure stratégie index-only : 6,886.473 ms
Cela ne fragilise pas l’intérêt de CREATE STATISTICS. Cela le précise : les statistiques améliorent les estimations, les index créent des chemins d’accès physiques.
Pourquoi la comparaison avec les index compte
L’un des résultats les plus intéressants est que certaines stratégies très chargées en index avaient l’air séduisantes en coût ou en runtime, tout en restant nettement moins bonnes sur la qualité d’estimation.
- Extended statistics : environ 2.0 KiB
- Alternatives à base d’index : entre 30.20 MiB et 37.64 MiB

C’est le point sous-estimé : pour environ 2 KiB de métadonnées, PostgreSQL devient beaucoup moins faux, tandis que les alternatives à base d’index consomment des dizaines de MiB supplémentaires sans forcément régler le vrai problème du planner.
Pourquoi “utiliser les deux” n’a pas gagné automatiquement
J’ai évidemment aussi testé la question évidente : est-ce que les extended statistics plus les bons index donnent forcément le meilleur résultat ?
Pas nécessairement.
Single-region :
- Statistics seules : 2,857.896 ms
- Statistics + partial hot-path indexes : 4,876.187 ms
Multi-region :
- Statistics seules : 7,289.319 ms
- Statistics + partial hot-path indexes : 8,950.207 ms
Plus d’index ne créent pas seulement des opportunités. Ils changent aussi l’espace de recherche du planner. “Prendre les deux” n’est donc pas une loi de la nature ; c’est une autre question de benchmark.
Caveats pratiques
Il y a plusieurs limites qu’il faut formuler explicitement :
- Les extended statistics ne s’appliquent qu’à l’intérieur d’une même relation.
- PostgreSQL ne les utilise pas directement pour estimer la sélectivité des joins entre tables.
- Tous les workloads n’en profitent pas. Si les colonnes sont réellement proches de l’indépendance, le gain sera faible.
- Elles ne remplacent ni de bonnes requêtes, ni des index utiles, ni le partitionnement, ni des réglages mémoire sains, ni un stockage rapide.
Ce sont des fonctionnalités d’information pour le planner, pas un charme de performance universel.
Quand sortir CREATE STATISTICS
La règle pratique est simple : si un plan semble mauvais et que l’erreur paraît liée à plusieurs colonnes filtrées ou groupées ensemble d’une façon que le planner modélise mal, pensez aux extended statistics avant de créer automatiquement un nouvel index.
Bons candidats :
- colonnes de filtrage fortement corrélées,
- attributs de dimensions pilotés par segment,
- group by avec cardinalité manifestement fausse,
- problèmes de fanout multi-colonnes,
- combinaisons très skewées de valeurs fréquentes,
- plans où une mauvaise estimation d’une seule relation empoisonne tout le reste.
Moins bons candidats :
- requêtes dont le vrai problème est l’absence de chemin d’accès physique,
- workloads dominés par un goulot I/O évident,
- cas où les colonnes sont effectivement presque indépendantes.
Utilisez EXPLAIN (ANALYZE, VERBOSE, BUFFERS). Si les estimated rows et les actual rows divergent massivement, les extended statistics méritent probablement d’être essayées.
Mieux vaut la vérité que les astuces
Le plus beau avec CREATE STATISTICS, c’est que cela nourrit le planner avec plus de vérité au lieu d’empiler toujours plus de structures sur les données.
Les benchmarks ne disent pas “les extended statistics gagnent toujours”. Ils disent quelque chose de plus utile :
- elles ont rendu PostgreSQL beaucoup moins faux,
- elles ont changé la forme du plan de manière significative,
- elles coûtent presque rien en stockage,
- et elles s’attaquent souvent plus directement au vrai problème du planner que des dizaines de MiB d’index supplémentaires.
Le benchmark, les requêtes et les résultats sont disponibles sur GitHub. Vous pouvez aussi tester ces requêtes dans notre Vela Postgres Sandbox.
Et si vous avez déjà regardé un plan en pensant : “ce join n’a aucune raison d’être imbriqué trois fois sous un trench coat”, alors il est très possible que les extended statistics soient exactement la fonctionnalité que vous cherchiez.