
Cuando empezamos a construir Vela teníamos un objetivo muy concreto, y un poco terco: un nuevo entorno de Postgres debía estar listo tan rápido que no se sintiera como “aprovisionamiento”. No queríamos decir “rápido para arrancar una VM”, queríamos decir lo más rápido posible. Tan rápido que los platform engineers hablaran de entrega instantánea, pero con aislamiento total.
Dicho eso, teníamos tres restricciones:
- Aislamiento total entre bases de datos con límites duros, no “aislamiento a nivel de namespace”.
- Resistencia real frente a noisy neighbors con límites firmes de CPU, RAM y actividad de disco.
- Escalabilidad nativa de Kubernetes con colocación automática y reemplazo sin interrupciones mediante live migration.
Aunque el objetivo inicial de Vela suena fácil y directo, fue desesperantemente difícil alcanzarlo. Cada base de datos (branch) en Vela recibe aislamiento fuerte y la capacidad de escalar de forma dinámica e independiente. Se siente como debería sentirse una base de datos sobre Kubernetes, pero con las garantías de aislamiento de una máquina virtual.
Este post cuenta cómo llegamos desde ahí hasta arranques en menos de 10 segundos, manteniendo aislamiento total entre bases de datos y un comportamiento de escalado que funciona de forma natural dentro de Kubernetes. Por el camino aprendimos mucho sobre el modelo de KubeVirt (y sus bordes afilados), por qué el autoscaling de VMs es sutilmente distinto al autoscaling de pods y por qué una imagen mínima de sistema operativo puede ser una palanca de rendimiento mayor que casi cualquier flag de tuning.
Por qué optamos por máquinas virtuales
Al principio elegimos VMs por una razón pragmática: la live migration de VMs es un problema resuelto. La soportan la mayoría de los hipervisores y sigue estando claramente por delante de la migración en caliente de contenedores en cuanto a madurez. Sí miramos trabajo sobre migración de contenedores (por ejemplo zeropod), pero no encajaba con nuestras restricciones. Aunque maneja bien el escalado, incluso hasta cero, no cumplía nuestro requisito de live migration sin interrupciones.
Kubernetes tampoco era negociable. Para la mayoría de los equipos de plataforma, Kubernetes es “el sustrato”, y se espera que todo lo demás se integre con su scheduling, observability y ciclo de vida operativo.
Así que hicimos lo obvio: ejecutar Postgres dentro de VMs que siguieran controladas como objetos de Kubernetes. KubeVirt está diseñado precisamente para eso: amplía la API de Kubernetes con tipos de VM y ejecuta la “carga útil” de la VM mediante un pod que lanza QEMU/KVM.
Primer intento: KubeVirt, Docker y arranques frustrantes
¿Máquinas virtuales en Kubernetes? Para eso está KubeVirt. Como todos, esa fue también nuestra respuesta. ¿Qué tan difícil podía ser?
Nuestra primera iteración arrancaba en unos 2 minutos en un buen día y hasta en 5 minutos en un mal día. Instantáneo, ¿no? 🫣
Los tiempos del arranque de la VM en sí ni siquiera eran tan malos. Sin embargo, arrancar la VM era solo el comienzo. Dentro de la VM levantábamos Docker (Compose) y luego descargábamos y cargábamos varias imágenes por branch; básicamente todos los servicios de cada branch (Postgres, PGBouncer, PostgREST, …). El throttling de Docker Hub y la “lotería del image pull” resultaron ser una fuente brutal de latencia de cola.
El proceso de arranque era duro:
- Kubernetes crea los recursos de VM de KubeVirt
- El recurso de VM arranca QEMU
- El sistema operativo invitado arranca
- El servicio Docker pasa a estar disponible
- Docker descarga las imágenes de contenedor individuales
- Docker arranca los contenedores uno a uno según el grafo de dependencias
- Los contenedores arrancan y quedan healthy
- Marcamos el branch como activo (healthy)
Sabíamos que descargar las imágenes en cada arranque no era óptimo, pero no esperábamos que fuera tan malo. El problema principal es cómo Docker maneja las descargas de imágenes y el arranque de contenedores. Básicamente descarga todas las imágenes primero y después las arranca según el grafo de dependencias. Basta con una imagen grande o lenta (por throttling), y ya estás fuera. Con cada imagen adicional aumenta la probabilidad de tener un mal día.
En conjunto identificamos tres componentes que amplificaban la latencia, en orden de impacto (de alto a bajo):
- Image pull y throttling del registry para poner a disposición las imágenes de los servicios del branch.
- El arranque en dos niveles con la VM y después los contenedores Docker.
- Pasos adicionales de configuración, como registrar el nombre DNS, aprovisionar un nuevo disco, ejecutar el initdb de Postgres y similares.
Vamos a precachear las imágenes de Docker
Lo primero era eliminar el problema de descargar siempre. Si tu camino de arranque incluye “descargar dependencias”, no tienes tiempo de arranque. Tienes una distribución de probabilidad.
Ya estábamos construyendo una imagen de VM, así que, ¿por qué no “simplemente” descargar todas las imágenes necesarias durante el proceso de build?
Dicho y hecho. Ajustamos el proceso de build para incluir un paso que descargara todas las imágenes Docker necesarias y las empaquetara dentro de la imagen final de arranque de la máquina virtual.
Funcionó muy bien. La mayor fuente de variabilidad desapareció. Pasamos a una base bastante consistente de 90-100 segundos. Aun así, seguíamos perdiendo mucho tiempo arrancando la imagen Linux y esperando a que Docker estuviera disponible antes de poder arrancar nuestros servicios reales del branch. Para un primer intento era suficiente. Sabíamos que había margen de optimización no arrancando una imagen Linux típica, sino afinando el propio procedimiento de arranque.
¿Por qué Docker?
Una de las preguntas que seguía apareciendo era: “¿Por qué demonios usasteis Docker dentro de la VM?”
La respuesta corta es una sola palabra: comodidad.
La respuesta larga es: la comodidad de tener ciclos de iteración más rápidos usando distintas imágenes Docker y probando distintas opciones de servicio (como Pgpool-II, PGBouncer y otras).
Necesitábamos poder experimentar sin reconstruir las máquinas virtuales, y Docker era la solución perfecta en ese momento. Además habría hecho los upgrades de base de datos realmente sencillos. En Postgres, para un upgrade de versión mayor necesitas dos versiones instaladas: la nueva y la actual. Con Docker eso estaba a un solo download de distancia. Usar la imagen base de la nueva versión, descargar la antigua tras el arranque, ejecutar la migración y eliminar la imagen del contenedor anterior. Hecho.
De todos modos, antes de volver al resto de factores de latencia, encontramos otros problemas acercándose.
Cuando KubeVirt empezó a fallarnos
Queremos dejarlo claro: ninguno de los problemas siguientes significa simplemente que “KubeVirt sea malo”. De hecho, KubeVirt resuelve un problema muy difícil y lo hace de la forma más Kubernetes posible.
Sin embargo, nuestro comportamiento objetivo (VMs rápidas, frecuentes, elásticas y con forma de base de datos) tensionaba partes distintas del sistema. No era la VM “de larga vida” típica que nunca cambia de caso de uso. KubeVirt es excelente si quieres la comodidad de Kubernetes y el ciclo de vida y aislamiento típicos de una máquina virtual. Nosotros, en cambio, nos apartábamos de ese patrón, y se empezó a notar.
Escalar una máquina virtual no es escalar un pod
El primer punto de fricción fue que escalar recursos de VM para CPU y RAM no era algo raro para nosotros. Queríamos escalar hacia arriba y hacia abajo de forma dinámica, tan a menudo y tan rápido como fuera posible. Potencialmente, incluso con scale-to-zero.
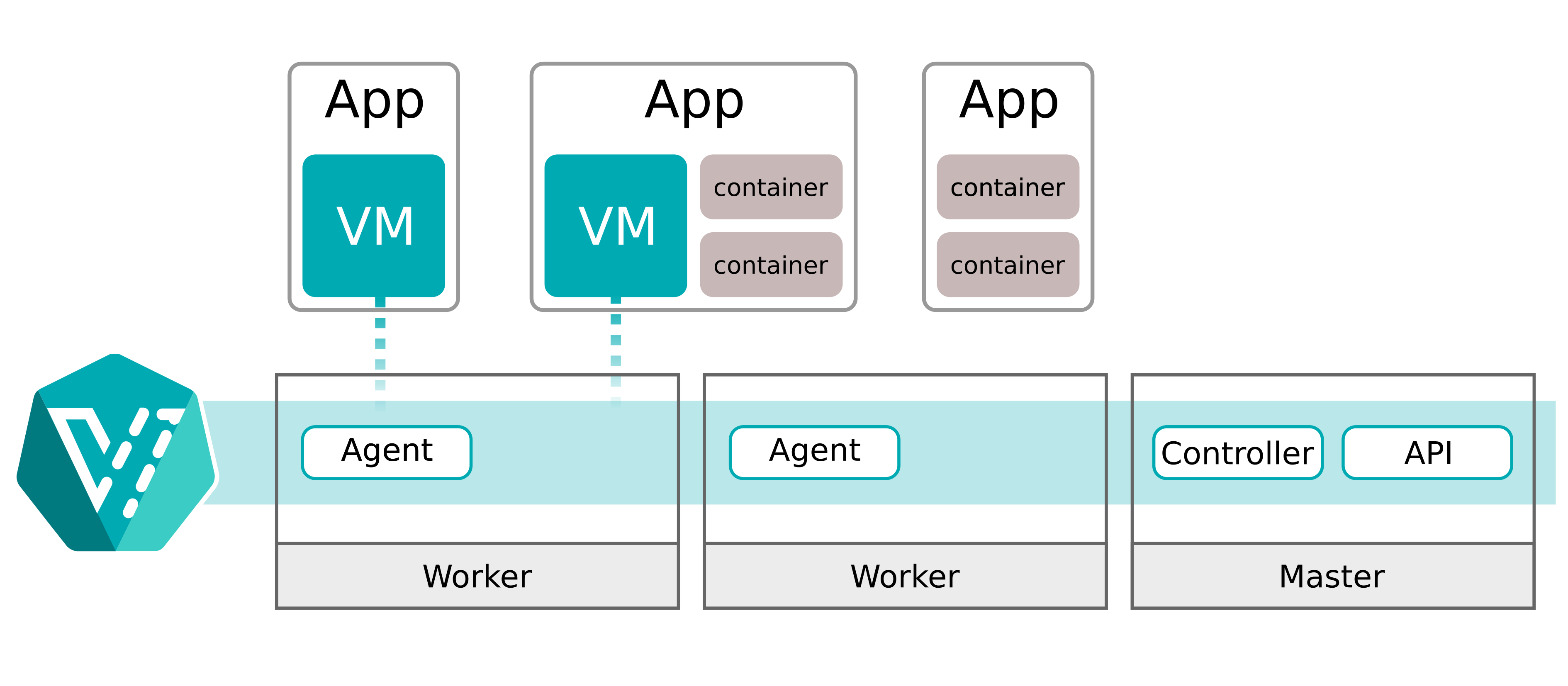
En KubeVirt, esos cambios disparan una live migration inmediata. Incluso si todavía hay recursos suficientes en el host actual. El principal punto de dolor es que la live migration siempre mueve la VM a otro worker de Kubernetes. Aunque su impacto en rendimiento es limitado, estar moviendo constantemente las máquinas virtuales no nos servía.
“Current hotplug implementation involves live-migration of the VM workload.” KubeVirt Authors, “Memory Hotplug” documentation (KubeVirt.io)
Para un ciclo de vida típico de VM, esa decisión de diseño tiene mucho sentido. Pero para nosotros significaba que cada “resize” se convertía en “mover el mundo”, con complejidad de red en cascada y efectos sobre la sostenibilidad de las conexiones a la base de datos.
Necesitábamos una solución que solo live-migrara una máquina virtual cuando de verdad no hubiera recursos disponibles y que permitiera escalar CPU y RAM localmente hacia arriba y hacia abajo.
La live migration y las sesiones TCP son una combinación brutal
También nos topamos con una verdad más dura: la live migration solo es “transparente” si tu stack de red y tu pipeline de migración preservan las invariantes que asume tu workload. Los clientes de Postgres no perdonan pausas largas.
Las bases de datos son sensibles a la latencia y orientadas a conexión. Nuestras pruebas internas mostraron que incluso las discontinuidades más pequeñas se vuelven visibles rápidamente durante pruebas sostenidas de conexiones. Soluciones sugeridas como passt redujeron parte de la carga, pero seguíamos viendo conexiones rotas bajo carga moderada o alta de pgbench.
Y parece que no éramos los únicos. KubeVirt tiene issues públicos y discusiones en la comunidad sobre problemas de red tras la migración. Por ejemplo, existe un informe histórico de que después de migrar la conectividad puede romperse en la interfaz masquerade. Otros miembros de la comunidad han descrito la pérdida de conexiones porque la identidad subyacente de pod/red cambia durante la migración.
Necesitábamos una red overlay de verdad.
Contabilidad de recursos a dos niveles: Pod frente a VM
Otro detalle incómodo: el control de recursos ocurre en múltiples capas del stack.
- El nivel de la máquina virtual es lo que QEMU cree que la VM tiene disponible.
- El nivel Pod/Cgroup es lo que Kubernetes impone sobre el pod virt-launcher (QEMU).
En nuestros experimentos vimos que las asignaciones de CPU y memoria debían gestionarse de forma efectiva tanto a nivel de VM como de pod. Actualizar solo el nivel pod causaba problemas de out-of-memory en la VM. Esto está relacionado con el problema de escalado mencionado antes.
Para mitigar parte del problema y permitir live resizing, tuvimos que rodear KubeVirt y usar libvirt para actualizar las VMs directamente. Había que hacerlo con cuidado para no romper el sistema, porque un solo evento de reconciliación sobre un recurso de VM de KubeVirt invalidaría cualquier actualización “manual”.
Necesitábamos una forma más segura de hacer las cosas.
Hora de seguir adelante
Nos encontramos en múltiples situaciones donde necesitábamos workarounds que no encajaban limpiamente en la superficie de API soportada, y la siguiente reconciliación los desharía. Parchear KubeVirt habría implicado mucho trabajo, y no queríamos cargar con un fork duradero de un proyecto tan central solo para seguir avanzando.
Nos preguntamos:
- “¿Es KubeVirt una buena API de virtualización para Kubernetes?” Sí, lo es.
- “¿Es KubeVirt una buena abstracción para nuestro lifecycle de branches y nuestro modelo de escalado?” Creemos que no.
Así que hicimos lo que hacen los builders de open source. Buscamos otro enfoque que encajara mejor con nuestros requisitos, y había dos opciones básicas: encontrar una solución mejor ya existente o escribirlo todo desde cero, con un propósito específico.
Nuestro primer pensamiento fue construir nuestra propia abstracción sobre libvirt o incluso directamente sobre QEMU. Pero al analizar el tamaño del código fuente de KubeVirt y diseñar qué características habría que rehacer, vimos el alcance real que teníamos delante.
Casar una máquina virtual con Kubernetes es un trabajo duro. Demasiados conceptos divergen y luego hay que volver a integrarlos. Nos dio respeto. Así que decidimos buscar primero otras soluciones. Algo más cercano a lo que necesitábamos. Y tuvimos suerte.
El giro: adoptar el Autoscaling de Neon
El mejor enfoque es buscar otra solución si puedes encontrar una que cumpla mejor tus requisitos. Y eso fue exactamente lo que hicimos.
La idea era simple y obvia, cuando lo piensas: mirar empresas cercanas y sus soluciones. Por suerte para nosotros, ahí fuera hay muchas bases de datos. Muchas open source. Muchas relacionadas con Postgres.
Cuando encontramos el proyecto Autoscaling de Neon, también nos dimos cuenta de que no éramos los primeros en tropezar con las limitaciones anteriores. Ellos se enfrentaron a muchos de los mismos problemas y decidieron escribir su propia solución. El enfoque de Neon tenía forma de base de datos sin pedir disculpas. Estaba diseñado alrededor del autoscaling vertical de Postgres dentro de micro-VMs gestionadas por K8s (basadas en QEMU). Además resolvieron la parte difícil: “no romper las sesiones TCP cuando cambias recursos o mueves el workload”.
La parte más interesante de Autoscaling es cómo se toman las decisiones de escalado y cómo funciona el escalado en sí.
Primero, Autoscaling usa cgroups para delimitar los recursos (CPU y memoria) a efectos de reporting. Para capturar el uso del “host” (la VM invitada), utiliza métricas recogidas a través de Prometheus. Cada pocos segundos se evalúa el uso actual frente a potenciales eventos de upscale o downscale. Además, el agente dentro de la máquina virtual puede solicitar de forma proactiva decisiones de escalado, aunque estas pueden ser vetadas.
Como Autoscaling usa QEMU por debajo, CPU y memoria se pueden hot-pluggear. Es decir, en tiempo de ejecución se añaden o retiran núcleos de CPU a la máquina virtual según haga falta. La memoria funciona de forma similar, usando dispositivos virtio-mem que pueden añadirse o quitarse en runtime. El kernel de Linux mueve las regiones de memoria que deben eliminarse para liberar un dispositivo virtio-mem antes de desacoplarlo (de forma parecida al memory ballooning).
“We want to dynamically change the amount of CPUs and memory of running Postgres instances, without breaking TCP connections to Postgres.” Neon Autoscaling README (GitHub)
Componentes de Autoscaling
Autoscaling en sí es un conjunto de componentes que trabajan juntos para habilitar Postgres serverless en Kubernetes.
- Un controlador (neonvm-controller) para gestionar los recursos de máquinas virtuales (CRDs).
- Un scheduler que evalúa la capacidad de los nodos y toma decisiones de colocación y reemplazo de VMs.
- Un agente por nodo (daemonset) que recoge el uso de recursos de las VMs y lo reporta.
- Un monitor de VM que corre junto al workload y reporta uso vía Prometheus, con configuración específica de cgroups.
- Un gestor VXLAN, que garantiza conectividad sostenida con interfaces de red virtuales y overlay networking (junto con Flannel).
- Una imagen runtime que envuelve la VM. Hace disponible la imagen de VM, arranca QEMU, maneja DHCP/port forwarding y gestiona mounts.
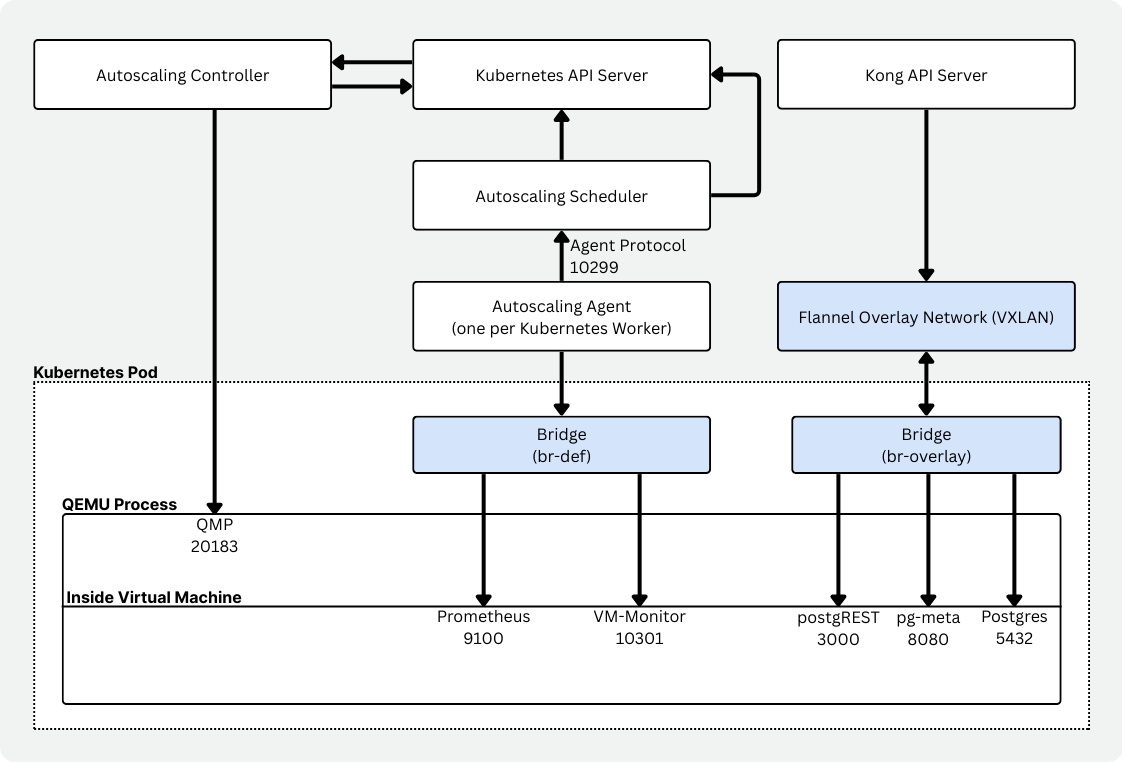
Aquí se aprecia la misma separación conceptual: un scheduler personalizado, un autoscaling-agent por nodo y un vm-monitor que puede reaccionar inmediatamente a presión de memoria. Un encaje mucho mejor para Vela.
Gracias al equipo de Neon detrás de Autoscaling por este gran trabajo.
Aun así hicieron falta cambios
Pero por mucho que Autoscaling ya encajara bien, seguían existiendo algunas “aristas” debido a las diferencias entre cómo están implementados Neon y Vela.
Primero, con simplyblock como almacenamiento principal subyacente, necesitábamos soporte para adjuntar uno o más PVCs (Persistent Volume Claims) a la máquina virtual.
Luego queríamos una forma de limitar el uso de CPU y RAM sin perder la opción de actualizar esos límites en caliente. Por desgracia, QEMU necesita conocer el máximo de CPU y RAM que se puede adjuntar en cualquier momento. Nosotros necesitábamos que esos valores fueran mucho más altos de lo que esperábamos que la gente alcanzara realmente al escalar. Así que ampliamos el proceso de decisión con un límite blando. Las VMs actuales tienen un límite duro de 128 vCPUs y 256 GB de memoria. El límite blando, en cambio, describe los factores máximos de escalado actuales, como 8 vCPUs o 16 GB de memoria. Las peticiones por encima del soft limit se rechazan.
Y por último añadimos un PowerState sencillo que nos permite arrancar y detener la máquina virtual simplemente actualizando ese valor en el CRD. Pura comodidad.
Ganar tiempo de arranque: matar el “Docker dentro de la VM”
Una vez que Autoscaling resolvió una gran parte de la fricción del lifecycle y del escalado, tocaba volver al problema real: el tiempo de arranque. El verdadero avance llegó cuando fuimos honestos con nosotros mismos. Lo que hacíamos al arrancar era sencillamente estúpido. Habíamos elegido nuestra comodidad por encima de la experiencia del usuario. Estábamos arrancando una distro de propósito general, luego arrancando Docker y después orquestando varios servicios mediante imágenes de contenedor. Así que eliminamos por completo esa capa interna de contenedores.
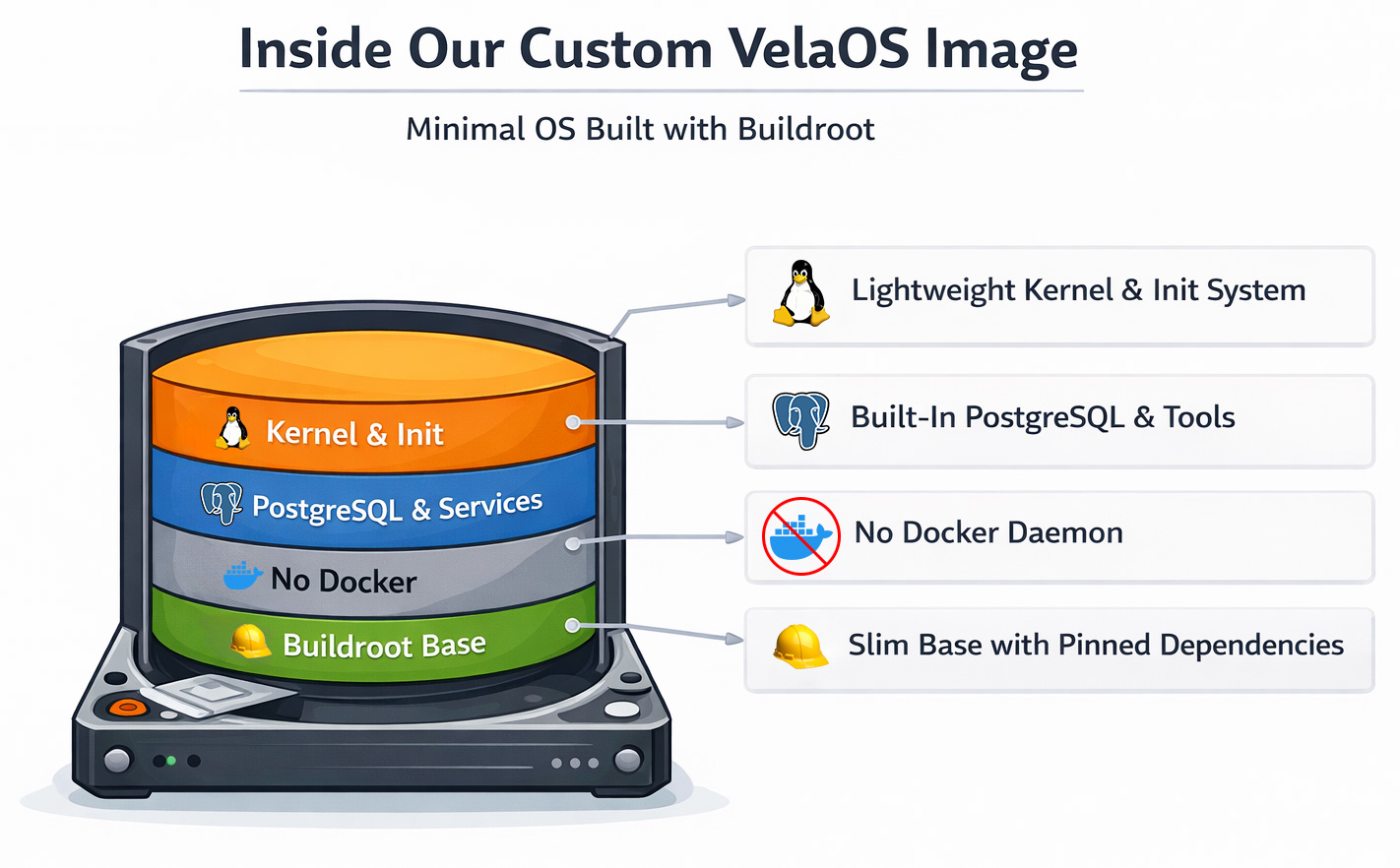
VelaOS: un kernel Linux y rootfs personalizados basados en Buildroot
Pasamos a una imagen Linux personalizada basada en Buildroot. Buildroot es un framework para construir kernels Linux y un root filesystem mínimo. Diseñado inicialmente para dispositivos embebidos, soporta imágenes de filesystem de solo lectura, actualizadores de dispositivos y más.
Aunque quizá no hubieras oído hablar antes de Buildroot, en realidad es un sistema muy utilizado. Entre sus usuarios más conocidos están OpenWRT, Home Assistant OS (HAOS), además de fabricantes de dispositivos embebidos como Google Fiber. Buildroot es conocido por sus root filesystems de tamaño mínimo.
Cambiar a Buildroot nos dio varias ventajas rápidas aparte de simplemente quitarnos Docker de encima:
- El proceso de arranque se volvió determinista usando inittab como sistema init base para controlar exactamente qué se arranca y cuándo.
- No más pulls de Docker, porque todos los servicios van integrados en la imagen de arranque.
- Más velocidad de arranque, porque no usamos una imagen de sistema operativo de propósito general sino un kernel Linux optimizado.
- Builds reproducibles, con cada componente fijado a una versión o commit concretos y checksum, asegurando que solo se construyan componentes no modificados.
Por el otro lado, perdimos velocidad de iteración. Buildroot, como framework de build, compila por sí mismo la mayor parte de los componentes de la imagen final. Así consigue imágenes de disco increíblemente pequeñas, a costa de tiempo de build. Aun así, gracias a CCache y otras técnicas de optimización, siguió siendo manejable.
El camino de arranque resultante es simple:
- Kubernetes programa el pod de la VM (a través de las decisiones del scheduler de autoscaling).
- El runtime arranca QEMU con nuestra imagen de VM.
- El invitado arranca un sistema mínimo con los servicios ya instalados.
- Postgres y los servicios auxiliares del branch se levantan inmediatamente (sin descargas).
Todavía hay margen de mejora. Pero por ahora creemos que <10 segundos es suficientemente bueno. El valor de Vela es “los branches aparecen rápido, se comportan de forma consistente y aíslan de verdad”.
Aislamiento y escalabilidad: por qué esto sigue sintiéndose como Kubernetes
Una preocupación razonable es: “Si dejasteis KubeVirt y empezasteis a usar plumbing propio de VMs, ¿no perdisteis la ergonomía de Kubernetes?”
En la práctica conservamos las partes queridas de Kubernetes. Seguimos teniendo control declarativo mediante CRDs y controladores que reconcilian el estado deseado. El scheduling se implementa a través de Kubernetes, con la colocación influida por el scheduler y el agente de autoscaling. Las restricciones de recursos a nivel de nodo aportan la evidencia necesaria para decisiones de colocación, escalado y migración basadas en la capacidad real del nodo y el uso real de la VM. Y, por último, los límites de aislamiento se fuerzan haciendo que cada branch de base de datos tenga su propio límite de VM.
Todo esto preservando la posibilidad de live-migrar por completo un branch de Vela de un worker de Kubernetes a otro sin destruir las conexiones Postgres ya existentes.
Un arranque rápido también es una característica del control plane
Pero un tiempo de arranque inferior a 10 segundos no es solo una mejora de experiencia de usuario. También cambia qué construyes y cómo lo construyes:
- Vela puede escalar con más agresividad porque añadir capacidad es barato, horizontalmente con más máquinas virtuales y verticalmente mediante live-resizing de límites de VM.
- Vela puede tratar los entornos como efímeros porque el coste de recrearlos es bajo y el almacenamiento y el cómputo están completamente separados.
- Vela puede absorber fallos sustituyendo la VM en lugar de repararla.
Esa es la forma de un sistema que, con el tiempo, puede servir a usuarios, agentes y workflows de CI sin hacer esperar al usuario.
Lecciones aprendidas: ¡Siempre es más complicado de lo que crees!
“VMs vs containers” no es el debate, el debate es el determinismo del boot path.
Empezamos con VMs por buenas razones (madurez en migración, aislamiento fuerte), pero nuestros peores retrasos vinieron de nuestro propio amor por la comodidad y la iteración rápida. El arranque de Docker más los pulls de imágenes. En el momento en que eliminamos “tirar imágenes al arrancar”, el tiempo hasta estar listos dejó de ser una apuesta.
La reconciliación de Kubernetes es amiga y enemiga.
Si te descubres “trabajando alrededor del reconciler”, trátalo como una señal de que estás fuera del modelo de extensión previsto y acércate a patrones soportados o elige un sustrato que se adapte mejor a tus necesidades de control.
La optimización más rápida suele consistir en quitar cosas.
Igual que el código más rápido es el que nunca se ejecuta, la optimización más rápida suele ser eliminar componentes innecesarios. En nuestro caso, eliminar Docker Compose y los pulls de imágenes borró minutos de variabilidad.
La live migration no es una única feature, sino toda una superficie de producto.
KubeVirt y Autoscaling abordan la migración de formas muy distintas. Mientras que en KubeVirt casi cualquier cambio de CPU o memoria termina en una live migration, Autoscaling intenta hacer lo máximo posible sobre la VM actual y solo migra cuando escasean los recursos físicos. La otra gran diferencia es una identidad de red estable conseguida mediante una red overlay real y no hacks sobre el plano de red de Kubernetes. Si tu workload tiene forma de base de datos, el evento “se migró” tiene que ser invisible para los clientes, o vivirás luchando contra tormentas de reconexión y latencia de cola.
Las imágenes mínimas de sistema operativo no solo aportan velocidad. Reducen la entropía operativa.
Una imagen pequeña y diseñada con un propósito tiene menos piezas móviles. Eso implica menos interacciones inesperadas, menos demonios de fondo haciendo cosas “útiles” y una superficie de depuración más pequeña cuando algo sale mal. Con VelaOS, basado en Buildroot, también conseguimos builds reproducibles y la opción de certificar exactamente qué hay dentro de la VM en cada momento (excepto los datos).
No tengas miedo de sentir respeto por el problema. A veces eso lleva a un gran resultado.
Cuando investigamos construir nuestra propia alternativa a KubeVirt, el alcance de la tarea daba miedo. Lo suficiente como para dedicar tiempo a investigar otras soluciones que ya pudieran existir. Eso nos llevó a Autoscaling. Y nos alegra haber sentido ese respeto.
KubeVirt está haciendo un trabajo importante para el ecosistema de Kubernetes.
Sin KubeVirt dando los primeros pasos para llevar las máquinas virtuales a Kubernetes, quizá hoy no estaríamos aquí. Merece la pena decirlo explícitamente: KubeVirt está haciendo un trabajo importante para el ecosistema. Incluso allí donde encontramos limitaciones, el proyecto sigue evolucionando activamente. Por ejemplo, la propia comunidad de KubeVirt está siguiendo mejoras alrededor del targeting de migración y del acoplamiento con resize, como puede verse en issues como #15625. Y KubeVirt sigue documentando integraciones del mundo real, como su ejecución junto a Cluster Autoscaler en entornos cloud.
Adónde queremos ir después
No vemos esto como “KubeVirt vs Neon Autoscaling”. Hay múltiples maneras válidas de ejecutar VMs sobre Kubernetes, y la mejor opción depende de la forma de tu workload.
KubeVirt es una capa de virtualización potente y generalista para Kubernetes, y seguimos de cerca su evolución.
Para los objetivos principales de Vela, como branches efímeros de base de datos con aislamiento fuerte, necesitábamos un control plane y un camino runtime optimizados sin complejos para bases de datos.
Autoscaling de Neon nos dio la base adecuada, y Vela OS hizo predecible el tiempo de arranque.
Si estás construyendo algo en este espacio, nos encantaría hablar sobre tus experiencias, decisiones y edge cases adicionales. Especialmente en torno a networking, comportamiento de migración o diseño de imágenes de VM.
En un futuro cercano empezaremos a upstreamear las mejoras que hemos hecho. Creemos en un ecosistema open source sano y queremos compartir los cambios en lugar de mantenerlos privados.
Si quieres experimentar y probar nuestras instancias Postgres de Vela, crea tu cuenta gratuita en https://demo.vela.run. Vela es completamente open source y está pensada para self-hosting en tu propio data center o private cloud. En este momento estamos limpiando el codebase, corrigiendo bugs pendientes e implementando el procedimiento de instalación de cara al usuario.