
Versión corta: cuando una query va lenta, casi todo el mundo piensa primero en índices. PostgreSQL ofrece de todo: índices multicolumna, parciales, sobre expresiones. El problema es el coste: más storage, más mantenimiento, más escritura. Lo que mucha gente ignora es CREATE STATISTICS. Las extended statistics pueden mejorar el plan con un coste casi inexistente en almacenamiento.
En muchos planes malos el verdadero problema no es que el planner “sea tonto”, sino que está tomando decisiones racionales a partir de una imagen equivocada de los datos. Cuando varios predicados están correlacionados, las estadísticas por columna no bastan. Ahí entran las extended statistics.
La versión corta
CREATE STATISTICS permite a Postgres recopilar información adicional que las estadísticas normales por columna no pueden representar bien.
En la práctica, ayuda sobre todo en cuatro tipos de problemas:
- filtros correlacionados sobre varias columnas,
- conteos distinct multicolumna,
- combinaciones de valores muy sesgadas,
- expresiones para las que normalmente terminarías creando un índice sobre expresión.
–-- Alternative to index on expressions CREATE STATISTICS stats_expr ON (date_trunc(‘day’, created_at)) FROM events; --- What people normally mean by --- extended statistics CREATE STATISTICS stats_multi (dependencies, ndistinct, mcv) ON plan_tier, region, billing_status FROM tenants; |
La primera forma es útil para estadísticas sobre expresiones como date_trunc o extracción desde JSONB. La segunda es lo que la mayoría entiende por extended statistics.
Los tres tipos importantes son dependencies, ndistinct y mcv. Igual que con las estadísticas normales, CREATE STATISTICS solo define el objeto; ANALYZE sigue siendo quien recoge los datos.
¿Por qué extended statistics?
Por defecto, Postgres almacena sobre todo estadísticas por columna. Eso funciona bien mientras los filtros puedan tratarse como independientes. El problema aparece cuando la relación entre columnas importa.
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
En datos reales, esos predicados suelen estar correlacionados. Sin estadísticas adicionales, PostgreSQL se comporta como si cada condición redujera las filas de forma independiente. El resultado es una estimación que parece limpia en matemáticas y absurda en operación.
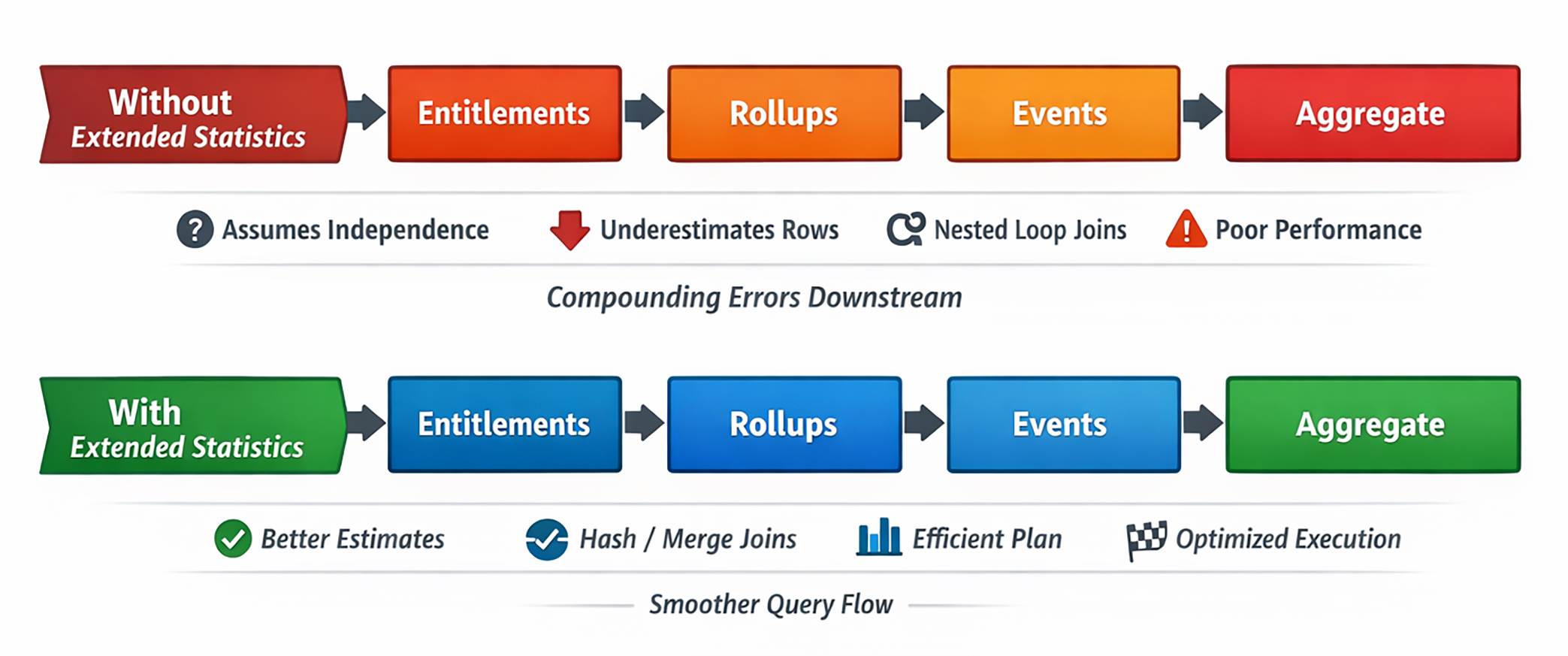
Y cuando la estimación inicial es mala, todo lo demás se contamina: el orden de joins, el método de join, el paralelismo, el tamaño de los hash, la estrategia de sort, el riesgo de spill.
Lo que Postgres sabe por defecto
Con cada ANALYZE, PostgreSQL guarda información por columna como fracciones de nulos, histogramas, valores frecuentes y cardinalidades. Todo eso es útil, pero sigue siendo conocimiento local a una sola columna.
Imagina una tabla con un millón de filas y esta distribución:
plan_tier = 'enterprise'coincide con el 6 %region = 'eu-central'coincide con el 25 %billing_status = 'active'coincide con el 80 %
1,000,000 * 0.06 * 0.25 * 0.80 = 12,000 rows |
El problema es que esas columnas rara vez son independientes. En el mundo real, la respuesta puede ser 40.000, 60.000 o 5.000 filas. Las estadísticas por columna no pueden decirlo.
Benchmarking de extended statistics
Para mostrarlo con algo concreto, construí una carga sintética pero realista de analytics SaaS con cuatro tablas: tenants, tenant_entitlements, usage_rollups y analytics_events.
El dataset está diseñado para exponer justo los puntos ciegos del planner: correlaciones entre plan, región y estado de facturación; entitlements premium concentrados; y combinaciones (tenant, feature, day) que no son aleatorias.
Es sintético, sí, pero sintético en el sentido en que un túnel de viento es sintético: controlado para aislar un fenómeno real.
Aislar el problema con la forma de los datos
Tabla: tenants
Las columnas de segmentación están correlacionadas de una manera muy común en datos SaaS reales.
Tabla: tenant_entitlements
Los features premium como sso, audit_logs o workflows aparecen mucho más en tenants enterprise.
Tabla: usage_rollups
Esta tabla modela fanout temporal realista por combinación tenant-feature.
Tabla: analytics_events
Aquí se produce la explosión de cardinalidad: muchas filas de eventos por cada combinación que pasa los filtros anteriores.
La query de reporting
La pregunta de negocio es sencilla: “¿Qué features premium generan más actividad reciente entre tenants enterprise activos de una región importante?”
SELECT e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.region = 'eu-central' AND t.billing_status = 'active' AND te.entitlement IN ('sso', 'audit_logs') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY e.feature_name ORDER BY rolled_requests DESC; |
Para varias regiones se usa una variante ampliada con CTE y agregación final.
WITH regional_feature_totals AS ( SELECT t.region, e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') AND te.entitlement IN ('sso', 'audit_logs', 'workflows') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY t.region, e.feature_name ) SELECT region, feature_name, total_events, rolled_requests FROM ( SELECT region, feature_name, total_events, rolled_requests, row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank FROM regional_feature_totals ) ranked WHERE regional_rank <= 3 ORDER BY region, regional_rank; |
Desmontando la forma de la query
Etapa 1: definir el tenant slice
WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') |
Si PostgreSQL estima mal este primer recorte, todo lo que viene después nace ya sobre una población equivocada.
Etapa 2: limitar a features permitidos
JOIN tenant_entitlements te ON te.tenant_id = t.id ... AND te.entitlements IN (...) |
La tabla de entitlements actúa aquí como join target y como filtro correlacionado de features a la vez.
Etapa 3: ligar uso reciente a features elegibles
JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement ... AND r.rollup_day >= CURRENT_DATE - 30 |
Aquí empieza la multiplicidad: un tenant puede tener varios entitlements relevantes y varios días recientes por feature.
Etapa 4: expandir a eventos en bruto
JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name ... AND e.event_type IN (...) |
En este punto una mala estimación ya sale carísima. Los nested loops pueden parecer baratos en papel cuando en realidad no lo son.
Etapa 5: colapsar de nuevo la explosión
GROUP BY e.feature_name ORDER BY rolled_requests DESC |
GROUP BY t.region, e.feature_name |
El resultado final es pequeño, pero el trabajo para llegar ahí no. Esa es precisamente la gracia de esta query como demo del planner.
Etapa 6: ranking en la query multi-región
row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank ... --- followed by WHERE regional_rank <= 3 |
Esto añade presión extra de sort y de temp I/O. La query ya no es solo un problema de joins y agregados, también es un problema de ranking.
Extended statistics al rescate
El reflejo habitual ante estos problemas es añadir más índices multicolumna, parciales o incluso sobre expresiones. Aquí, en cambio, usamos tres objetos estadísticos para atacar directamente los supuestos erróneos del planner.
- columnas correlacionadas de tenants,
- combinaciones tenant-entitlement,
- combinaciones de rollups.
Y recuerda: después de crear las estadísticas, hay que ejecutar ANALYZE.
Tipo: dependencies
Las estadísticas de dependencia funcional ayudan a que PostgreSQL entienda que ciertas columnas predicen otras con suficiente fuerza como para no tratarlas como independientes.
- Un país suele predecir la moneda.
- Un estado suele predecir la zona horaria.
- El segmento del tenant suele predecir familias de entitlements.
CREATE STATISTICS stats_tl_segment_dependencies (dependencies) ON id, plan_tier, region, billing_status FROM tenants; |
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
Como regla mental: dependencies corrige “estos filtros no son independientes”.
Tipo: mcv
MCV significa “most common values”, pero aquí conviene pensarlo como “most common combinations”.
CREATE STATISTICS stats_tl_segment_mcv (mcv) ON plan_tier, region, billing_status FROM tenants; |
Con esto PostgreSQL aprende que algunas combinaciones son especialmente frecuentes, especialmente raras o directamente imposibles. Como regla mental: mcv corrige “esta combinación exacta se comporta distinto al promedio”.
Tipo: ndistinct
ndistinct le dice a PostgreSQL cuántas combinaciones distintas de varias columnas existen realmente, en lugar de conocer solo los valores distintos de cada columna por separado.
CREATE STATISTICS stats_tel_entitlement_ndistinct (ndistinct) ON tenant_id, entitlement FROM tenant_entitlements; CREATE STATISTICS stats_url_feature_ndistinct (ndistinct) ON tenant_id, feature_name, rollup_day FROM usage_rollups; |
Como regla mental: ndistinct corrige “estos grupos o combinaciones no son tan numerosos como el planner cree”.
Qué almacena PostgreSQL
Aquí es donde se vuelve interesante. Todos estos problemas también podrían abordarse con más índices. El problema es que los índices son caros de mantener y caros en almacenamiento.
Las extended statistics, en cambio, son sorprendentemente baratas. Viven en pg_statistic_ext y pg_statistic_ext_data y son básicamente metadatos para el planner.
pg_statistic_extdescribe los objetos estadísticos.pg_statistic_ext_datacontiene los datos materializados.
En este benchmark, el coste total fue de unos 2.059 bytes:
- Tenant-Segment
mcv: ~1.049 bytes - Tenant-Segment
dependencies: ~518 bytes - Entitlement
ndistinct: ~220 bytes - Rollup
ndistinct: ~272 bytes
Ese es el punto: no son índices sombra enormes, son metadatos que hacen al planner mucho menos equivocado.
Arreglando execution plans
Cuando empecé este artículo quería demostrar sobre todo mejores tiempos. Sí hubo mejoras, pero no tan espectaculares como esperaba. Lo que sí mejoró muchísimo fueron las estimaciones, y eso suele ser aún más importante.
| Scenario | Average Time | Worst Estimate | Additional Storage |
|---|---|---|---|
| Extended statistics | 2,857.896 ms | 48.27x | 2.0 KiB |
| Baseline + Composite Join-Key Indexes | 5,882.659 ms | 106.48x | 37.64 MiB |
| Baseline + Events (feature_name, event_type, tenant_id) | 4,781.551 ms | 108.7x | 31.45 MiB |
| Baseline + Partial Hot-Path Indexes | 4,765.351 ms | 106.22x | 30.20 MiB |
| Extended Statistics + Partial Hot-Path Indexes | 4,876.187 ms | 46.65x | 30.21 MiB |
Cada query se ejecutó cinco veces. Los planes completos y las mediciones están en el repositorio.
Query de una sola región
El esquema base usa índices de una sola columna. Eso evita la ejecución totalmente secuencial, pero obliga al planner a estimar intersecciones de predicados correlacionados sobre tenants, entitlements, rollups y events.
| Metric | Value |
|---|---|
| Average execution time | 14,168.174 ms |
| Average planning time | 4.134 ms |
| Execution samples | 31,093.955 ms, 29,065.788 ms, 3,564.811 ms, 3,570.114 ms, 3,546.200 ms |
| Planning samples | 5.058 ms, 3.952 ms, 8.969 ms, 1.899 ms, 0.793 ms |
| Join chain | Nested Loop:Inner -> Nested Loop:Inner -> Nested Loop:Inner |
| Scan nodes | Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Nested Loop: 178,389 estimated / 18,774,720 actual (105.25x) |
| Worst estimate path | Sort -> Aggregate -> Nested Loop |
Con extended statistics el panorama mejora mucho:
| Metric | Value |
|---|---|
| Average execution time | 2,857.896 ms |
| Average planning time | 3.025 ms |
| Execution samples | 4,318.854 ms, 2,612.261 ms, 2,396.848 ms, 2,467.702 ms, 2,493.816 ms |
| Planning samples | 6.719 ms, 2.067 ms, 2.128 ms, 2.243 ms, 1.970 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Hash: 12,966 estimated / 625,824 actual (48.27x) |
| Worst estimate path | Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash |
El planner deja de comportarse como si el volumen intermedio fuera minúsculo. Un detalle importante: el coste estimado total sube. Eso no es una regresión, sino una señal de que PostgreSQL por fin cree en un modelo más realista.
Query multi-región
En la versión multi-región la diferencia de tiempo fue todavía más visible.
Baseline:
| Metric | Value |
|---|---|
| Average execution time | 24,933.705 ms |
| Average planning time | 3.648 ms |
| Execution samples | 84,815.859 ms, 12,696.190 ms, 11,819.487 ms, 8,482.936 ms, 6,854.054 ms |
| Planning samples | 6.125 ms, 5.681 ms, 2.067 ms, 2.181 ms, 2.187 ms |
| Join chain | Merge Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Sort: 53,580 estimated / 17,164,496 actual (320.35x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Merge Join -> Sort |
Con extended statistics:
| Metric | Value |
|---|---|
| Average execution time | 7,289.319 ms |
| Average planning time | 2.875 ms |
| Execution samples | 7,503.924 ms, 8,261.715 ms, 7,433.035 ms, 8,181.565 ms, 5,066.357 ms |
| Planning samples | 9.244 ms, 0.932 ms, 1.039 ms, 1.801 ms, 1.359 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Nested Loop: 68,387 estimated / 1,113,566 actual (16.28x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash -> Nested Loop |
Eso no es un ajuste fino menor. Es PostgreSQL volviendo a vivir en el mismo código postal que la realidad.
¿De verdad hizo las queries más rápidas?
A veces sí, a veces no. Precisamente por eso este tema merece tratarse con cuidado.
Runtime en una sola región
- Baseline media: 14,168.174 ms
- Extended statistics media: 2,857.896 ms
Eso parece espectacular, pero está muy influido por dos primeras ejecuciones extremadamente lentas en el baseline. La afirmación prudente es: una mejor comprensión del planner aquí se correlacionó con mejor comportamiento estable.
Runtime multi-región
- Solo statistics: 7,289.319 ms
- Mejor estrategia solo con índices: 6,886.473 ms
Eso no debilita el caso de CREATE STATISTICS. Lo aclara: las estadísticas mejoran cardinalidad y creencias del planner; los índices crean caminos físicos de acceso.
Por qué importa la comparación con índices
Uno de los resultados más interesantes fue que algunas estrategias cargadas de índices parecían atractivas en coste o runtime, pero seguían siendo mucho peores en calidad de estimación.
- Extended statistics: alrededor de 2.0 KiB
- Alternativas cargadas de índices: entre 30.20 MiB y 37.64 MiB

Ese es el aspecto infravalorado: con unos 2 KiB de metadatos, PostgreSQL se vuelve mucho menos incorrecto, mientras que las alternativas basadas en índices consumen decenas de MiB extra y a menudo ni siquiera resuelven el problema real del planner.
Por qué “usar ambos” no ganó automáticamente
También probé la pregunta obvia: ¿extended statistics más índices óptimos da automáticamente el mejor resultado?
No necesariamente.
Single-region:
- Solo statistics: 2,857.896 ms
- Statistics + partial hot-path indexes: 4,876.187 ms
Multi-region:
- Solo statistics: 7,289.319 ms
- Statistics + partial hot-path indexes: 8,950.207 ms
Más índices no solo crean oportunidades. También cambian el espacio de búsqueda del planner. “Usa ambos y ya” no es una ley natural; es otra pregunta de benchmark.
Caveats prácticos
Hay varias limitaciones que conviene dejar claras:
- Las extended statistics solo aplican dentro de una misma relación.
- PostgreSQL no las usa directamente para estimación de selectividad de joins entre tablas.
- No todos los workloads se benefician. Si las columnas son de verdad casi independientes, el impacto puede ser pequeño.
- No sustituyen buen diseño de queries, índices útiles, particionado, memoria razonable ni storage rápido.
Son una funcionalidad para darle mejor información al planner, no un amuleto universal de rendimiento.
Cuándo recurrir a CREATE STATISTICS
La regla práctica es simple: si un plan parece erróneo y la “rareza” está ligada a varias columnas filtradas o agrupadas juntas de una forma que el planner modela mal, piensa en extended statistics antes de crear otro índice por reflejo.
Buenos candidatos:
- columnas de filtrado muy correlacionadas,
- atributos de dimensión impulsados por segmento,
- workloads de group by con cardinalidad claramente incorrecta,
- problemas de fanout multicolumna,
- combinaciones sesgadas de valores comunes,
- planes donde una mala estimación de una sola relación envenena el resto.
Peores candidatos:
- queries cuyo problema real es un camino físico de acceso ausente,
- workloads dominados claramente por I/O,
- casos donde las columnas sí son casi independientes.
Usa EXPLAIN (ANALYZE, VERBOSE, BUFFERS). Si estimated rows y actual rows divergen muchísimo, probablemente merezca la pena probar extended statistics.
Mejor verdad que trucos
Lo mejor de CREATE STATISTICS es que obliga a alimentar al planner con más verdad en lugar de apilar estructuras adicionales sobre los datos.
Los benchmarks no dicen “extended statistics siempre ganan”. Dicen algo más útil:
- hicieron a PostgreSQL mucho menos equivocado,
- cambiaron la forma del plan de forma significativa,
- costaron casi nada en storage,
- y a menudo atacaron el problema del planner más directamente que decenas de MiB de índices extra.
Benchmark, queries y resultados están en GitHub. También puedes probar las queries tú mismo en nuestra Vela Postgres Sandbox.
Y si alguna vez miraste un plan y pensaste “no puede ser que este join deba ir anidado tres veces con gabardina”, probablemente estabas buscando extended statistics sin saberlo.