
Als wir begonnen haben, Vela zu bauen, hatten wir ein sehr konkretes und ein wenig stures Ziel: Eine neue Postgres-Umgebung sollte so schnell bereit sein, dass sie sich nicht wie „Provisioning“ anfühlt. Wir meinten nicht „schnell für einen VM-Start“, wir meinten so schnell wie nur irgend möglich. So schnell, dass Plattformingenieure von sofortiger Bereitstellung sprechen, und trotzdem mit voller Isolation.
Das bedeutete allerdings, dass wir drei Randbedingungen hatten:
- Volle Isolation zwischen Datenbanken mit harten Grenzen, nicht bloß „Isolation auf Namespace-Ebene“.
- Vollständig robust gegen Noisy Neighbors mit harten Ressourcenlimits für CPU, RAM und Festplattenaktivität.
- Kubernetes-native Skalierbarkeit mit automatischer Platzierung und unterbrechungsfreiem Ersatz per Live-Migration.
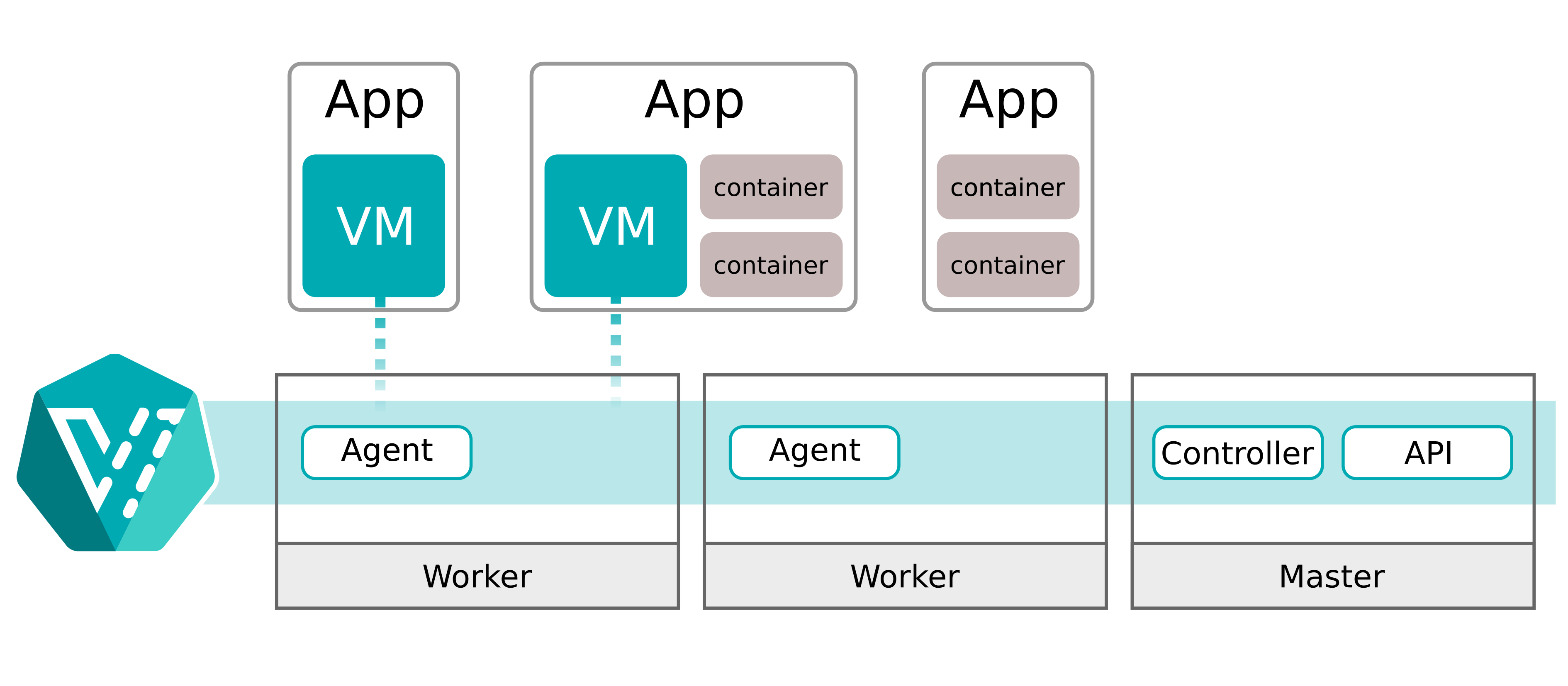
Auch wenn Velas ursprüngliches Ziel einfach und geradlinig klingt, war es unerquicklich schwer, es zu treffen. Jede Datenbank (jeder Branch) in Vela erhält starke Isolation und die Fähigkeit, sich dynamisch und unabhängig zu skalieren. Es fühlt sich so an, wie sich eine Datenbank auf Kubernetes anfühlen sollte, aber mit den Isolationsgarantien einer virtuellen Maschine.
Dieser Beitrag erzählt die Geschichte, wie wir von dort zu Starts in unter 10 Sekunden gekommen sind, während wir gleichzeitig volle Isolation zwischen Datenbanken und ein Skalierungsverhalten beibehalten haben, das sich natürlich in Kubernetes einfügt. Auf dem Weg dorthin haben wir viel über das Modell von KubeVirt gelernt (und über seine scharfen Kanten), darüber, warum Autoscaling für VMs subtil anders ist als Autoscaling für Pods, und warum ein winziges eigenes OS-Image ein größerer Performance-Hebel sein kann als fast jede Tuning-Option.
Warum wir uns für virtuelle Maschinen entschieden haben
Am Anfang haben wir uns aus einem pragmatischen Grund für VMs entschieden: Live-Migration von VMs ist ein gelöstes Problem. Sie wird von den meisten Hypervisoren unterstützt und ist in ihrer Reife noch immer deutlich weiter als Container-Live-Migration. Wir haben uns zwar Arbeiten zur Container-Migration angesehen (z. B. zeropod), aber sie passten nicht zu unseren Randbedingungen. Während es das Skalieren (sogar bis auf null) elegant behandelt, erfüllte es unsere Anforderung an unterbrechungsfreie Live-Migration nicht.
Kubernetes war ebenfalls nicht verhandelbar. Für die meisten Plattformteams ist Kubernetes „das Substrat“, und alles andere soll sich in dessen Scheduling, Observability und operativen Lebenszyklus integrieren.
Also taten wir das Offensichtliche: Wir betreiben Postgres in VMs, die trotzdem als Kubernetes-Objekte kontrolliert werden. Genau dafür ist KubeVirt gedacht: Es erweitert die Kubernetes-API um VM-Typen und führt die VM-Nutzlast über einen Pod aus, der QEMU/KVM startet.
Erster Versuch: KubeVirt, Docker und frustrierende Startzeiten
Virtuelle Maschinen auf Kubernetes? Dafür gibt es KubeVirt. Wie alle anderen kamen wir zunächst auf dieselbe Antwort. Wie schwer kann es schon sein?
Unsere erste Iteration startete an einem guten Tag in etwa 2 Minuten und an einem schlechten Tag in bis zu 5 Minuten. Sofort genug, oder? 🫣
Die Zeiten für den VM-Boot selbst waren nicht einmal so schlimm. Allerdings war das Starten der VM nur der Anfang. In der VM starteten wir Docker (Compose) und zogen und luden dann pro Branch mehrere Container-Images, im Grunde sämtliche Services für jeden Branch (Postgres, PGBouncer, PostgREST, …). Docker-Hub-Throttling und die „Image-Pull-Lotterie“ erwiesen sich als brutale Quelle für Tail-Latenz.
Der Boot-Prozess war unerquicklich:
- Kubernetes erstellt die KubeVirt-VM-Ressourcen
- Die VM-Ressource startet QEMU
- Das Gastbetriebssystem bootet
- Der Docker-Dienst wird verfügbar
- Docker lädt die einzelnen Container-Images herunter
- Docker startet die Container nacheinander gemäß des Abhängigkeitsgraphen
- Die Container fahren hoch und werden healthy
- Wir markieren den Branch als aktiv (healthy)
Wir wussten, dass es nicht optimal war, die Images jedes Mal beim Start einer VM herunterzuladen, aber wir hatten nicht erwartet, dass es so schlimm sein würde. Das Hauptproblem ist, wie Docker Image-Downloads und Container-Starts handhabt. Im Wesentlichen lädt es zuerst alle Images herunter und startet sie dann entsprechend des Container-Abhängigkeitsgraphen. Ein großes oder langsam (gedrosselt) geladenes Image reicht aus, und der Tag ist gelaufen. Mit jedem zusätzlichen Image steigt die Wahrscheinlichkeit, einen schlechten Tag zu erwischen.
Insgesamt identifizierten wir drei Komponenten, die die Latenz verstärkten, in der Reihenfolge ihres Einflusses (hoch bis niedrig):
- Image-Pulls und Registry-Throttling, um Branch-Service-Images verfügbar zu machen.
- Den zweistufigen Start mit der VM und den Docker-Containern.
- Zusätzliche Setup-Schritte, etwa das Registrieren des DNS-Namens, das Provisionieren eines neuen Datenträgers, das Ausführen von Postgres’ initdb und Ähnliches.
Lasst uns Docker-Images vorab cachen
Zuerst mussten wir das ständige Herunterladen loswerden. Wenn dein Boot-Pfad „Abhängigkeiten herunterladen“ enthält, hast du keine Boot-Zeit. Du hast eine Wahrscheinlichkeitsverteilung.
Wir bauten ohnehin ein VM-Image, also warum nicht „einfach“ alle benötigten Container-Images schon während des Build-Prozesses herunterladen?
Gesagt, getan. Das heißt, wir haben den Build-Prozess um einen Schritt erweitert, der alle benötigten Docker-Images herunterlädt und sie in das finale VM-Boot-Image einbettet.
Das funktionierte großartig. Die größte Quelle der Boot-Zeit-Variabilität war verschwunden. Wir lagen nun ziemlich konstant bei einer Basis von 90 bis 100 Sekunden. Ein Großteil der Zeit ging aber immer noch dafür drauf, das Linux-Image zu booten und darauf zu warten, dass der Docker-Dienst verfügbar wird, bevor wir endlich unsere eigentlichen Branch-Services starten konnten. Für einen ersten Schuss war das gut genug. Wir wussten aber, dass weiteres Optimierungspotenzial darin lag, nicht einfach ein typisches Linux-Image zu booten, sondern den Boot-Prozess selbst zu optimieren.
Warum Docker?
Eine der naheliegenden Fragen lautet: „Warum zum Teufel habt ihr Docker innerhalb der VM verwendet?“
Die kurze Antwort ist nur ein Wort: Komfort.
Die lange Antwort lautet: Komfort in Form schnellerer Iterationszyklen, indem wir verschiedene Docker-Images einsetzen und unterschiedliche Service-Optionen testen konnten (wie Pgpool-II, PGBouncer und andere).
Wir wollten experimentieren können, ohne jedes Mal virtuelle Maschinen neu zu bauen, und Docker war damals die perfekte Lösung. Es hätte außerdem Datenbank-Upgrades wirklich einfach gemacht. Bei Major-Version-Upgrades von Postgres braucht man zwei Postgres-Versionen installiert: die neue und die aktuelle. Mit Docker wäre das nur einen Download entfernt gewesen. Das Basis-Image der neuen Version verwenden, nach dem Boot die alte Version schnell herunterladen, die Migration durchführen und das alte Container-Image wieder entfernen. Fertig.
Wie auch immer: Bevor wir zu den anderen Latenzfaktoren zurückkehren konnten, schlichen sich bereits neue Probleme an.
Als KubeVirt anfing, uns im Weg zu stehen
Wir wollen deutlich machen, dass keines der folgenden Probleme einfach „KubeVirt ist schlecht“ bedeutet. Tatsächlich löst KubeVirt ein sehr schwieriges Problem und tut dies auf die denkbar Kubernetes-konformste Weise.
Unser Zielverhalten (schnelle, häufige, elastische, datenbankförmige VMs) belastete jedoch andere Teile des Systems. Es war eben nicht die typische „langlebige“ VM, deren Anwendungsfall sich nie ändert. KubeVirt ist großartig, wenn man den Komfort von Kubernetes und den typischen Lebenszyklus sowie die Isolation einer virtuellen Maschine haben möchte. Wir hingegen wichen von diesem Muster ab, und das begann sich zu zeigen.
Eine virtuelle Maschine zu skalieren ist nicht dasselbe wie einen Pod zu skalieren
Der erste Reibungspunkt war, dass VM-Ressourcenskalierung für CPU und RAM bei uns nicht selten ist. Wir wollten dynamisch hoch- und herunterskalieren, und zwar so oft und so schnell wie möglich. Im Idealfall inklusive Scale-to-zero.
In KubeVirt lösen solche Änderungen sofort eine Live-Migration aus. Selbst dann, wenn auf dem aktuellen Host noch genügend Ressourcen verfügbar sind. Der Hauptschmerzpunkt ist, dass die Live-Migration die VM immer auf einen anderen Kubernetes-Worker verschiebt. Zwar ist der Performance-Einfluss einer Live-Migration begrenzt, aber das ständige Bewegen der virtuellen Maschinen hätte für uns nicht funktioniert.
“Current hotplug implementation involves live-migration of the VM workload.” KubeVirt Authors, “Memory Hotplug” documentation (KubeVirt.io)
Für einen typischen VM-Lebenszyklus ergibt diese Designentscheidung absolut Sinn. Für uns bedeutete sie jedoch, dass jedes „Resize“ zu einem „die ganze Welt verschieben“ wurde, mit Kaskadeneffekten in Netzwerkkomplexität und Verbindungsstabilität zur Datenbank.
Wir brauchten eine Lösung, die eine virtuelle Maschine nur dann live migriert, wenn wirklich keine Ressourcen verfügbar sind, und lokales Hoch- und Herunterskalieren für CPU und RAM ermöglicht.
Live-Migration und TCP-Sessions sind eine brutale Kombination
Wir stießen außerdem auf eine härtere Wahrheit: Live-Migration ist nur dann „nahtlos“, wenn dein Netzwerk-Stack und die Migrations-Pipeline die Invarianten erhalten, von denen dein Workload ausgeht. Postgres-Clients verzeihen keine längeren Stalls.
Datenbanken sind latenzsensitiv und verbindungsorientiert. Unsere internen Tests zeigten, dass selbst kleinste Unterbrechungen unter anhaltenden Verbindungstests schnell sichtbar werden. Vorgeschlagene Lösungen wie passt reduzierten die Last, aber unter moderater bis hoher pgbench-Last sahen wir weiterhin Verbindungsabbrüche.
Und wir waren damit offenbar nicht allein. Für KubeVirt gibt es öffentliche Issues und Community-Diskussionen über Netzwerkprobleme nach einer Migration. So existiert zum Beispiel schon lange ein Bericht darüber, dass nach einer Migration die Konnektivität am Masquerade-Interface abbrechen kann. Andere Community-Mitglieder beschrieben, dass Verbindungen verloren gehen, weil sich während der Migration die zugrunde liegende Pod-/Netzwerkidentität ändert.
Wir brauchten echtes Overlay-Networking.
Doppelte Ressourcenbuchhaltung: Pod vs. VM
Ein weiterer Stolperstein: Ressourcensteuerung findet auf mehreren Ebenen im Stack statt.
- Die Ebene der virtuellen Maschine ist das, was QEMU glaubt, der VM zur Verfügung zu stellen.
- Die Pod-/Cgroup-Ebene ist das, was Kubernetes dem virt-launcher-(QEMU-)Pod tatsächlich auferlegt.
In unseren Experimenten stellten wir fest, dass CPU- und Speicherzuweisungen effektiv sowohl auf VM- als auch auf Pod-Ebene verwaltet werden mussten. Nur die Pod-Ebene zu aktualisieren, führte in der VM zu Out-of-Memory-Problemen. Das hängt mit dem oben erwähnten Skalierungsproblem zusammen.
Um Teile des Problems zu entschärfen und Live-Resizing zu ermöglichen, mussten wir an KubeVirt vorbei arbeiten und die VMs direkt über libvirt aktualisieren. Wir mussten dabei sehr vorsichtig sein, das System nicht zu beschädigen, denn jedes einzelne Reconciliation-Ereignis auf einer KubeVirt-VM-Ressource hätte manuelle Änderungen wieder ungültig gemacht.
Wir brauchten einen sichereren Weg.
Zeit weiterzuziehen
Wir gerieten mehrfach in Situationen, in denen wir Workarounds brauchten, die sich nicht sauber in die unterstützte API-Oberfläche einfügten, und die nächste Reconciliation hätte sie wieder rückgängig gemacht. KubeVirt zu patchen hätte viel Arbeit bedeutet, und wir wollten kein langlebiges Fork eines so zentralen Projekts mit uns herumschleppen, nur um weiterzukommen.
Also fragten wir uns:
- „Ist KubeVirt eine gute Virtualisierungs-API für Kubernetes?“ Ja, ist es.
- „Ist KubeVirt eine gute Abstraktion für unseren Branch-Lebenszyklus und unser Skalierungsmodell?“ Wir denken: nein.
Also taten wir, was Open-Source-Bauer eben tun. Wir suchten nach einem anderen Ansatz, der besser zu unseren Anforderungen passt. Im Grunde gab es zwei Möglichkeiten: eine bessere bestehende Lösung finden oder alles von Grund auf selbst und gezielt entwickeln.
Unser erster Gedanke war, unsere eigene Abstraktion direkt auf libvirt oder QEMU aufzusetzen. Aber als wir uns in die Größe des KubeVirt-Quellcodes einarbeiteten und die benötigten Features abzuschätzen begannen, erkannten wir die Dimension der Aufgabe.
Eine virtuelle Maschine mit Kubernetes zu verheiraten ist harte Arbeit. Zu viele Konzepte laufen auseinander und müssen dann wieder zusammengeführt werden. Das hat uns Respekt eingeflößt. Also entschieden wir uns, zuerst nach anderen Lösungen zu suchen. Nach etwas, das näher an dem lag, was wir brauchten. Und wir hatten Glück.
Der Schwenk: Neons Autoscaling übernehmen
Der bessere Ansatz ist, eine andere Lösung zu suchen, wenn man eine finden kann, die die eigenen Anforderungen besser erfüllt. Und genau das taten wir.
Der Ansatz war simpel und naheliegend, wenn man darüber nachdenkt: Schau dir benachbarte Unternehmen und deren Lösungen an. Glücklicherweise gibt es da draußen viele Datenbanken. Viele davon sind Open Source. Viele sind Postgres(-nah).
Als wir auf Neons Autoscaling-Projekt stießen, erkannten wir außerdem, dass wir nicht die Ersten waren, die an die oben beschriebenen Grenzen geraten waren. Neon stand vor vielen derselben Probleme und entschied sich deshalb, seine eigene Lösung dafür zu schreiben. Ihr Ansatz war kompromisslos datenbankförmig. Er war für vertikales Autoscaling von Postgres in Kubernetes-verwalteten Micro-VMs (QEMU-basiert) entwickelt worden. Und sie lösten auch den kniffligen Teil: „TCP-Sessions nicht abbrechen, wenn sich Ressourcen ändern oder der Workload umzieht.“
Der interessanteste Teil von Autoscaling ist, wie Skalierungsentscheidungen getroffen werden und wie das Skalieren selbst funktioniert.
Zunächst verwendet Autoscaling Cgroups, um Ressourcen (CPU und Speicher) für die Nutzungsberichterstattung einzugrenzen. Um die Auslastung eines „Hosts“ (der Gast-VM) zu erfassen, werden über Prometheus gesammelte Metriken genutzt. Alle paar Sekunden wird die aktuelle Auslastung gegen potenzielle Up- oder Downscaling-Ereignisse bewertet. Außerdem kann der Agent innerhalb der virtuellen Maschine proaktiv Skalierungsentscheidungen anfordern, diese können jedoch abgelehnt werden.
Da Autoscaling unter der Haube QEMU verwendet, können CPU und Speicher im laufenden Betrieb per Hot-Plug hinzugefügt oder entfernt werden. CPU-Kerne werden zur Laufzeit an die virtuelle Maschine angehängt oder von ihr gelöst. Mit dem Speicher funktioniert es ähnlich: Über virtio-mem-Geräte kann Speicher hinzugefügt oder entfernt werden. Der Linux-Kernel verschiebt Speicherbereiche, die entfernt werden sollen, bevor ein virtio-mem-Gerät abgetrennt wird (ähnlich wie beim Ballooning).
“We want to dynamically change the amount of CPUs and memory of running Postgres instances, without breaking TCP connections to Postgres.” Neon Autoscaling README (GitHub)
Autoscaling-Komponenten
Autoscaling selbst ist eine Menge von Komponenten, die zusammenspielen, um serverless Postgres in Kubernetes zu ermöglichen.
- Ein Controller (neonvm-controller), der die Ressourcen der virtuellen Maschinen (CRDs) verwaltet.
- Ein Scheduler, der die Node-Kapazität auswertet und Entscheidungen zu VM-Platzierung und -Ersatz trifft.
- Ein Agent pro Node (DaemonSet), der die Ressourcennutzung der VMs erfasst und meldet.
- Ein VM-Monitor, der neben dem Workload läuft und die Nutzung über Prometheus meldet, mit cgroup-spezifischer Konfiguration.
- Ein VXLAN-Manager, der zusammen mit Flannel durch virtuelle Netzwerkschnittstellen und Overlay-Networking für beständige Konnektivität sorgt.
- Ein Runtime-Image, das die VM umhüllt. Es stellt das VM-Image bereit, startet QEMU, kümmert sich um DHCP/Port-Forwarding und verwaltet Mounts.
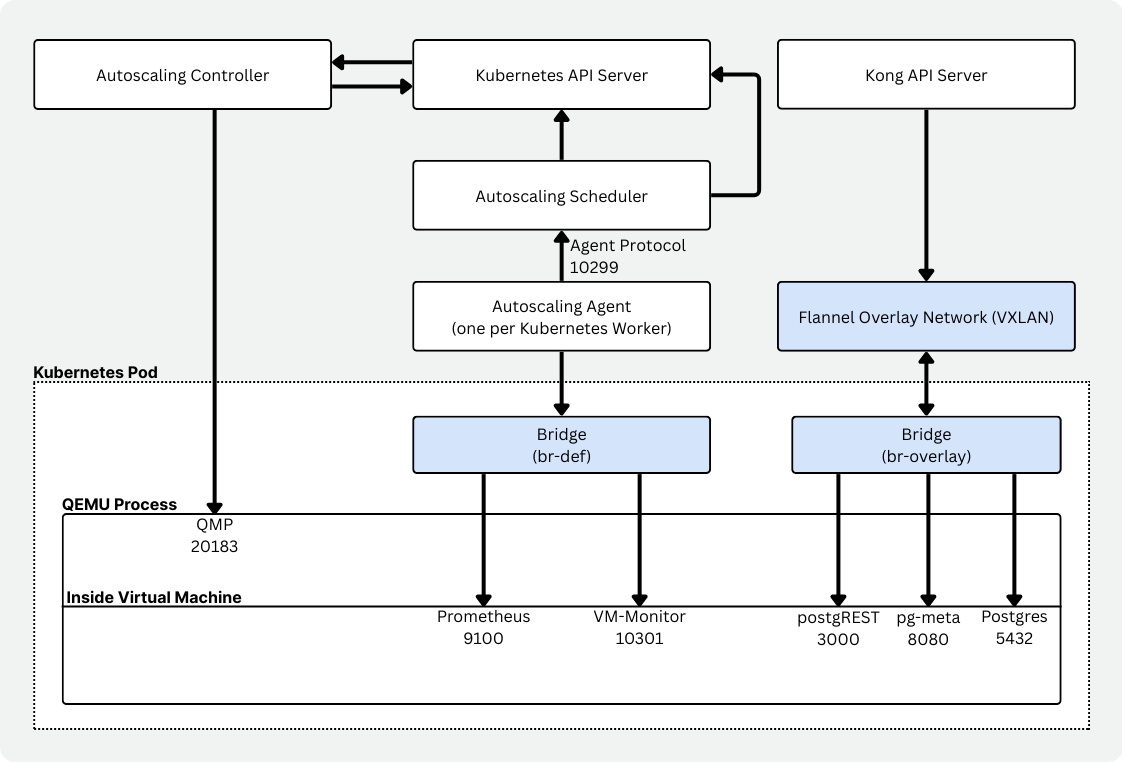
Man sieht dieselbe konzeptionelle Aufteilung: einen eigenen Scheduler, einen Autoscaling-Agenten pro Node und einen VM-Monitor, der sofort auf Speicherdruck reagieren kann. Für Vela war das ein viel besserer Match.
Vielen Dank an das Neon-Team hinter Autoscaling für diese großartige Arbeit!
Änderungen waren trotzdem nötig
Doch obwohl Autoscaling bereits sehr gut passte, gab es einige „raue Kanten“, die sich aus den Unterschieden zwischen Neon und Vela ergaben.
Zunächst brauchten wir, weil simplyblock als zugrunde liegender Storage verwendet wird, Unterstützung dafür, einen oder mehrere PVCs (Persistent Volume Claims) an die virtuelle Maschine anzuhängen.
Dann wollten wir CPU- und RAM-Nutzung begrenzen, ohne die Möglichkeit zu verlieren, diese Limits live zu aktualisieren. Leider muss QEMU wissen, welches Maximum an CPU und RAM grundsätzlich attachbar ist. Diese Werte mussten deutlich höher sein, als wir realistischerweise erwarten, dass Nutzer skalieren. Deshalb erweiterten wir den Entscheidungsprozess um ein Soft Limit. Aktuelle VMs haben ein hartes Limit von 128 vCPUs und 256 GB Speicher. Das Soft Limit beschreibt dagegen die aktuellen maximalen Skalierungsfaktoren, etwa 8 vCPUs oder 16 GB RAM. Anfragen oberhalb dieser Soft Limits werden abgelehnt.
Zu guter Letzt fügten wir einen einfachen PowerState hinzu, der es uns ermöglicht, die virtuelle Maschine durch bloßes Aktualisieren des Werts im CRD zu starten und zu stoppen. Reiner Komfort.
Boot-Zeit gewinnen: „Docker in der VM“ abschaffen
Nachdem Autoscaling einen großen Teil der Friktion beim Lebenszyklus und beim Skalieren gelöst hatte, war es Zeit, zum eigentlichen Problem zurückzukehren: zur Boot-Zeit. Der wahre Durchbruch bei der Boot-Zeit kam, als wir ehrlich zu uns selbst waren. Was wir beim Start taten, war schlicht dumm. Wir hatten Bequemlichkeit für uns über die Nutzererfahrung gestellt. Wir booteten eine allgemeine Linux-Distribution, starteten Docker und orchestrierten dann mehrere Services über Container-Images. Also entfernten wir die gesamte innere Container-Schicht.
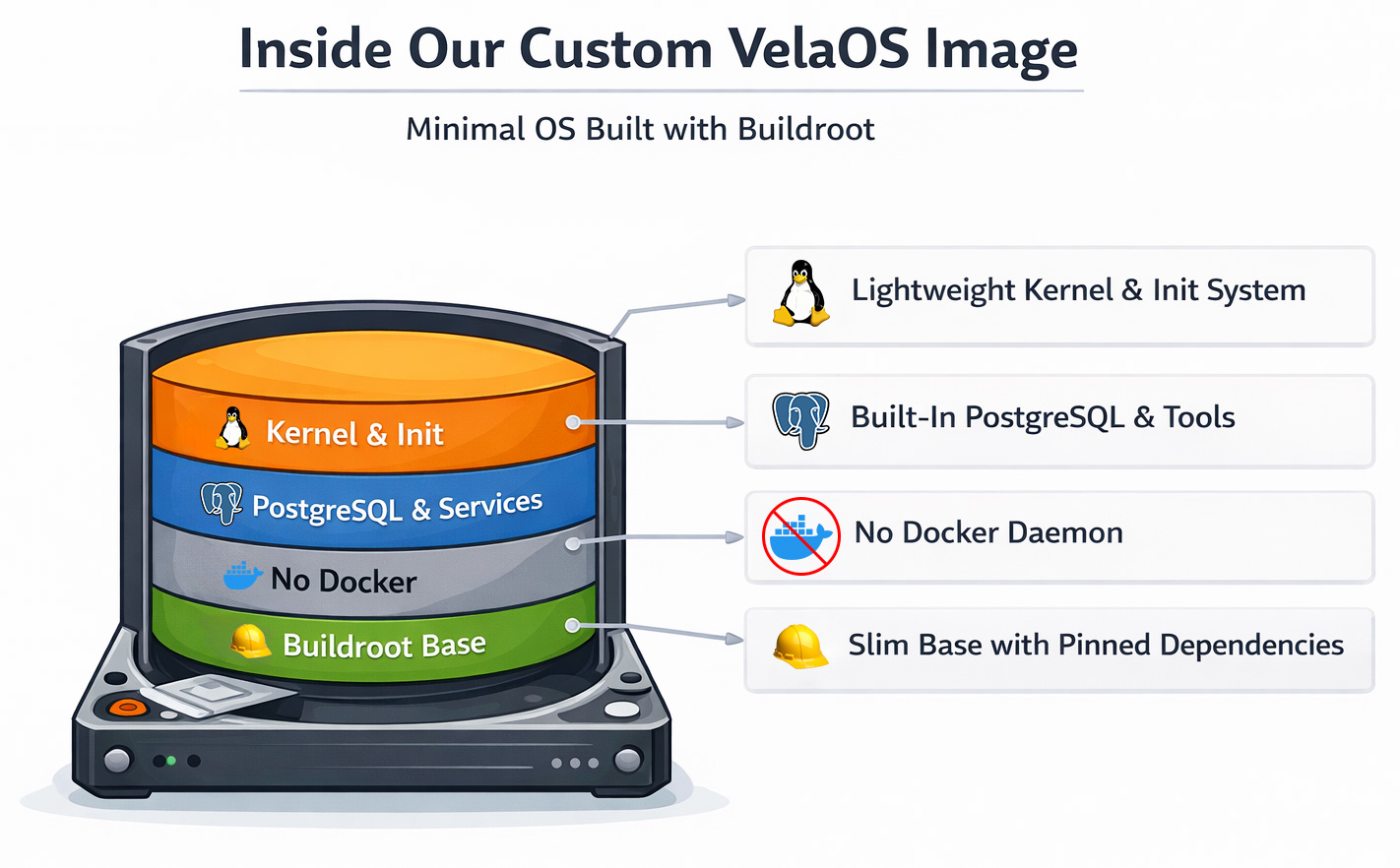
VelaOS: Ein eigener Linux-Kernel und Rootfs auf Buildroot-Basis
Wir wechselten zu einem eigenen Linux-Image auf Basis von Buildroot. Buildroot selbst ist ein Framework zum Bauen von Linux-Kerneln und eines minimalen Root-Dateisystems. Ursprünglich für eingebettete Geräte entwickelt, unterstützt es schreibgeschützte Dateisystem-Images, Geräte-Updater und mehr.
Auch wenn du Buildroot vielleicht bisher nicht kanntest: Es ist tatsächlich ein weit verbreitetes System. Bekanntere Nutzer sind OpenWRT, Home Assistant OS (HAOS) sowie Hersteller eingebetteter Geräte wie Google Fiber. Buildroot ist für seine minimalen Root-Dateisysteme bekannt.
Der Wechsel zu Buildroot brachte uns neben dem Wegfall von Docker noch einige schnelle Gewinne:
- Der Boot-Prozess wurde deterministisch, weil wir inittab als Basissystem für Init verwenden und damit exakt kontrollieren, was wann startet.
- Keine Docker-Pulls mehr, weil alle Services in das Boot-Image integriert sind.
- Höhere Boot-Geschwindigkeit, weil wir kein allgemeines Betriebssystem-Image, sondern einen optimierten Linux-Kernel verwenden.
- Reproduzierbare Builds, weil jede Komponente auf eine bestimmte Version oder einen bestimmten Commit samt Checksumme gepinnt ist und so nur unveränderte Komponenten gebaut werden.
Auf der anderen Seite verloren wir Geschwindigkeit in der Entwicklung. Buildroot baut als Build-Framework die meisten Komponenten des finalen Images selbst. So erreicht es unglaublich kleine Disk-Images, allerdings auf Kosten der Build-Zeit. Dank CCache und anderer Optimierungstechniken blieb das dennoch beherrschbar.
Der resultierende Boot-Pfad ist einfach:
- Kubernetes schedult den VM-Pod (über die Entscheidungen des Autoscaling-Schedulers).
- Die Runtime startet QEMU mit unserem VM-Image.
- Das Gastsystem bootet ein minimales OS mit bereits installierten Diensten.
- Postgres und die unterstützenden Branch-Services kommen sofort hoch (ohne Downloads).
Es gibt weiterhin Verbesserungspotenzial. Aber im Moment glauben wir, dass <10 Sekunden gut genug sind. Der Wert von Vela ist: „Branches erscheinen schnell, verhalten sich konsistent und isolieren hart.“
Isolation und Skalierbarkeit: Warum es sich immer noch nach Kubernetes anfühlt
Eine berechtigte Sorge ist: „Wenn ihr KubeVirt verlassen und eigene VM-Mechanik gebaut habt, habt ihr dann nicht die Kubernetes-Ergonomie verloren?“
In der Praxis haben wir die geliebten Teile von Kubernetes behalten. Wir haben weiterhin deklarative Kontrolle über CRDs und Controller, die den gewünschten Zustand reconciliaten. Scheduling wird über Kubernetes umgesetzt, wobei die Platzierung durch Autoscaling-Scheduler und Agent beeinflusst wird. Node-bezogene Ressourcenbeschränkungen liefern die Grundlage für Platzierungs-, Skalierungs- und Migrationsentscheidungen basierend auf realer Node-Kapazität und tatsächlicher VM-Nutzung. Und schließlich werden Isolationsgrenzen erzwungen, indem jeder Datenbank-Branch seine eigene VM-Grenze bildet.
All das, während wir weiterhin die Möglichkeit bewahren, einen Vela-Branch vollständig live von einem Kubernetes-Worker auf einen anderen zu migrieren, ohne bestehende Postgres-Verbindungen zu zerstören.
Schneller Boot ist auch ein Control-Plane-Feature
Aber eine Boot-Zeit unter 10 Sekunden verbessert nicht nur die Nutzererfahrung. Sie verändert auch, was und wie man baut:
- Vela kann aggressiver hochskalieren, weil zusätzliche Kapazität billig ist, horizontal über mehr virtuelle Maschinen und vertikal über Live-Resizing von VM-Limits.
- Vela kann Umgebungen als ephemer behandeln, weil die Kosten einer Neuerstellung gering sind und Storage und Compute vollständig getrennt sind.
- Vela kann Ausfälle absorbieren, indem es die VM ersetzt, statt sie zu reparieren.
Das ist die Form eines Systems, das irgendwann Nutzer, Agents und CI-Workflows bedienen kann, ohne den Nutzer warten zu lassen.
Was wir gelernt haben: Es ist immer komplizierter, als man denkt!
„VMs vs. Container“ ist nicht die eigentliche Debatte, sondern Determinismus im Boot-Pfad.
Wir starteten aus guten Gründen mit VMs (Migrationsreife, starke Isolation), aber unsere schlimmsten Verzögerungen kamen aus unserer eigenen Liebe zu Komfort und schneller Iteration. Der Docker-Start plus die Image-Pulls. In dem Moment, in dem wir „Images beim Boot ziehen“ entfernt hatten, hörte Time-to-Ready auf, ein Glücksspiel zu sein.
Kubernetes-Reconciliation ist Freund und Feind zugleich.
Wenn du dich dabei ertappst, „gegen den Reconciler zu arbeiten“, solltest du das als Zeichen verstehen, dass du außerhalb des beabsichtigten Erweiterungsmodells unterwegs bist. Dann solltest du entweder näher an unterstützte Muster heranrücken oder ein Substrat wählen, das besser zu deinen Kontrollbedürfnissen passt.
Die schnellste Optimierung besteht meistens darin, Dinge zu entfernen.
Genauso wie der schnellste Code der ist, der nie ausgeführt wird, besteht die schnellste Optimierung darin, unnötige Komponenten zu entfernen. In unserem Fall eliminierte das vollständige Entfernen von Docker Compose und Container-Image-Pulls Minuten an Variabilität.
Live-Migration ist kein einzelnes Feature, sondern eine ganze Produktoberfläche.
KubeVirt und Autoscaling gehen Migration sehr unterschiedlich an. Während bei KubeVirt fast jede CPU- oder Speicheränderung in einer Live-Migration endet, versucht Autoscaling, so viel wie möglich auf der bestehenden VM-Instanz zu erledigen und migriert erst, wenn physische Ressourcen knapp werden. Der andere große Unterschied ist eine stabile Netzwerkidentität durch ein echtes Overlay-Netz statt Hacks auf der Kubernetes-Netzebene. Wenn dein Workload datenbankartig ist, muss das Ereignis „es wurde migriert“ für Clients unsichtbar bleiben, sonst verbringst du dein Leben damit, gegen Reconnect-Stürme und Tail-Latenz zu kämpfen.
Minimale OS-Images bringen nicht nur Geschwindigkeit. Sie reduzieren operative Entropie.
Ein kleines, zweckgebautes Image hat weniger bewegliche Teile. Das bedeutet weniger überraschende Interaktionen, weniger Hintergrund-Daemons, die „hilfreiche“ Dinge tun, und eine kleinere Debugging-Oberfläche, wenn etwas schiefläuft. Mit VelaOS auf Basis von Buildroot erreichten wir außerdem reproduzierbare Builds und die Möglichkeit, genau zu zertifizieren, was sich zu jedem Zeitpunkt in der VM befindet (außer den Daten).
Hab keine Angst davor, Respekt zu haben. Manchmal führt das zu einem großartigen Ergebnis.
Als wir untersuchten, unsere eigene KubeVirt-Alternative zu bauen, war der Umfang der Aufgabe einschüchternd. Einschüchternd genug, dass wir die Zeit investierten, nach anderen möglicherweise schon existierenden Lösungen zu suchen. So kamen wir zu Autoscaling. Und wir sind froh, dass wir diesen Respekt hatten.
KubeVirt leistet wichtige Arbeit für das Kubernetes-Ökosystem.
Ohne KubeVirt, das die ersten Schritte gemacht hat, virtuelle Maschinen nach Kubernetes zu bringen, wären wir heute vielleicht nicht hier. Es lohnt sich, ausdrücklich zu sagen, dass KubeVirt wichtige Arbeit für das Ökosystem leistet. Selbst dort, wo wir auf Grenzen gestoßen sind, entwickelt sich das Projekt aktiv weiter. So verfolgt die KubeVirt-Community selbst Verbesserungen bei Migration-Targeting und der Kopplung von Resize und Migration, wie in Issues wie #15625 zu sehen ist. Und KubeVirt dokumentiert weiterhin reale Integrationen, etwa den gemeinsamen Betrieb mit dem Cluster Autoscaler in Cloud-Umgebungen.
Wohin wir als Nächstes wollen
Wir sehen das nicht als „KubeVirt vs. Neon Autoscaling“. Es gibt mehrere valide Ansätze, VMs auf Kubernetes zu betreiben, und die beste Wahl hängt von der Form des jeweiligen Workloads ab.
KubeVirt ist eine mächtige, allgemeine Virtualisierungsschicht für Kubernetes, und wir verfolgen seine Entwicklung weiterhin genau.
Für Velas primäre Ziele, etwa schnelle ephemere Datenbank-Branches mit starker Isolation, brauchten wir aber eine Control Plane und einen Runtime-Pfad, die kompromisslos auf Datenbanken optimiert sind.
Neons Autoscaling lieferte dafür das richtige Fundament, und Vela OS machte die Boot-Zeit vorhersagbar.
Wenn du etwas in diesem Bereich baust, würden wir sehr gern über deine Erfahrungen, Entscheidungen und weitere Edge Cases sprechen. Besonders über Networking, Migrationsverhalten oder VM-Image-Design.
In naher Zukunft werden wir beginnen, die von uns vorgenommenen Verbesserungen upstream einzubringen. Wir glauben an ein gesundes Open-Source-Ökosystem und wollen die Änderungen teilen, statt sie privat zu halten.
Wenn du unsere Vela-Postgres-Instanzen erleben und testen möchtest, erstelle deinen kostenlosen Account unter https://demo.vela.run. Vela ist vollständig Open Source und für Self-Hosting im eigenen Rechenzentrum oder in der Private Cloud gedacht. Im Moment räumen wir noch den Code auf, beheben verbleibende Bugs und implementieren den nutzerseitigen Installationsablauf.