
Kurzfassung: Wenn Queries langsam sind, denkt man zuerst an Indizes. PostgreSQL hat dafür viele Werkzeuge, von Multi-Column- über Partial- bis hin zu Expression-Indizes. Das Problem: Jeder zusätzliche Index kostet Storage, Schreibaufwand und WAL. Was viele übersehen: Extended Statistics. Sie verbessern Query-Pläne fast ohne zusätzlichen Speicherbedarf.
Das eigentliche Problem hinter vielen schlechten Plänen ist nicht Faulheit des Planners, sondern ein falsches Bild der Daten. Wenn mehrere Filter korreliert sind, reichen per-Column-Statistiken oft nicht aus. Genau hier setzt CREATE STATISTICS an.
Die Kurzversion
CREATE STATISTICS erlaubt Postgres, zusätzliche Informationen zu sammeln, die normale Spaltenstatistiken nicht ausdrücken können.
Praktisch hilft das vor allem bei vier Problemen:
- korrelierten Filtern über mehrere Spalten,
- Distinct-Schätzungen über mehrere Spalten,
- schiefen, ungleich verteilten Wertekombinationen,
- Ausdrücken, bei denen man sonst einen Expression-Index bauen würde.
–-- Alternative to index on expressions CREATE STATISTICS stats_expr ON (date_trunc(‘day’, created_at)) FROM events; --- What people normally mean by --- extended statistics CREATE STATISTICS stats_multi (dependencies, ndistinct, mcv) ON plan_tier, region, billing_status FROM tenants; |
Die erste Form hilft zum Beispiel bei Ausdrucksstatistiken wie date_trunc oder JSONB-Extraktion. Die zweite Form ist das, was die meisten mit „Extended Statistics“ meinen.
Es gibt drei relevante Statistikarten: dependencies, ndistinct und mcv. Und wie bei normalen Statistiken gilt: CREATE STATISTICS definiert nur das Objekt, ANALYZE füllt es mit Daten.
Warum Extended Statistics?
Postgres legt standardmäßig vor allem Statistiken pro Spalte an. Das funktioniert gut, solange einzelne Filter unabhängig betrachtet werden können. Problematisch wird es, wenn Beziehungen zwischen Spalten entscheidend sind.
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
In realen Daten sind solche Prädikate oft korreliert. Ohne zusätzliche Statistik behandelt PostgreSQL sie aber so, als ob jede Bedingung die Zeilenmenge unabhängig reduziert. Das führt zu formal sauberen, operativ aber absurden Schätzungen.
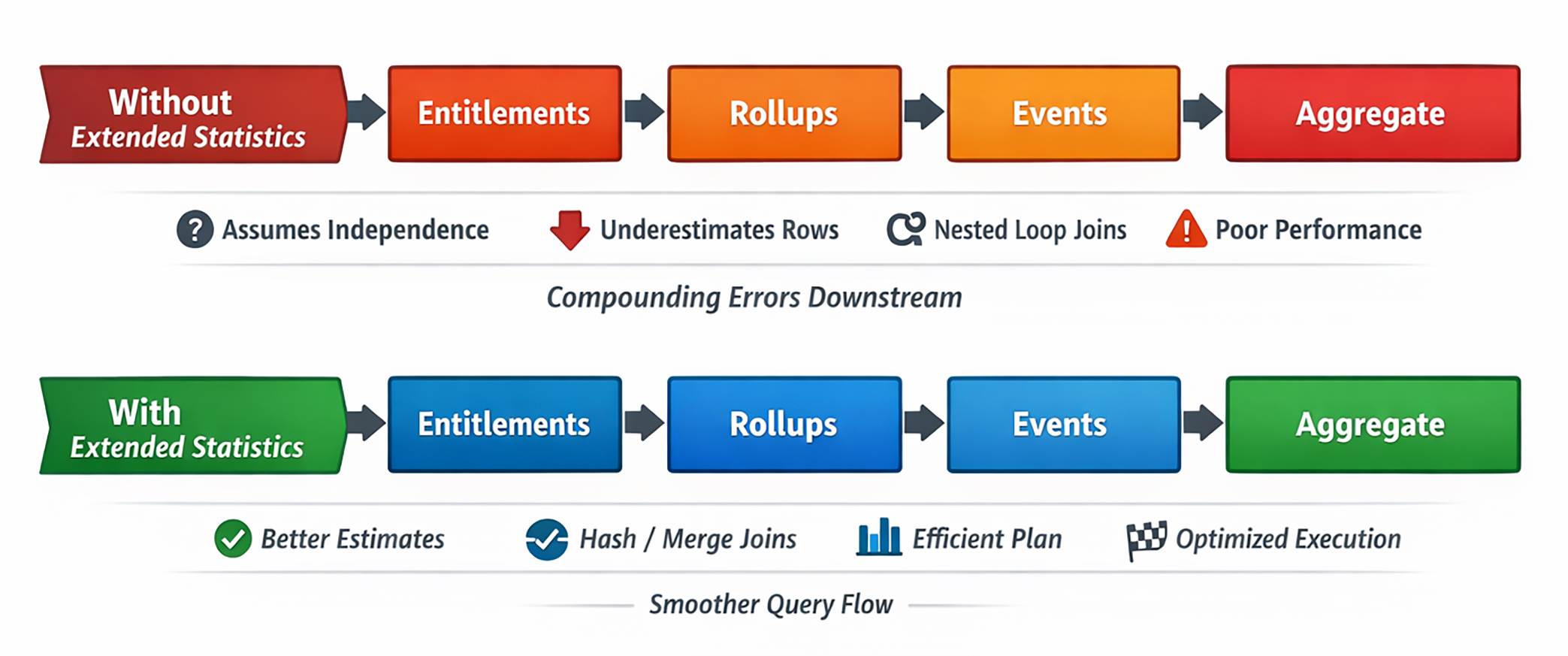
Und sobald die Schätzung am Anfang falsch ist, wird danach fast alles wackelig: Join-Reihenfolge, Join-Typ, Parallelisierung, Hash-Größe, Sort-Strategie, Spill-Risiko.
Was Postgres standardmäßig weiß
Mit jedem ANALYZE speichert PostgreSQL pro Spalte Informationen wie Null-Anteile, Histogrammgrenzen, häufige Werte oder Distinct Counts. Das ist nützlich, aber eben nur spaltenlokal.
Bei einer Tabelle mit einer Million Zeilen könnte Postgres beispielsweise so rechnen:
plan_tier = 'enterprise'trifft 6 %region = 'eu-central'trifft 25 %billing_status = 'active'trifft 80 %
1,000,000 * 0.06 * 0.25 * 0.80 = 12,000 rows |
Das Problem: In der Realität sind diese Spalten oft nicht unabhängig. Die echte Antwort kann 40.000, 60.000 oder auch nur 5.000 Zeilen sein. Normale Einzelspaltenstatistiken können das nicht sagen.
Benchmarking von Extended Statistics
Um das greifbar zu machen, habe ich einen synthetischen, aber bewusst realistischen SaaS-Analytics-Workload mit vier Tabellen gebaut: tenants, tenant_entitlements, usage_rollups und analytics_events.
Der Datensatz wurde gezielt so geformt, dass die Schwächen des Planners sichtbar werden: Korrelationen zwischen Tarif, Region und Billing-Status, konzentrierte Premium-Entitlements und nicht zufällige (tenant, feature, day)-Verteilungen.
Die Daten sind synthetisch, aber so synthetisch wie ein Windkanal: kontrolliert, um ein reales Phänomen isoliert zu zeigen.
Das Problem über Datenformen isolieren
Tabelle: tenants
Die Segmentierung nach Tarif, Region und Billing-Status ist bewusst korreliert, wie in realen SaaS-Daten.
Tabelle: tenant_entitlements
Premium-Features wie sso, audit_logs oder workflows sind häufiger bei Enterprise-Tenants konzentriert.
Tabelle: usage_rollups
Diese Tabelle modelliert realistische zeitgebundene Fanout-Effekte pro Tenant-Feature-Kombination.
Tabelle: analytics_events
Hier liegt die eigentliche Explosion. Für jede passende Tenant-Feature-Kombination gibt es potenziell viele Rohereignisse, besonders bei „heißen“ Kombinationen.
Die Reporting-Query
Die zentrale Frage lautet: „Welche Premium-Features erzeugen unter aktiven Enterprise-Tenants in einer wichtigen Region zuletzt die meiste Aktivität?“
SELECT e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.region = 'eu-central' AND t.billing_status = 'active' AND te.entitlement IN ('sso', 'audit_logs') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY e.feature_name ORDER BY rolled_requests DESC; |
Für mehrere Regionen gleichzeitig gibt es eine leicht erweiterte Variante mit CTE und nachgelagerter Aggregation.
WITH regional_feature_totals AS ( SELECT t.region, e.feature_name, count(*) AS total_events, sum(r.request_count) AS rolled_requests FROM tenants t JOIN tenant_entitlements te ON te.tenant_id = t.id JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') AND te.entitlement IN ('sso', 'audit_logs', 'workflows') AND r.rollup_day >= CURRENT_DATE - 30 AND e.event_type IN ('view', 'click', 'run') GROUP BY t.region, e.feature_name ) SELECT region, feature_name, total_events, rolled_requests FROM ( SELECT region, feature_name, total_events, rolled_requests, row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank FROM regional_feature_totals ) ranked WHERE regional_rank <= 3 ORDER BY region, regional_rank; |
Die Form der Query zerlegen
Stufe 1: Tenant-Slice definieren
WHERE t.plan_tier = 'enterprise' AND t.billing_status = 'active' AND t.region IN ('eu-central', 'ap-southeast', 'us-east') |
Wenn Postgres diese erste Auswahl schon falsch einschätzt, basiert der gesamte restliche Plan auf der falschen Population.
Stufe 2: Auf berechtigte Features einschränken
JOIN tenant_entitlements te ON te.tenant_id = t.id ... AND te.entitlements IN (...) |
Die Entitlement-Tabelle ist hier nicht nur Join-Ziel, sondern zugleich ein korrelierter Feature-Filter.
Stufe 3: Aktuelle Nutzung binden
JOIN usage_rollups r ON r.tenant_id = t.id AND r.feature_name = te.entitlement ... AND r.rollup_day >= CURRENT_DATE - 30 |
Hier beginnt die Vervielfachung: Ein Tenant kann mehrere passende Entitlements und pro Feature mehrere Rollup-Tage haben.
Stufe 4: Auf Rohereignisse erweitern
JOIN analytics_events e ON e.tenant_id = t.id AND e.feature_name = r.feature_name ... AND e.event_type IN (...) |
Spätestens an dieser Stelle werden schlechte Row Estimates teuer. Nested Loops können billig aussehen, obwohl sie es nicht sind.
Stufe 5: Die Explosion wieder klein aggregieren
GROUP BY e.feature_name ORDER BY rolled_requests DESC |
GROUP BY t.region, e.feature_name |
Das Endergebnis ist klein, der Weg dahin aber überhaupt nicht. Genau das macht diese Query als Planner-Demo so wertvoll.
Stufe 6: Ranking in der Multi-Region-Query
row_number() OVER ( PARTITION BY region ORDER BY rolled_requests DESC, total_events DESC, feature_name ) AS regional_rank ... --- followed by WHERE regional_rank <= 3 |
Hier kommt zusätzlicher Sort- und Temp-I/O-Druck hinzu. Die Query ist also nicht nur Join- und Aggregationsproblem, sondern auch ein Ranking-Problem.
Extended Statistics als Rettung
Der erste Reflex bei solchen Problemen ist oft: mehr Multi-Column-, Partial- oder Expression-Indizes. Das kann helfen, aber für diesen Fall nutzen wir drei Statistikobjekte, um die eigentlichen Fehlannahmen des Planners zu adressieren.
- korrelierte Tenant-Spalten,
- Tenant-Entitlement-Kombinationen,
- Rollup-Kombinationen.
Wichtig: Nach dem Anlegen muss wieder ANALYZE laufen.
Typ: dependencies
Funktionale Abhängigkeitsstatistiken helfen PostgreSQL zu erkennen, dass manche Spalten andere so stark vorhersagen, dass Unabhängigkeitsannahmen falsch sind.
- Land sagt oft Währung voraus.
- Bundesstaat sagt oft Zeitzone voraus.
- Tenant-Segment sagt oft Entitlement-Familien voraus.
CREATE STATISTICS stats_tl_segment_dependencies (dependencies) ON id, plan_tier, region, billing_status FROM tenants; |
WHERE plan_tier = 'enterprise' AND region = 'eu-central' AND billing_status = 'active' |
Als Merksatz: dependencies korrigiert „diese Filter sind nicht unabhängig“.
Typ: mcv
MCV steht für „most common values“, bei Extended Statistics aber besser gedacht als „most common combinations“.
CREATE STATISTICS stats_tl_segment_mcv (mcv) ON plan_tier, region, billing_status FROM tenants; |
Damit lernt PostgreSQL zum Beispiel, dass bestimmte Kombinationen besonders häufig, besonders selten oder überhaupt unmöglich sind. Als Merksatz: mcv korrigiert „diese exakte Kombination verhält sich anders als der Durchschnitt“.
Typ: ndistinct
ndistinct sagt PostgreSQL, wie viele unterschiedliche Kombinationen mehrerer Spalten tatsächlich existieren, statt nur die Distinct-Werte je Spalte zu kennen.
CREATE STATISTICS stats_tel_entitlement_ndistinct (ndistinct) ON tenant_id, entitlement FROM tenant_entitlements; CREATE STATISTICS stats_url_feature_ndistinct (ndistinct) ON tenant_id, feature_name, rollup_day FROM usage_rollups; |
Als Merksatz: ndistinct korrigiert „diese Gruppen- oder Join-Kombinationen sind viel weniger zahlreich, als der Planner denkt“.
Was PostgreSQL speichert
Hier wird es besonders interessant. Man könnte all diese Probleme auch mit mehr Indizes angehen. Aber Indizes sind teuer zu pflegen und teuer im Speicherverbrauch.
Extended Statistics sind dagegen erstaunlich billig. Sie leben in pg_statistic_ext und pg_statistic_ext_data und bestehen im Kern aus Planner-Metadaten.
pg_statistic_extbeschreibt die Statistikobjekte.pg_statistic_ext_dataenthält die gesammelten Daten.
Im Benchmark lag der Gesamtbedarf aller Statistikobjekte bei etwa 2.059 Bytes:
- Tenant-Segment
mcv: ~1.049 Bytes - Tenant-Segment
dependencies: ~518 Bytes - Entitlement
ndistinct: ~220 Bytes - Rollup
ndistinct: ~272 Bytes
Das ist der Punkt: keine riesigen Schattenindizes, sondern kleine Metadaten, die den Planner weniger falsch machen.
Execution Plans reparieren
Ursprünglich wollte ich vor allem bessere Laufzeiten zeigen. Die wurden auch besser, aber nicht so spektakulär wie gehofft. Was sich jedoch massiv verbessert hat, waren die Schätzungen. Und genau das ist in vielen Fällen wichtiger.
| Scenario | Average Time | Worst Estimate | Additional Storage |
|---|---|---|---|
| Extended statistics | 2,857.896 ms | 48.27x | 2.0 KiB |
| Baseline + Composite Join-Key Indexes | 5,882.659 ms | 106.48x | 37.64 MiB |
| Baseline + Events (feature_name, event_type, tenant_id) | 4,781.551 ms | 108.7x | 31.45 MiB |
| Baseline + Partial Hot-Path Indexes | 4,765.351 ms | 106.22x | 30.20 MiB |
| Extended Statistics + Partial Hot-Path Indexes | 4,876.187 ms | 46.65x | 30.21 MiB |
Jede Query wurde fünfmal ausgeführt. Die vollständigen Pläne und Messwerte liegen im Repository.
Single-Region-Query
Das Basisschema nutzt einfache Single-Column-Indizes. Das vermeidet vollständig sequenzielle Ausführung, zwingt den Planner aber trotzdem dazu, Korrelationen über tenants, entitlements, rollups und events zu raten.
| Metric | Value |
|---|---|
| Average execution time | 14,168.174 ms |
| Average planning time | 4.134 ms |
| Execution samples | 31,093.955 ms, 29,065.788 ms, 3,564.811 ms, 3,570.114 ms, 3,546.200 ms |
| Planning samples | 5.058 ms, 3.952 ms, 8.969 ms, 1.899 ms, 0.793 ms |
| Join chain | Nested Loop:Inner -> Nested Loop:Inner -> Nested Loop:Inner |
| Scan nodes | Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Nested Loop: 178,389 estimated / 18,774,720 actual (105.25x) |
| Worst estimate path | Sort -> Aggregate -> Nested Loop |
Mit Extended Statistics sieht dasselbe Bild deutlich besser aus:
| Metric | Value |
|---|---|
| Average execution time | 2,857.896 ms |
| Average planning time | 3.025 ms |
| Execution samples | 4,318.854 ms, 2,612.261 ms, 2,396.848 ms, 2,467.702 ms, 2,493.816 ms |
| Planning samples | 6.719 ms, 2.067 ms, 2.128 ms, 2.243 ms, 1.970 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 7 estimated / 2 actual |
| Worst estimate | Hash: 12,966 estimated / 625,824 actual (48.27x) |
| Worst estimate path | Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash |
Der Planner verhielt sich danach nicht mehr so, als wären die Zwischenmengen winzig. Ein wichtiger Nebeneffekt: Die geschätzten Gesamtkosten gingen hoch. Das ist kein Rückschritt, sondern ein Zeichen dafür, dass PostgreSQL das Problem endlich realistischer einschätzt.
Multi-Region-Query
Bei der komplexeren Multi-Region-Variante waren die Laufzeitgewinne noch sichtbarer.
Baseline:
| Metric | Value |
|---|---|
| Average execution time | 24,933.705 ms |
| Average planning time | 3.648 ms |
| Execution samples | 84,815.859 ms, 12,696.190 ms, 11,819.487 ms, 8,482.936 ms, 6,854.054 ms |
| Planning samples | 6.125 ms, 5.681 ms, 2.067 ms, 2.181 ms, 2.187 ms |
| Join chain | Merge Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Sort: 53,580 estimated / 17,164,496 actual (320.35x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Merge Join -> Sort |
Mit Extended Statistics:
| Metric | Value |
|---|---|
| Average execution time | 7,289.319 ms |
| Average planning time | 2.875 ms |
| Execution samples | 7,503.924 ms, 8,261.715 ms, 7,433.035 ms, 8,181.565 ms, 5,066.357 ms |
| Planning samples | 9.244 ms, 0.932 ms, 1.039 ms, 1.801 ms, 1.359 ms |
| Join chain | Hash Join:Inner -> Nested Loop:Inner -> Merge Join:Inner |
| Scan nodes | Subquery Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Bitmap Heap Scan, Bitmap Index Scan, Index Scan |
| Top-level rows | 28 estimated / 5 actual |
| Worst estimate | Nested Loop: 68,387 estimated / 1,113,566 actual (16.28x) |
| Worst estimate path | Incremental Sort -> Subquery Scan -> WindowAgg -> Incremental Sort -> Aggregate -> Gather Merge -> Sort -> Aggregate -> Hash Join -> Hash -> Nested Loop |
Das ist keine kleine Verfeinerung mehr. Das ist PostgreSQL, das wieder in dieselbe Postleitzahl wie die Realität gezogen wird.
Wurden die Queries wirklich schneller?
Manchmal ja, manchmal nein. Genau deshalb lohnt sich ein nüchterner Blick auf dieses Thema.
Single-Region-Laufzeit
- Baseline im Schnitt: 14,168.174 ms
- Mit Extended Statistics: 2,857.896 ms
Das sieht spektakulär aus, wird aber stark von zwei sehr langsamen ersten Läufen im Baseline-Fall beeinflusst. Die vorsichtige Aussage ist also eher: bessere Planner-Kenntnis korrelierte hier mit besserem Steady-State-Verhalten.
Multi-Region-Laufzeit
- Nur Statistics: 7,289.319 ms
- Beste reine Index-Strategie: 6,886.473 ms
Das schwächt den Fall für CREATE STATISTICS nicht. Es präzisiert ihn nur: Statistiken verbessern Schätzungen, Indizes schaffen physische Zugriffspfade. Das sind verwandte, aber nicht identische Probleme.
Warum der Index-Vergleich wichtig ist
Ein spannendes Ergebnis war, dass indexlastige Varianten bei Kosten oder Laufzeit teilweise attraktiv wirkten, aber in der Schätzqualität deutlich schlechter blieben.
- Extended Statistics: etwa 2.0 KiB
- Index-lastige Alternativen: etwa 30.20 MiB bis 37.64 MiB

Genau das ist der unterschätzte Punkt: Extended Statistics machten PostgreSQL für ungefähr 2 KiB Metadaten deutlich weniger falsch, während indexbasierte Alternativen zig MiB extra brauchten und das eigentliche Planner-Problem oft gar nicht lösten.
Warum „beides zusammen“ nicht automatisch gewann
Natürlich habe ich auch die naheliegende Frage getestet: Werden Extended Statistics plus gute Indizes automatisch noch besser?
Überraschenderweise nicht immer.
Single-Region:
- Nur Statistics: 2,857.896 ms
- Statistics + Partial Hot-Path Indexes: 4,876.187 ms
Multi-Region:
- Nur Statistics: 7,289.319 ms
- Statistics + Partial Hot-Path Indexes: 8,950.207 ms
Mehr Indizes schaffen nicht nur Möglichkeiten. Sie verändern auch den Suchraum des Planners. „Nimm einfach beides“ ist also keine Naturregel, sondern ebenfalls ein Benchmark-Thema.
Praktische Einschränkungen
Ein paar Grenzen sollte man klar benennen:
- Extended Statistics gelten nur innerhalb einer Relation.
- PostgreSQL nutzt sie nicht direkt für Join-Selectivity über Tabellen hinweg.
- Nicht jeder Workload profitiert. Bei echten Unabhängigkeiten bringen sie wenig.
- Sie ersetzen keine guten Queries, sinnvollen Indizes, Partitionierung, vernünftige Speicherwerte oder ein schnelles Storage-Backend.
Sie sind ein Planner-Informationsfeature, kein universeller Performance-Zauber.
Wann man zu CREATE STATISTICS greifen sollte
Die praktische Regel ist simpel: Wenn ein Plan falsch aussieht und das Problem mit mehreren gemeinsam gefilterten oder gruppierten Spalten zusammenhängt, denke an Extended Statistics, bevor du reflexhaft den nächsten Index anlegst.
Gute Kandidaten sind:
- stark korrelierte Filterspalten,
- segmentgetriebene Dimensionseigenschaften,
- Group-by-Workloads mit offensichtlich falscher Kardinalität,
- Multi-Column-Fanout-Probleme,
- schiefe Kombinationen häufiger Werte,
- Pläne, bei denen eine schlechte Einzelrelation-Schätzung den Rest vergiftet.
Schlechtere Kandidaten sind:
- Queries mit fehlendem physischen Zugriffspfad,
- Workloads, die klar I/O-limitiert sind,
- Fälle, in denen die Spalten tatsächlich nahe an Unabhängigkeit liegen.
Nutze EXPLAIN (ANALYZE, VERBOSE, BUFFERS). Wenn Estimated und Actual Rows massiv auseinanderlaufen, können Extended Statistics genau richtig sein.
Wahrheit ist besser als Tricks
Das Schönste an CREATE STATISTICS ist, dass es den Planner mit mehr Wahrheit versorgt, statt einfach immer neue Strukturen auf die Daten zu stapeln.
Die Benchmarks sagen nicht „Extended Statistics gewinnen immer“. Sie sagen etwas Nützlicheres:
- Sie machten PostgreSQL deutlich weniger falsch.
- Sie änderten die Planform sinnvoll.
- Sie kosten fast keinen Speicher.
- Sie adressieren das Planner-Problem oft direkter als Dutzende MiB zusätzlicher Indizes.
Benchmark, Queries und Ergebnisse liegen auf GitHub. In unserer Vela Postgres Sandbox kannst du die Queries auch selbst testen.
Und wenn du je auf einen Plan geschaut und gedacht hast: „Es gibt keine Welt, in der dieser Join dreimal in einem Trenchcoat verschachtelt sein sollte“, dann könnten Extended Statistics genau das Feature sein, das du gesucht hast.