
We were made to believe that using a database is hard and cumbersome. But just as LLMs and GenAI are changing how people build applications, Vela changes how people interact with databases. Not by inventing a new database engine or redefining SQL, but by fixing something far more fundamental: the user experience around Postgres.
PostgreSQL itself is incredibly capable. It's rock-solid and production-proven. It's highly extensible. And it is the fastest-growing database. Powerful enough to run everything from small internal tools to large production systems with petabytes of data.
What has not changed much, though, is how users actually use databases day-to-day. Provisioning is slow, even with Kubernetes-based setups, and cloning is painful, if not impossible. Testing database changes often feels risky, and database access is tightly controlled. Not because the technology demands it, but because existing workflows do.
Vela addresses this gap head-on and transforms the role of the database from being a guarded infrastructure component to an accessible, on-demand building block for engineers and non-engineers.
For engineers, it enables fast, realistic testing workflows without waiting on ops or a time slot on a shared staging system. For non-engineers, it enables safe, direct interaction with real data for analytics, reporting, and internal tooling. The result is that Postgres becomes accessible to groups that were previously blocked by process, tooling, or organizational boundaries.
Vela doesn't change PostgreSQL. It changes who can use it, how quickly they can use it, and how safe that use is.
What Vela Is Not
Let's be blunt and explicit, Vela is not YET another database engine. It is built on vanilla Postgres. Just to make sure that we're on the same page. With new databases popping up left and right, I totally understand that some folks might get confused.
It doesn't introduce a new storage format, a new execution engine, nor some proprietary query planner. It's not a new query language and doesn't add additional abstraction layers you have to learn before writing SQL.
Last but not least, Vela is not a PostgreSQL fork. It uses the default, upstream Postgres source code (version 18.1 as of writing).
This matters because forks almost always come with trade-offs: diverging behavior, delayed upgrades, incompatible extensions, or long-term vendor lock-in. Vela deliberately avoids that path. If you know PostgreSQL today, you already know how to use Vela from a database perspective.
Same Postgres, Different Experience
Under the hood, Vela runs vanilla PostgreSQL. The same query engine. The same planner. The same extensions. The same SQL semantics.
Your existing tools continue to work. ORMs do not need adapters. Migration tools behave the same way. Dashboards, BI tools, and scripts connect as they always have. From the client's point of view, it is just Postgres.
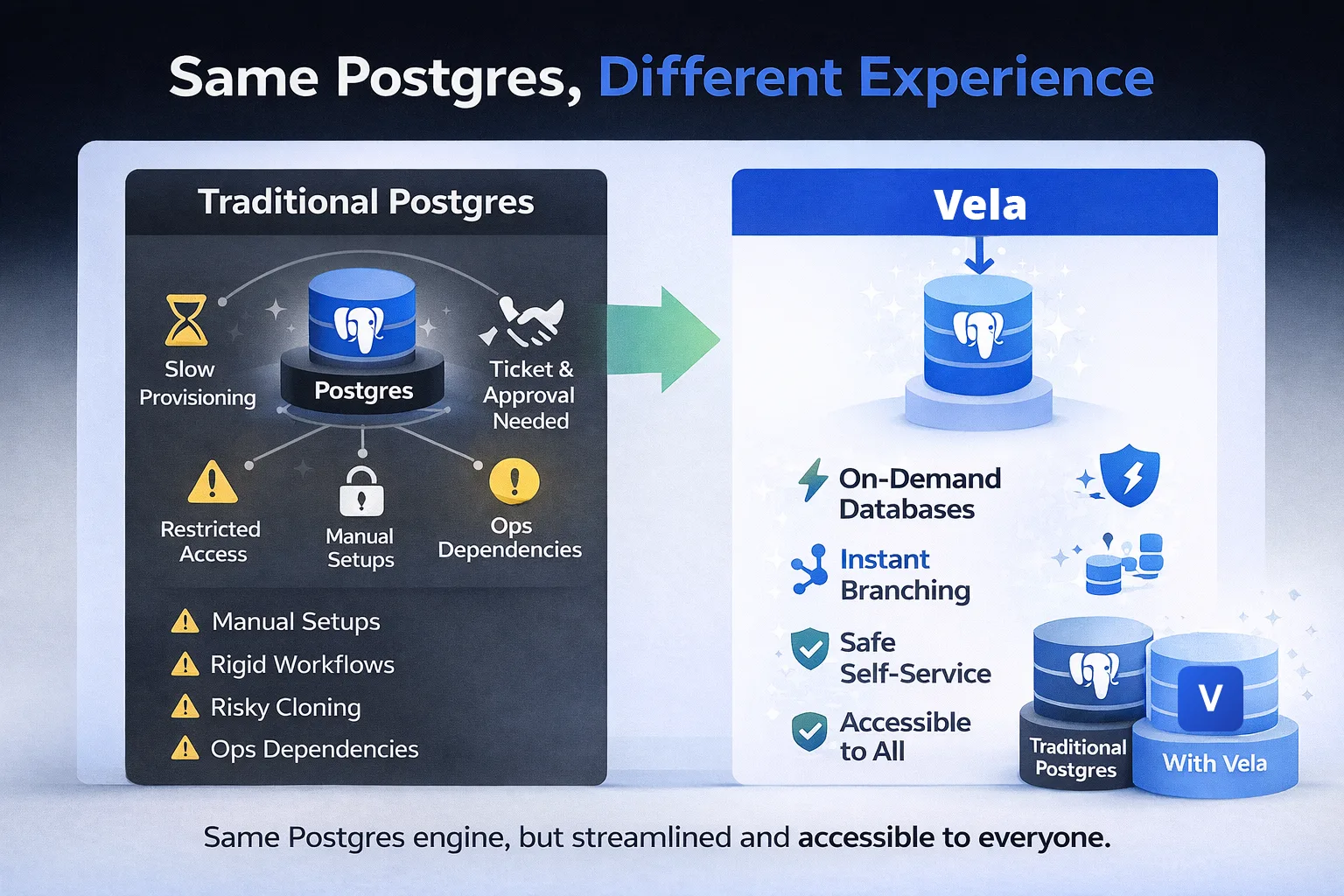
The difference lies entirely in the experience around it. Vela promises the "Same Postgres, Different Experience." You do not get a new database; you get a new way to interact with your databases.
This also means there is no incentive to hide improvements behind proprietary features. Any PostgreSQL-level changes that we might introduce are intended to be upstreamed. The goal is to improve the ecosystem, not fragment it.
Self-Hosting of PostgreSQL Is Solved; The User Experience Is Not
From an infrastructure perspective, PostgreSQL is largely a solved problem. Kubernetes-native operators such as CloudNativePG and StackGres manage the lifecycle reliably. For on-prem additional solutions, such as Autobase, make bare-metal or VM-based deployments easy to set up.
Yet, despite all this progress, day-to-day database workflows still feel stuck in the last millennium.
Creating a new database often requires a ticket and a wait while someone finds time to set it up. Cloning production data requires coordination, approvals, and long-running jobs. Testing schema changes means negotiating access to a shared staging environment that everyone is afraid to touch. Even simple experiments that cannot just run in a local Docker container require a DBA or platform engineer to be in the loop.
The irony: the hardest part is no longer running PostgreSQL. It is interacting with the database efficiently and safely.
Databases Are Treated As Infrastructure; Not As A Commodity
In many organizations, databases are treated as a critical infrastructure item, a scarce asset, rather than everyday tools.
Databases are requested through tickets or require Terraform plans executed by the ops teams. Non-technical teams cannot create or modify schemas without engineering support, even though AI-driven tooling is here to address this. Cloning a database usually means slow dumps and restores, or worse, shared schemas that introduce accidental coupling.
Furthermore, access to realistic data is restricted or simply unavailable. Anonymization pipelines run nightly as batch jobs, and analysts must work with stale snapshots, eliminating the ability to respond in real time.
Developers are told "please don't touch prod" even though they only need to reproduce an issue, analyze a bug, or identify additional edge cases. But apart from "prod," there is no option to gather this information.
With database requests slow and databases scarce resources, people avoid experimentation because the cleanup cost is high. The teams' efficiency decreases, not because PostgreSQL cannot handle the workload, but because the surrounding workflows cannot.
Databases As A Self-Service Product
Vela flips the mental model by treating databases as a self-service resource rather than an infrastructure artifact.
Instead of requesting a database and waiting, users create one themselves. In seconds rather than minutes. Instead of coordinating a clone, they branch it out. Instead of carefully cleaning up old environments, they simply delete them in the UI or API.
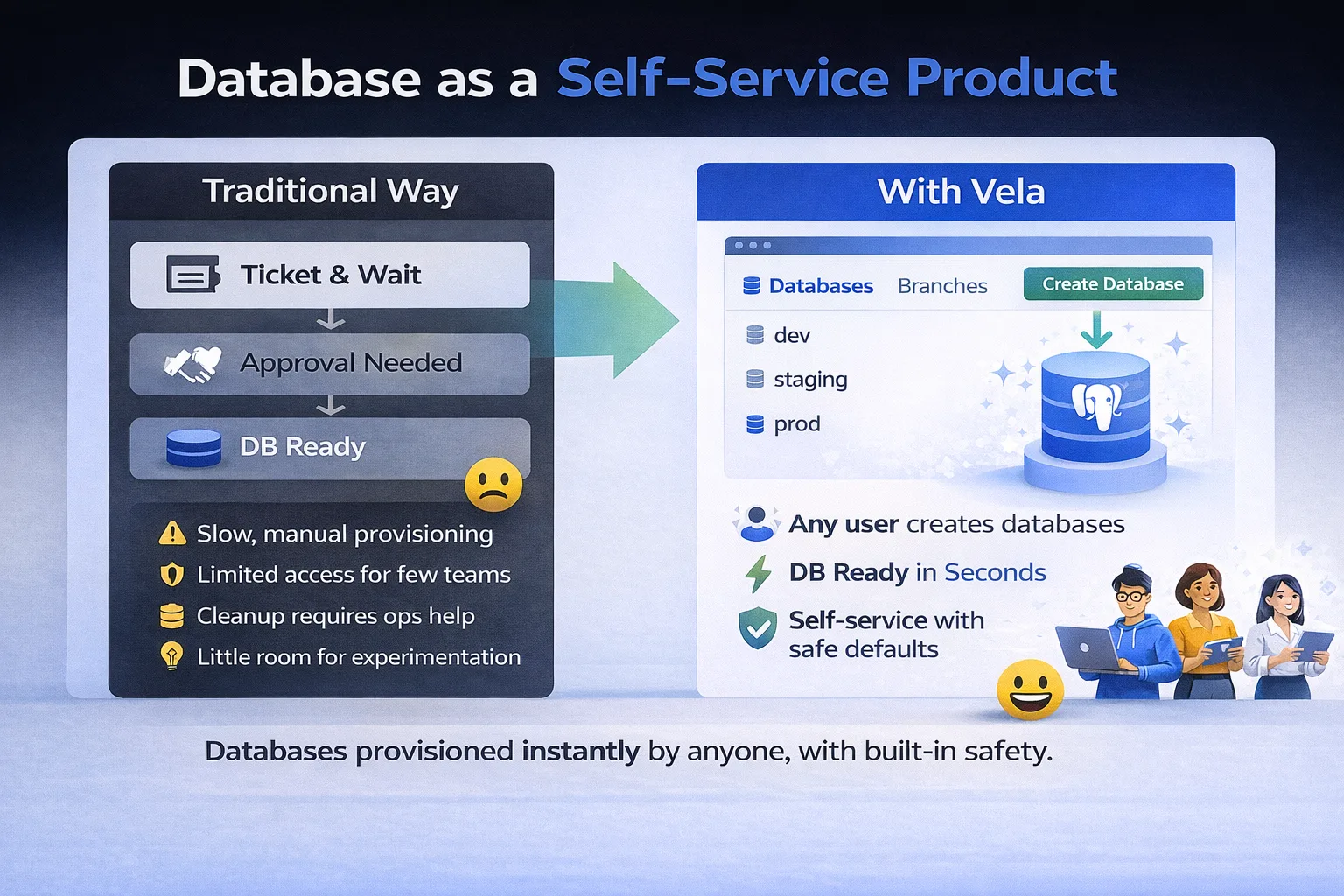
For developers, this means testing a migration no longer requires negotiating access to a shared staging system. You branch the database, apply the migration, run your tests, and discard the branch when you are done.
For analysts, it means creating a copy of a production dataset for a long-running report without impacting live workloads. And it means enabling near-real-time responses to sudden events.
For non-engineers, it means being able to explore data or build small internal tools without waiting for engineering availability. No matter if those people are in sales, marketing, or finance.
Access becomes fast, reversible, and safe by default. The user interface lowers the barrier to entry without removing guardrails, which is what makes self-service viable at scale.
Branches Are Real Databases, Not Illusions
One of the most important design choices in Vela is that branches are real PostgreSQL databases. In Vela, everything is a branch. Like in Git. You start with your "main" database branch and can continue creating further branches out of it.
That means that a branch is not just another schema. It doesn't even share a PostgreSQL process with other branches. It does not rely on tricks to simulate isolation. Each branch runs as a fully isolated Postgres instance within its own micro virtual machine.
The practical consequence, no cross-branch lock contention. Extensions cannot conflict with each other, and one branch cannot starve another of resources or accidentally affect its behavior. Vela explicitly limits resources on multiple levels (organizations, projects, branches) to ensure maximum multi-tenancy safety.
From the user's perspective, this means that branching feels trustworthy. You are not working in a fragile approximation of a database. You are working in a real one.
From the platform team's perspective, it provides security and predictability, while enabling careful resource planning without flying blind and hoping for the best.
Why This Matters For Real Workflows
These design choices immediately show their value in everyday workflows.
Feature testing no longer depends on minimal unit tests or shared staging environments that everyone is afraid to touch. Each feature branch can have its own database branch, with realistic data and full isolation. QA teams can validate behavior without coordinating schedules or worrying about interference.
Developers can experiment freely. Breaking something is no longer a crisis, because cleanup is trivial. You delete the branch, and it is gone. Additionally, devs can identify additional edge cases before handing a feature over to QA, reducing iterations and improving development efficiency.
Non-engineering teams benefit just as much. Sales teams can build lightweight tools on top of real data. Marketing can explore datasets without waiting for exports. Analysts can run heavy queries without impacting production.
Perhaps most importantly, cleanup becomes part of the workflow. Instead of accumulating half-abandoned databases and schemas, teams delete what they no longer need.
Storage Is The Hidden Enabler
None of this would be practical without the right storage foundation. This is where simplyblock plays its strength.
Vela uses simplyblock as its underlying distributed storage engine. This enables fast, copy-on-write semantics at the storage layer, which is what makes instant branching possible and powers many of the features of the Vela Postgres platform.
When you create a branch, the data is not copied eagerly. It is shared safely until changes are made. Only then is the changed data copied and stored as independent data fragments. This keeps both time and costs under control, even as the number of databases grows.
Just as importantly, performance remains predictable. Running many parallel databases does not turn into a noisy-neighbor problem. This is essential, especially when self-service is no longer limited to a small group of experts.
Why Does it Matter to Your Organization
Organizations are increasingly aware that database babysitting is expensive and reaction speed to data is important.
Highly skilled engineers spend time on tasks that do not directly add value to the business, such as waiting for databases or a fresh data copy.
At the same time, more roles depend on direct access to data. Analysts, product managers, and business teams want to move faster and experiment more. Blocking them with rigid processes is no longer sustainable.
Platforms that succeed in this environment remove friction without removing control. They make the safe path the easy path. Vela fits squarely into that shift.
Vela Reimagines The Postgres Experience, Not Postgres Itself
Vela does not try to make PostgreSQL better by changing it. Postgres is already good enough. It remains what it has always been: rock-solid, boring, trusted, and proven.
What changes is everything around it. The experience becomes faster. Access becomes safer. More people can work directly with databases without increasing risk. Vela increases your efficiency and output. As a result, other teams and the whole company move faster.
With Vela, existing tools, drivers, extensions, and SQL behavior of Postgres remains untouched. The database stays boring, as it should. However, the way users interact with Postgres finally aligns with how modern teams should work.
If you're interested to give it a spin, you can use our Vela Sandbox. It's free and provides a window into the future of consuming databases, on-premise or in your private cloud.