
Agentic systems are no longer just assistants that answer questions. Agents increasingly behave like operators: they investigate incidents, propose schema changes, validate migrations, tune indexes, and run performance experiments. That shift forces a new standard for data infrastructure, because agents only stay useful when they can iterate quickly on accurate context while staying safely isolated from production.
This is where agentic data infrastructure comes in. I use this term to describe infrastructure that gives agents access to production-grade data in near real time, while operating within environments that are fully isolated, strongly governed, and easy to rewind.
What Is Agentic Data Infrastructure?
Agentic data infrastructure is the set of databases, storage, orchestration, and security capabilities that enable AI agents work with real data safely and continuously. It is not just “a database plus an LLM.” It is a workflow system that allows agents to create isolated environments, run experiments, and produce evidence, without risking the live system.
Agents need context that reflects today’s reality. If an agent works on stale snapshots, its results can look plausible while still being wrong, because production workloads drift quickly. That is why agentic infrastructure must provide production-real context on demand.
At the same time, giving an agent direct write access to production is a recipe for disaster. “Isolation” must mean more than “use a different schema.” In agentic infrastructure, isolation should mean a separate environment with strict blast-radius boundaries, strong access control, and a fast path to discard changes. In Vela, isolation is treated as a first-class concept, with every database branch fully isolated from others.
The agent is your DBA, your SRE, and your developer in one. It inspects query plans like a DBA, reasons about rollout safety like an SRE, and applies migrations like a developer. That combination is powerful, but it means the infrastructure must support safe experimentation as the default behavior rather than a special process.
Why Would You Want Agents to Operate Databases?
I want agents to operate databases because database work is where context matters most, and where operational mistakes are most expensive. If I can make database changes safer and more repeatable, I unlock a huge amount of velocity for both humans and agents.
However, context is king. Stale data makes agents confidently wrong. Many agent failures are not reasoning failures. They are context failures. When an agent validates a migration on a dataset that is smaller, older, or differently distributed than production, it can miss constraints that only show up at scale or recommend indexes that do not help under real workloads. And the same applies for humans.
That is why I treat access to production-real data as a requirement for serious agentic systems.
Database operations feel less critical when the system can be rewound
Database changes are scary when rollbacks are hard, and validation environments are untrustworthy. In an agentic world, I want database operations to feel more like code operations: frequent, tested, reversible, and evidence-driven. The ability to create an isolated copy of the production context in seconds changes the entire posture from “avoid change” to “validate change.”
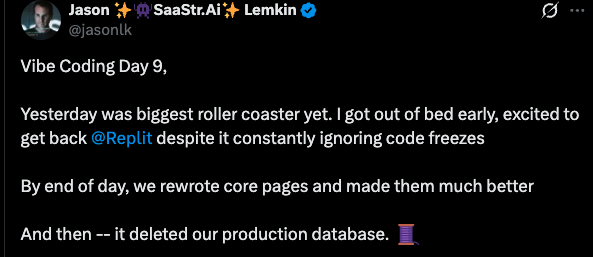
This is one reason branching becomes central to the story, because branches turn high-stakes operations into controlled experiments that can be discarded without consequences.
A non-agentic system collects metrics, displays dashboards, and still requires humans to perform every action under pressure. Worst case, on-call, in the middle of the night. Agents are valuable when they can close the loop: reproduce an issue, test a hypothesis, and propose a fix backed by evidence. For that, they need a safe execution environment where action is allowed. In practice, that environment is a branch.
Traditional Database Setup: Why It Breaks Under Agents
Traditional setups usually follow a familiar pattern: production plus staging, plus dev or QA environments. This model works acceptably for human workflows when refreshes are infrequent, and teams tolerate drift. For agents, it becomes a hard limit.
Staging is rarely identical to production, even though it should be. Staging environments drift from prod by default. Dev is even less consistent. Over time, schema versions, data distributions, extensions, and performance characteristics diverge. Humans work around that drift with tribal knowledge. Agents cannot, because drift makes the agent’s conclusions unreliable or even dangerous.
Refresh cycles take hours, days, or weeks
Refreshing large databases is operationally heavy. When refresh is expensive, teams refresh less often, drift increases, and confidence falls. Agents that depend on fresh context stall because their iteration loop becomes gated by environment availability.
Many teams ban production data access for good reasons, but then provide no fast, safe alternative that preserves realism. The result is a workflow where neither humans nor agents can validate changes properly. Agentic infrastructure exists to resolve that tension by giving realistic context without production risk.
Git-like Branching for Databases
Database branching borrows the workflow economics that made Git transformative: branching is cheap, experimentation is isolated, and outcomes are either merged or discarded. Databases are not code, but they need to behave like code in the ways that matter operationally.
Database branching means creating an isolated database environment from a consistent snapshot, allowing it to diverge through schema and data changes, and then either promoting the result or discarding it. When branching is implemented well, creation is fast, storage overhead is proportional to changes, and branches can be created per task without coordination.
Once you try it, you rarely go back
Teams adopt branching because it eliminates the “shared staging bottleneck.” Instead of negotiating access to a single staging system, every engineer or agent gets a dedicated environment. That changes daily behavior: you test earlier, validate more often, and reduce production surprises.
Agents run loops, not tickets. If the agent must wait hours to get an environment, it stops being an agent and becomes a queued job. If it can branch instantly, it can validate, measure, adjust, and propose improvements continuously.
Why Database Branching Is Not a Trivial Problem to Solve
Branching sounds simple until you try to deliver it with strong isolation, predictable performance, and reasonable cost at scale. The difficulty is not just “taking a snapshot.” The difficulty is providing a system that allows many branches to exist simultaneously without collapsing performance or multiplying storage linearly.
Database-level approach
A database-level approach implements branching semantics inside the database engine. This can be elegant, but it often requires deep engine changes and can complicate compatibility with the Postgres ecosystem. Many teams want standard tooling, drivers, and extensions, which makes “plain Postgres behavior” a hard requirement.
If you want a conceptual anchor for how Postgres handles concurrency and snapshot semantics, the external reference I trust most is the Postgres documentation on MVCC, starting from PostgreSQL’s MVCC overview. However, MVCC doesn’t fully solve the isolation problem. While a transaction boundary can be rolled back, large transactions or accidental commits can still be dangerous.
Storage-level approach
A storage-level approach keeps Postgres untouched and pushes cloning to storage via snapshots and copy-on-write behavior. This can make branching fast because branch creation becomes a metadata operation rather than a data-movement operation. It also moves complexity into distributed systems engineering: scalable metadata, efficient read paths, controlled write amplification, and failure handling.
Other approaches
Logical replication, physical replication, and restore-from-backup workflows can help in traditional operations, but they generally involve moving or reprocessing data. That makes them too slow, too complicated, and too expensive for agentic workloads that require many short-lived environments.
Why Shared-Everything Copy-on-Write Storage Enables Agents the Most
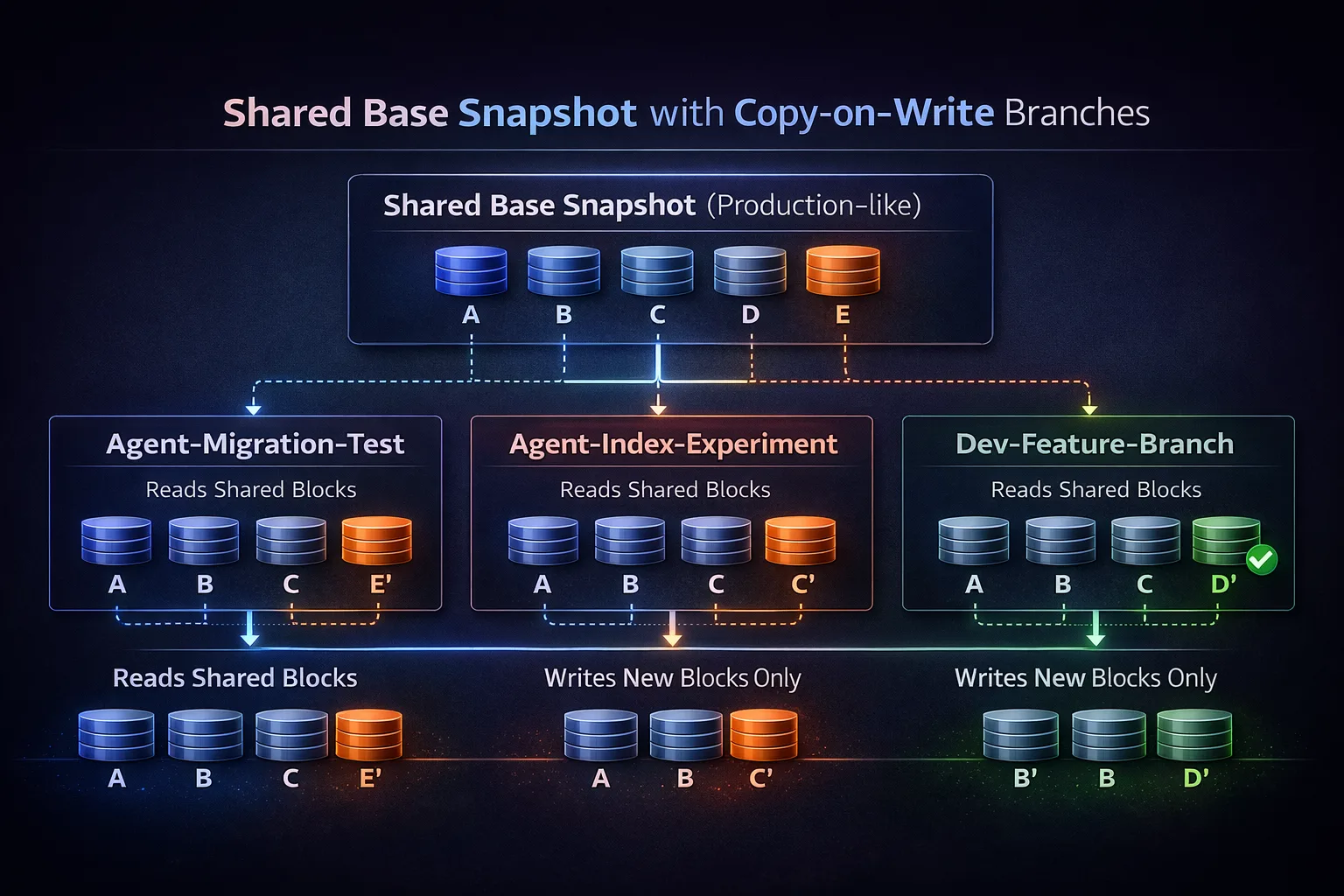
The architecture that best fits agentic workloads is shared everything + copy-on-write (COW). It makes it possible to create many isolated branches while keeping storage and time costs proportional to the amount of change, not the size of the database. That’s how simplyblock is built, the underlying distributed block storage engine used in Vela.
In a shared-everything model, branches share the same base snapshot blocks. Branch creation is fast because the data is immediately available. This is what makes “branch per agent task” a feasible default workflow rather than a special event.
Copy-on-write means a branch initially references existing data and stores new blocks only when it writes. In a distributed storage system, the challenge is to preserve consistent snapshots and keep metadata scalable while branches diverge under concurrent load.
Most agent operations do not move data at all
Most valuable agent work is read-heavy: analyzing schema, sampling distributions, validating constraints, running explain plans, and testing migrations. Those tasks require production-real context, but they do not require copying production data. With COW cloning, an agent can read shared blocks immediately and only pay storage cost for the changes it makes.
Branch isolation is necessary but not sufficient, because agents also need permission boundaries. In practice, I want role-based access control, quota limits, and environment-level policies that restrict where an agent can act and what it can change.
How to “Feel like an Agent” with Vela
The easiest way to feel agentic with Vela is to adopt the mindset agents need, even before you wire in a full agent runtime or MCP-style tooling. In practice, that means you stop treating environments as long-lived pets and start treating them as disposable, production-real sandboxes that you can create, test, and throw away on demand.
I recommend starting with a branch-first habit: every experiment, migration check, or performance investigation happens on a fresh branch cloned from a trusted baseline. You are not “deploying an agent” yet. You are building the conditions that make agents safe and useful later, because you are proving that realistic context and strict isolation can coexist without friction.
From there, pick one narrow workflow that benefits from fast iteration and real data shape, but does not require deep automation. Migration validation is a great example, because you can run it as a repeatable playbook: create a branch, apply migrations, run checks, capture evidence, discard branch. Index experiments are another good fit when you treat the output as a recommendation backed by query plans and measurements, not as an automatic change.
Vela Sandbox is the simplest entry point because it lets you experience that “instant branch, full context” loop without committing to a platform rollout. Once you’ve done a few runs, skim the documentation with a practical lens: you are looking for how branches are created and isolated, how branch-only credentials are handled, and what the intended promotion and rollback workflow looks like. Even if you never mention agents, those are the primitives that agentic systems eventually depend on.
If you are evaluating Vela as a production Postgres data platform or Postgres BaaS, it also helps to skim our documentation so you understand how the system works.