Vela Storage powers the next generation of Postgres: instant, elastic, and durable by design. Built on simplyblock's distributed NVMe storage substrate, it enables copy-on-write database cloning, real-time elasticity, and synchronous replication without compromising performance. For developers, that means instant Postgres branches, production-grade durability, and predictable cost. For platform teams, it means a Postgres Data Platform that runs at NVMe speed with cloud-scale reliability. On your own infrastructure.
The Storage Gap in Modern Data Platforms
Modern software evolves faster than its storage does. AI agents and automated pipelines now generate and test code continuously. Platform teams host thousands of short-lived environments for CI, QA, and analytics. Yet the storage stack underneath these systems still behaves like a fixed appliance—slow to scale, expensive to replicate, and inefficient to clone.
Postgres, the backbone of most modern applications, has adapted to nearly every use case: transactional, analytical, and now vector-based AI workloads. But Postgres itself can only move as fast as the storage beneath it. Traditional "elastic" cloud storage is not truly elastic. Volumes must be resized manually. Snapshots hydrate lazily. Scaling is bound by cooldown timers and IOPS limits. Teams over-provision for safety and end up paying 5–6x what they should.
Vela was created to solve that. It combines a Postgres Data Platform with a distributed NVMe-backed storage engine from simplyblock purpose-built for workloads that need to fork, scale, and recover instantly. It's Postgres, redesigned for the age of AI and automation.
Why Elastic Storage Isn't Truly Elastic
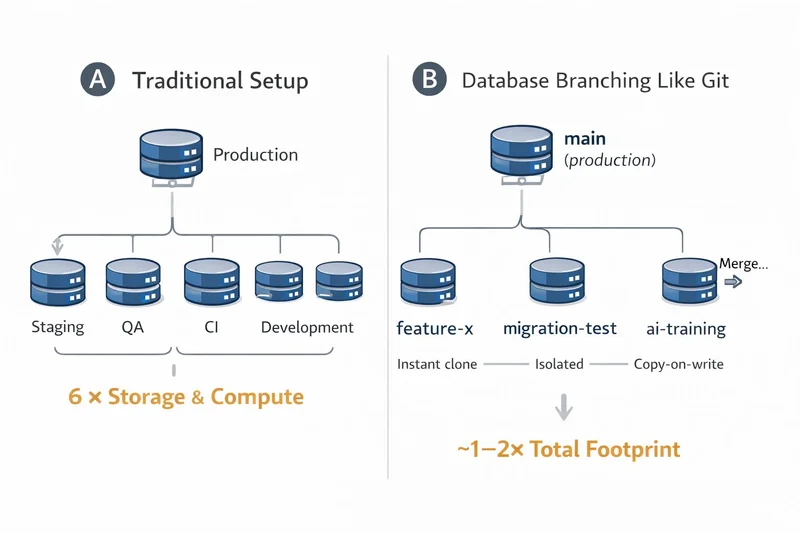
Elasticity has become the most misunderstood promise in cloud infrastructure. Services like Amazon EBS or GCP Persistent Disks call themselves "elastic," but elasticity there is procedural, not dynamic. Volumes can grow, but only in fixed increments and on long cooldowns. They can't shrink. Forking a volume into a new environment triggers a full copy, wasting both time and money.
For example, a single production instance with 16 vCPUs, 192 GiB RAM, and 15 TB storage multiplied across five staging and testing environments equals nearly six times the resource footprint. That's 6x cost and CO₂ for the same dataset. Vela eliminates that duplication. Thin clones reuse production data at the block level, so you pay primarily for deltas—the data that changes, not for entire database copies. Elasticity, in Vela's model, is continuous, not procedural.
Why We Built Our Own Storage
We could have reimplemented PostgreSQL's storage engine like Aurora or Neon, but that approach couples the database to a proprietary backend and breaks compatibility with upstream Postgres. Instead, we built elasticity below the database layer, where it belongs. With developer velocity in mind, we designed a system that works on your own infrastructure through our BYOC model, ensuring you maintain control.
With Vela's storage layer we wanted to make sure developers get an amazing backend experience:
- A database that could branch like code
- Clones that appeared instantly
- Volumes that can grow and shrink automatically
- Consistent latency under load, without provisioned IOPS billing
Simplyblock provides a distributed, NVMe-backed block layer that's transparent to Postgres. It offers true copy-on-write semantics, synchronous replication, and linear scalability, all exposed through a standard Linux block device. That choice gave Vela a foundation where Postgres itself remains untouched yet gains instant cloning, elastic scaling, and enterprise durability.
Architecture: The Three Layers of Vela Storage
Vela Storage is best understood as a stack, not a single component. The foundation is simplyblock's software-defined storage, which exposes high-performance block volumes using NVMe/TCP and enterprise storage services like snapshots and clones. Above that, a virtualization + autoscaling layer provisions and places VMs. Finally, Vela is deployed into those VMs, where it runs Postgres and the developer workflow layer (branching, cloning, RBAC, platform services).
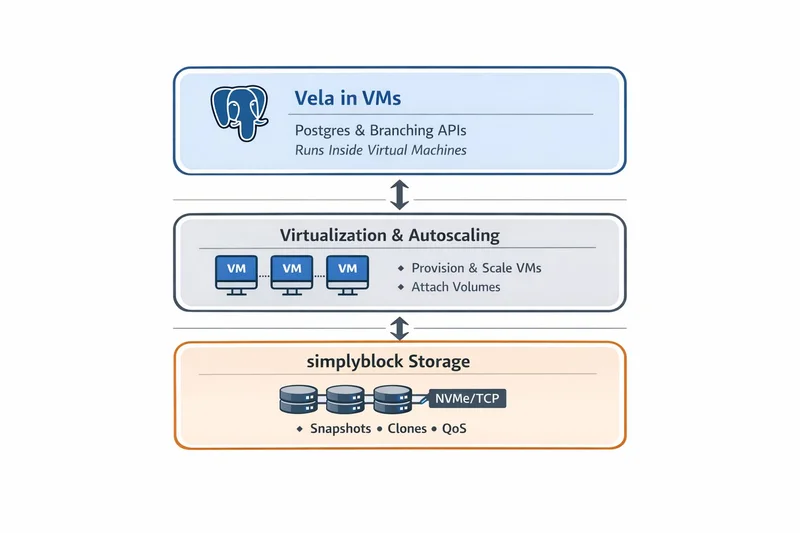
1. Simplyblock Storage Substrate (Data Plane + Control Plane)
At the bottom, simplyblock aggregates NVMe devices into a distributed storage system and presents them as block volumes to consumers. It is designed as software-defined storage with cloud-native integration, and it uses NVMe-over-TCP to provide ultra-low-latency remote block access. Crucially for Vela, simplyblock also provides storage services that map directly to "database workflow" primitives. Features like snapshots, clones, multi-tenancy, and QoS exist at the storage layer, so higher layers can create fast copies without moving full datasets.
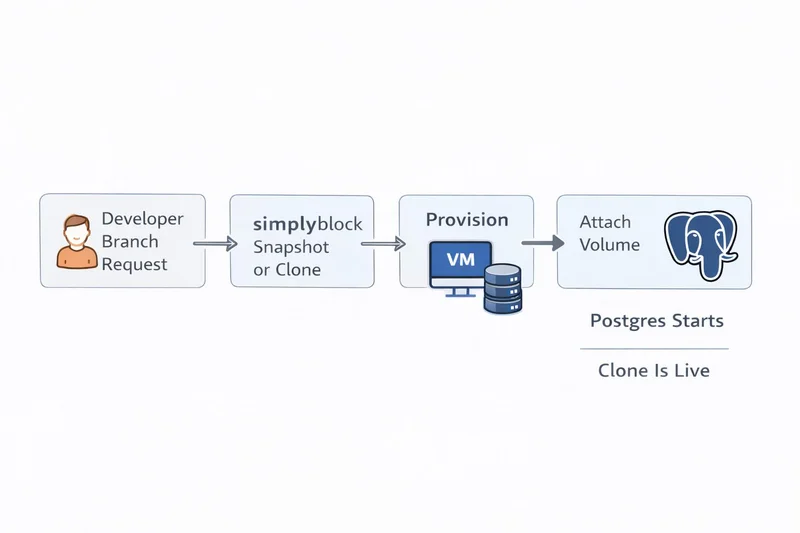
Create your Postgres backend in 90 seconds.
Launch a production-ready Postgres stack with branching and instant clones.
Start in 90 seconds2. Virtualization + Autoscaling Layer (VM Lifecycle and Placement)
On top of the storage substrate, the virtualization layer is responsible for provisioning VMs, placing them on available compute, attaching simplyblock-backed volumes, and scaling VM fleets up or down based on demand. This layer is where "platform elasticity" actually happens operationally. The storage stays durable and shared underneath, while compute environments come and go.
3. Vela inside VMs (Postgres + Branching Workflows + Platform UX)
Inside each VM, Vela runs plain PostgreSQL plus the platform services that turn it into a Postgres BaaS and Postgres Data Platform. This is where developers experience instant database branches and clones, Git-like workflows, and platform features like RBAC and guardrails.
Technical Capabilities and Measured Outcomes
Instant Forking and Snapshots
Forking or snapshotting a Postgres instance in Vela is a metadata-only operation. Even for large databases (100 GB–1 TB), these operations complete in under 600 ms at the storage layer. This enables entirely new workflows: ephemeral feature branches, production-grade testing, or per-agent sandboxes all running on real data, without the overhead of copying terabytes.
Predictable High Performance
Vela achieves performance parity with local NVMe and surpasses traditional cloud volumes by orders of magnitude. Some of the Postgres benchmark numbers that Vela has achieved:
- Read Throughput: 290,000 TPS
- Write Throughput: 23,000 TPS
- p99 Latency: ~3 ms
- IOPS: 1M+ sustained
Unlike AWS EBS or io2 volumes, there are no IOPS throttling limits or per-IOPS charges. Performance scales linearly as nodes are added.
Elastic Resource Utilization
Each volume automatically expands or contracts with actual data usage. When a forked environment is deleted, unused blocks are reclaimed. This continuous elasticity eliminates the "optimizing" delays and idle over-allocation common to cloud volumes.
Durability and High Availability
All writes replicate synchronously across multiple NVMe block servers, ensuring zero data loss under node failure. The system maintains 99.99% availability, with self-healing replication and no manual intervention required.
Compatibility and Transparency
Because Vela operates at the block layer, PostgreSQL remains fully unmodified. You can upgrade Postgres, run any extension, and use standard backup tools. Vela simply replaces the slow part of your infrastructure, not your workflow.
Economic and Environmental Efficiency
Vela's elasticity translates directly to resource efficiency. Instead of maintaining multiple database copies across production, staging, dev, and test environments, most teams operate at roughly 2x their production footprint to serve technically infinite number of prod database copies and forks. Infrastructure costs drop sharply, and platform engineering effort decreases by up to 85%, as Vela manages storage, backups, replication, and orchestration automatically.
This efficiency isn't just financial—it's sustainable. A single deployment can reduce monthly CO₂ emissions by more than 1,300 kg, equivalent to 750 trees planted per month. Elastic infrastructure is inherently green.
Built for Developers and Platform Engineers Alike
For developers, Vela brings a Git-like experience to databases: branch, test, merge, and rollback with confidence. For platform engineers, it eliminates the complexity of manually provisioning and scaling storage. Integrating with Kubernetes and CI/CD systems, Vela delivers:
- Instant branch creation for every PR
- Massive cost savings on dev and QA environments
- Improved reliability from immutable snapshots
- Compliance-friendly data separation
The Bottom Line
Vela Storage is the backbone of Vela's Postgres Data Platform. It turns Postgres into an elastic, cloneable, and durable backend for AI, SaaS, and modern developer workflows—without vendor lock-in.