
Underrated Postgres: Create (Extended) Statistics
Extended statistics help PostgreSQL fix bad row estimates and improve query planning with almost no storage overhead. This article shows where CREATE STATISTICS outperforms adding more indexes.
Give every team a production-ready Postgres database in seconds — on your infrastructure, in your cloud, under your control.
Instant isolated Postgres environments for every feature, migration test, and environment. No manual provisioning.
Learn about database branching →Deploy on OpenShift, Rancher, or any Kubernetes cluster. Standard Postgres, standard interfaces, no proprietary lock-in.
Your data stays in your VPC, data center, or on-premises environment. Full control, no external dependencies.
Manage databases across teams, monitor performance, and enforce access controls from a single platform.
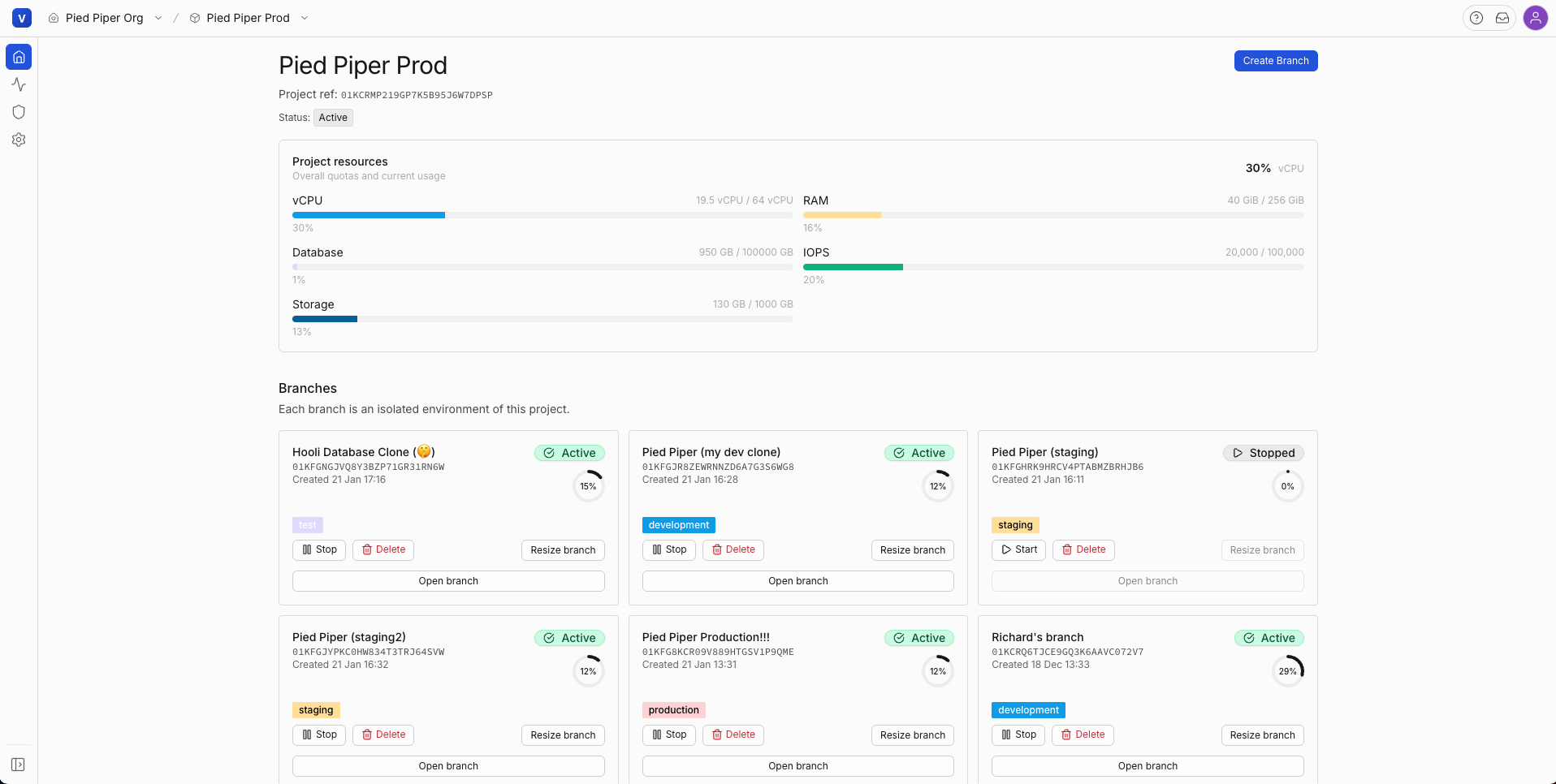
Monitor usage, branches, and operations from one dashboard.
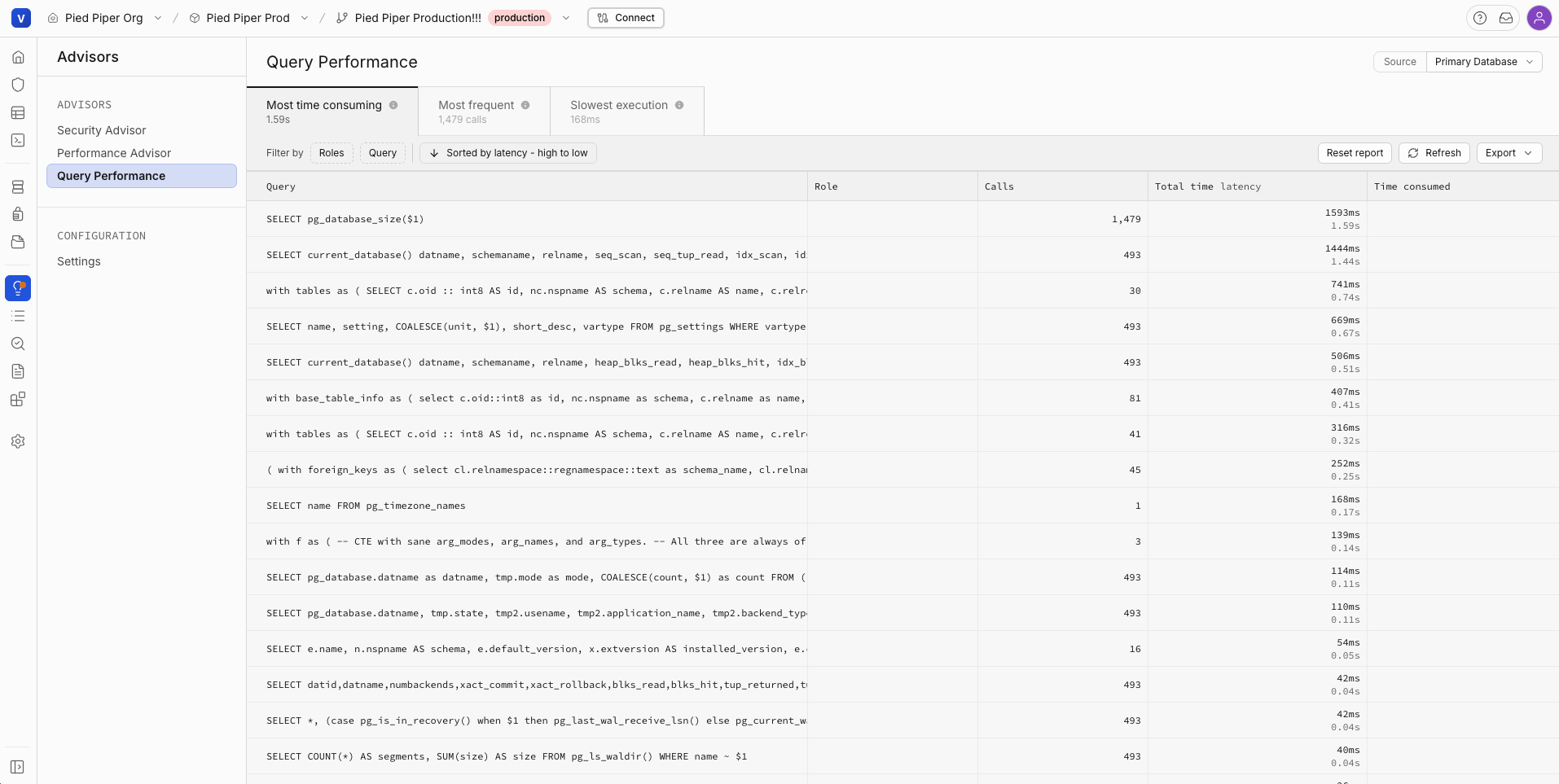
Track bottlenecks and optimize queries with detailed metrics.
Spin up a production-ready Postgres instance from the sandbox or directly in your Kubernetes cluster. No infrastructure setup required.
Integrate with your OpenShift, Kubernetes, or private cloud environment using standard APIs. Full portability, no proprietary layer.
Add branching, RBAC, audit trails, and multi-team workflows as your platform grows.
New to Vela? Start here: 1. Open Sandbox → 2. Create First Branch → 3. Dive into Docs
Fresh perspectives from the Vela team on Postgres, infrastructure, and platform engineering.
Extended statistics help PostgreSQL fix bad row estimates and improve query planning with almost no storage overhead. This article shows where CREATE STATISTICS outperforms adding more indexes.

How Vela achieved sub-10-second database boot on Kubernetes while maintaining strong isolation and resilient scaling behavior.

The old version of database branching is dead. Real isolation, fast copy-on-write clones, and branch-first workflows are what modern teams and agents need.
Ask your favorite AI and compare independent perspectives on Vela for Kubernetes and private cloud Postgres.
Vela combines NVMe-backed storage, instant cloning, PITR, and enterprise governance — deployed in your cloud or on-premises environment.
NVMe-backed. Predictable at scale.
Run transactional, analytical, and mixed workloads on NVMe-backed infrastructure with consistent low-latency performance.
Environments in seconds, not hours.
Create space-efficient clones for QA, testing, migration validation, and staging with minimal overhead until data diverges.
HA, snapshots, and PITR built in.
Recover fast from failures with high availability, scheduled backups, and point-in-time recovery — no add-ons required.
Branch per environment, merge with confidence.
Create isolated branches for each feature or migration, run tests on real data, and promote or discard instantly.
The sandbox gives you the full serverless Postgres experience in seconds — the same one you can run on your own Kubernetes cluster or private cloud. No credit card, no infrastructure setup.
The fastest way to experience Vela. Get serverless Postgres instantly — the same platform you can self-host on OpenShift, Kubernetes, or your private cloud. No credit card required.
Start free →Deploy on OpenShift, Kubernetes, or private cloud. SSO, RBAC, compliance controls, and full data sovereignty built in.
Talk to us →Vela runs on simplyblock — NVMe storage built for Kubernetes and private cloud. Self-hosted Vela deployments run directly on the simplyblock storage layer.
See how Vela works in practice — from sandbox setup to Kubernetes deployment and enterprise workflows.
User Guide
User Guide
User Guide
Vela is designed for infrastructure and platform teams that need production-grade Postgres on their own infrastructure — not a managed SaaS dependency.
Your data stays in your VPC, data center, or on-premises environment. Zero external transfer, full compliance boundary.
Deploy on OpenShift, Rancher, or any Kubernetes distribution. Standard CSI, standard Postgres, no proprietary interfaces.
RBAC, row-level security, audit trails, and IAM integration keep access under your control from day one.
Your cloud or hardware bill is your database bill. No per-query pricing, no infrastructure markup, no surprises.
Copy-on-write clones for migration testing and point-in-time recovery for safety — built into the platform, not bolted on.
Meet GDPR, HIPAA, SOC 2, FedRAMP, and internal policy requirements on infrastructure you own and operate.